SIGCOMM Student Scholar
50 Years of the ACM Turing Award Celebration
I graduated in May 2018 and I am now a tenure-track faculty member at the Max Planck Institute for Software Systems in Saarbrücken, Germany!
At Brown, I was advised by Professor Rodrigo Fonseca.
My research focuses on monitoring, understanding, and enforcing distributed system behaviors. In my PhD work I adapted techniques from end-to-end request tracing to new applications in multi-tenant resource management and dynamic causal profiling. My work on Pivot Tracing introduced baggage, a concept for generic cross-system metadata now widely used by tracing systems like Zipkin and OpenTracing.
I am currently working on large-scale end-to-end performance analysis, ranging from data collection, aggregation, and storage, to deriving high-level insights using machine learning and statistical analysis. My ongoing work is a collaboration with researchers in Facebook's tracing and performance groups.
End-to-end tracing has emerged recently as a valuable tool to improve the dependability of distributed systems, by performing dynamic verification and diagnosing correctness and performance problems. Contrary to logging, end-to-end traces enable coherent sampling of the entire execution of specific requests, and this is exploited by many deployments to reduce the overhead and storage requirements of tracing. This sampling, however, is usually done uniformly at random, which dedicates a large fraction of the sampling budget to common, 'normal' executions, while missing infrequent, but sometimes important, erroneous or anomalous executions. In this paper we define the representative trace sampling problem, and present a new approach, based on clustering of execution graphs, that is able to bias the sampling of requests to maximize the diversity of execution traces stored towards infrequent patterns. In a preliminary, but encouraging work, we show how our approach chooses to persist representative and diverse executions, even when anomalous ones are very infrequent.
Recent research has proposed a variety of cross-cutting tools to help monitor and troubleshoot end-to-end behaviors in distributed systems. However, most prior tools focus on data collection and aggregation, and treat analysis as a distinct step to be performed later, offline. This restricts the applicability of such tools to only doing post-facto analysis. However, this is not a fundamental limitation. Recent research has proposed tools that integrate analysis and decision-making at runtime, to directly enforce end-to-end behaviors and adapt to events.
In this thesis I present two new applications of cross-cutting tools to previously unexplored domains: resource management, and dynamic monitoring. Retro, a cross-cutting tool for resource management, provides end-to-end performance guarantees by propagating tenant identifiers with executions, and using them to attribute resource consumption and enforce throttling decisions. Pivot Tracing, a cross-cutting tool for dynamic monitoring, dynamically monitors metrics and contextualizes them based on properties deriving from arbitrary points in an end-to-end execution.
Retro and Pivot Tracing illustrate the potential breadth of cross-cutting tools in providing visibility and control over distributed system behaviors. From this, I identify and characterize the common challenges associated with developing and deploying cross-cutting tools. This motivates the design of baggage contexts, a general-purpose context that can be shared and reused by different cross-cutting tools. Baggage contexts abstract and encapsulate components that are otherwise duplicated by most cross-cutting tools, and decouples the design of tools into separate layers that can be addressed independently by different teams of developers.
The potential impact of a common architecture for cross-cutting tools is significant. It would enable more pervasive, more useful, and more diverse cross-cutting tools, and make it easier for developers to defer development-time decisions about which tools to deploy and support.
A Universal Architecture for Cross-Cutting Tools in Distributed Systems
Many tools for analyzing distributed systems propagate contexts along the execution paths of requests, tasks, and jobs, in order to correlate events across process, component and machine boundaries. There is a wide range of existing and proposed uses for these tools, which we call cross-cutting tools, such as tracing, debugging, taint propagation, provenance, auditing, and resource management, but few of them get deployed pervasively in large systems. When they do, they are brittle, hard to evolve, and cannot coexist with each other. While they use very different context metadata, the way they propagate the information alongside execution is the same. Nevertheless, in existing tools, these aspects are deeply intertwined, causing most of these problems. In this paper, we propose a layered architecture for cross-cutting toolsthat separates concerns of system developers and tool developers, enabling independent instrumentation of systems, and the deployment and evolution of multiple such tools. At the heart of this layering is a general underlying format, baggage contexts, that enables the complete decoupling of system instrumentation for context propagation from tool logic. Baggage contexts make propagation opaque and general, while still maintaining correctness of the metadata under arbitrary concurrency and different data types. We demonstrate the practicality of the architecture with implementations in Java and Go, porting of several existing cross-cutting tools, and instrumenting existing distributed systems with all of them.
Universal Context Propagation for Distributed System Instrumentation
This paper presents Canopy, Facebook’s end-to-end performance tracing infrastructure. Canopy records causally related performance data across the end-to-end execution path of requests, including from browsers, mobile applications, and backend services. Canopy processes traces in near real-time, derives user-specified features, and outputs to performance datasets that aggregate across billions ofrequests. Using Canopy, Facebook engineers can query and analyze performance data in real-time. Canopy addresses three challenges we have encountered in scaling performance analysis: supporting the range of execution and performance models used by different components of the Facebook stack; supporting interactive ad-hoc analysis of performance data; and enabling deep customization by users, from sampling traces to extracting and visualizing features. Canopy currently records and processes over1 billion traces per day. We discuss how Canopy has evolved to apply to a wide range of scenarios, and present case studies of its use in solving various performance challenges.
Canopy: An End-to-End Performance Tracing And Analysis System
In many important cloud services, different tenants execute their requests in the thread pool of the same process, requiring fair sharing of resources. However, using fair queue schedulers to provide fairness in this context is difficult because of high execution concurrency, and because request costs are unknown and have high variance. Using fair schedulers like WFQ and WF²Q in such settings leads to bursty schedules, where large requests block small ones for long periods of time. In this paper, we propose Two-Dimensional Fair Queuing (2DFQ), which spreads requests of different costs across di erent threads and minimizes the impact of tenants with unpredictable requests. In evaluation on production workloads from Azure Storage, a large-scale cloud system at Microsoft, we show that 2DFQ reduces the burstiness of service by 1-2 orders of magnitude. On workloads where many large requests compete with small ones, 2DFQ improves 99th percentile latencies by up to 2 orders of magnitude.
2DFQ: Two-Dimensional Fair Queuing for Multi-Tenant Cloud Services
Workflow-centric tracing captures the workflow of causally-related events (e.g., work done to process a request) within and among the components of a distributed system. As distributed systems grow in scale and complexity, such tracing is becoming a critical tool for understanding distributed system behavior. Yet, there is a fundamental lack of clarity about how such infrastructures should be designed to provide maximum benefit for important management tasks, such as resource accounting and diagnosis. Without research into this important issue, there is a danger that workflow-centric tracing will not reach its full potential. To help, this paper distills the design space of workflow-centric tracing and describes key design choices that can help or hinder a tracing infrastructure’s utility for important tasks. Our design space and options for them are based on our experiences developing several previous workflow-tracing infrastructures.
Monitoring and troubleshooting distributed systems is notoriously difficult; potential problems are complex, varied, and unpredictable. The monitoring and diagnosis tools commonly used today – logs, counters, and metrics – have two important limitations: what gets recorded is defined a priori, and the information is recorded in a component- or machine-centric way, making it extremely hard to correlate events that cross these boundaries. This paper presents Pivot Tracing, a monitoring framework for distributed systems that addresses both limitations by combining dynamic instrumentation with a novel relational operator: the happened-before join. Pivot Tracing gives users, at runtime, the ability to define arbitrary metrics at one point of the system, while being able to select, filter, and group by events meaningful at other parts of the system, even when crossing component or machine boundaries. We have implemented a prototype of Pivot Tracing for Java-based systems and evaluate it on a heterogeneous Hadoop cluster comprising HDFS, HBase, MapReduce, and YARN. We show that Pivot Tracing can effectively identify a diverse range of root causes such as software bugs, misconfiguration, and limping hardware. We show that Pivot Tracing is dynamic, extensible, and enables cross-tier analysis between inter-operating applications, with low execution overhead.
Pivot Tracing: Dynamic Causal Monitoring for Distributed Systems
In distributed systems shared by multiple tenants, effective resource management is an important pre-requisite to providing quality of service guarantees. Many systems deployed today lack performance isolation and experience contention, slowdown, and even outages caused by aggressive workloads or by improperly throttled maintenance tasks such as data replication. In this work we present Retro, a resource management framework for shared distributed systems. Retro monitors per-tenant resource usage both within and across distributed systems, and exposes this information to centralized resource management policies through a high-level API. A policy can shape the resources consumed by a tenant using Retro’s control points, which enforce sharing and rate-limiting decisions. We demonstrate Retro through three policies providing bottleneck resource fairness, dominant resource fairness, and latency guarantees to high-priority tenants, and evaluate the system across five distributed systems: HBase, Yarn, MapReduce, HDFS, and Zookeeper. Our evaluation shows that Retro has low overhead, and achieves the policies’ goals, accurately detecting contended resources, throttling tenants responsible for slowdown and overload, and fairly distributing the remaining cluster capacity.
Retro: Targeted Resource Management in Multi-tenant Distributed Systems
As our systems move to more concurrent and distributed execution patterns, the tools and abstractions we have to understand, monitor, schedule, and enforce their behavior become progressively less effective or adequate. We argue that systems should be built with causal propagation of generic metadata as a first class primitive, to serve as the narrow waist upon which many debugging and troubleshooting tools could be built, in an analogy to the role of the IP layer in networking
We are Losing Track: a Case for Causal Metadata in Distributed Systems
In distributed services shared by multiple tenants, managing resource allocation is an important pre-requisite to providing dependability and quality of service guarantees. Many systems deployed today experience contention, slowdown, and even system outages due to aggressive tenants and a lack of resource management. Improperly throttled background tasks, such as data replication, can overwhelm a system; conversely, high-priority background tasks, such as heartbeats, can be subject to resource starvation. In this paper, we outline ve design principles necessary for effective and efficient resource management policies that could provide guaranteed performance, fairness, or isolation. We present Retro, a resource instrumentation framework that is guided by these principles. Retro instruments all system resources and exposes detailed, real-time statistics of pertenant resource consumption, and could serve as a base for the implementation of such policies.
Towards General-Purpose Resource Management in Shared Cloud Services
These are the application documents I used during my faculty job search in 2018. The outcome of my job search was to accept a faculty position at the Max Planck Institute for Software Systems.
This document summarizes information about end-to-end tracing for 26 companies. The information was gathered from documents shared to the Distributed Tracing Workgroup and through in-person conversations at tracing workshops.
Pivot Tracing is a monitoring framework for distributed systems that can seamlessly correlate statistics across applications, components, and machines at runtime without needing to change or redeploy system code. Users can define and install monitoring queries on-the-fly to collect arbitrary statistics from one point in the system while being able to select, filter, and group by events meaningful at other points in the system. Pivot Tracing does not correlate cross-component events using expensive global aggregations, nor does it perform offline analysis. Instead, Pivot Tracing directly correlates events as they happen by piggybacking metadata alongside requests as they execute—even across component and machine boundaries. This gives Pivot Tracing a very low runtime overhead—less than 1% for many cross-component monitoring queries.
Pivot Tracing: Dynamic Causal Monitoring for Distributed Systems
End-to-end tracing has emerged recently as a valuable tool to improve the dependability of distributed systems by performing dynamic verification and diagnosing correctness and performance problems. End-to-end traces are commonly represented as richly annotated directed acyclic graphs, with events as nodes and their causal dependencies as edges. Being able to automatically compare these graphs at scale is a key primitive for tasks such as clustering, classification, and anomaly detection. In this paper we explore recent developments in the theory of graph kernels, and investigate the feasibility of using a family of kernels based on the Weisfeiler-Lehman graph isomorphism test as an efficient and robust graph comparison primitive. We find that graph kernels provide a good formulation of the execution graph comparison problem, and present preliminary but encouraging results on their ability to distinguish high-level differences between execution graphs.
Ph.D. Candidate
Department of Computer Science
Brown University, USA
Research Intern
Facebook, New York
Research Intern
Microsoft Research, Redmond
MSc Computer Science
Brown University, USA
Software Developer
IBM UK
Mathematics & Computer Science
MMathComp, 1st Class
Oxford University, UK
50 Years of the ACM Turing Award Celebration
Pervasive Monitoring, Diagnostics, and Analytics of Distributed Systems through Dynamic Causal Tracing
Invited speaker for Pivot Tracing: Dynamic Causal Monitoring for Distributed Systems
Pivot Tracing: Dynamic Causal Monitoring for Distributed Systems, SOSP '15
Nominated by students of Brown CS138: Distributed Systems, Spring Semester
3rd Heidelberg Laureate Forum
Brown University
Oxford University, Hertford College
Interactive Hadoop Visualization

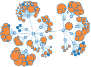

Execution Graph Comparison

Execution Graph Clustering