CS 300/1310 Spring 2024 Midterm Quiz
Welcome to our final quiz! We're hoping this quiz provides you with an opportunity to review your knowledge and what you've learned in CS 300. Our questions are designed to check your conceptual understanding, rather than asking you to memorize details.
Please make sure you read the rules below before you get started.
Rules
Read these rules carefully! In this quiz, you CANNOT interact with others, use AI tools, or access shared documents or editors. If you violate these rules, we will treat this as a matter of academic integrity and follow the process for academic code conduct violations.
The quiz is open book, open note, open computer. You may access the book and your own notes. You may also use computers or electronic devices to access your own class materials, public class materials, and online resources. Specifically:
- You may access a browser and a PDF reader.
- You may access your own notes and assignment code electronically.
- You may access the course site.
- You may access our lecture notes, exercises, and section notes.
- You may access our lecture, assignment, and section code.
- You may access online resources, including search engines, Wikipedia, and other websites.
- You may run a C or C++ compiler, including an assembler and linker.
- You may access manual pages and common utilities, including calculators and a Python interpreter.
However:
- You cannot use AI tools (like ChatGPT, Github Copilot, Google Bard, and others) during the quiz.
- You cannot contact other humans with questions about the quiz — whether in person, via IM, or by posting questions to forums — with the exception of course staff.
- You cannot interact with other humans via chat, text, phone calls, shared Google Docs, or anything like it.
- You cannot ask the quiz questions on class discussion forums or other question forums such as Stack Overflow.
- You cannot access solutions from any previous quiz, from this course or others, by paper or computer, except for those on the CS 300 course site.
Any violations of this policy are breaches of academic honesty and will be treated accordingly. Please appreciate our flexibility and behave honestly and honorably.
Additionally, students are taking the quiz at different times. Do not post publicly about the quiz until given permission to do so by course staff. This includes general comments about quiz difficulty.
Completing your quiz
You have 180 minutes to complete the quiz starting from the time you press "Start".
Different students may have different quizzes. Enter your answers directly in this form; a green checkmark appears when an answer is saved.
Students with extra time accommodations: If your extra time is not reflected next to the start button, contact course staff and wait for confirmation before pressing it.
You should not need to attach a drawing or other longer notes, but you may do
so by adding them to a final subdirectory in your cs300-s24-projects
repository. Make sure you push your changes to GitHub before time is up, and
explain in this form where we should look at your notes.
Notes
Assume a Linux operating system running on the x86-64 architecture unless otherwise stated. If you get stuck, move on to the next question. If you’re confused, explain your thinking briefly for potential partial credit.
1. Page Tables (12 points)
TAs Allison and Rahel feel like a page size of 2^12 (4096) bytes is too coarse and want to lower the page size to 2^8 (256) bytes. They do not change the virtual address size, so it remains as 8 bytes (64 bits). However, they target hardware that has at most 256 GB of RAM, so they only need an effective virtual address space of 2^38 bytes and thus leave bits 38 to 63 of the virtual address unused.
Consider the following questions based on Allison and Rahel's design.
QUESTION 1A. In Allison and Rahel's design, how many bits in the virtual address are used for the offset? Explain your reasoning.
QUESTION 1B. In Allison and Rahel's design, how many bits are used to index into the page table at each level? Explain your reasoning.
QUESTION 1C. At least how many levels of page tables do Allison and Rahel need to represent the entire address space? Explain your reasoning.
2. Fork & Pipes (11 points)
TA Ryan has written code that allows a child and parent process to communicate via two unidirectional pipes. His goal is for the parent process to greet the child process by sending a message, and then for the child to reply with a message greeting the parent.
#include <stdio.h>
#include <unistd.h>
#include <string.h>
int main() {
int parent_to_child[2];
int child_to_parent[2];
pipe(parent_to_child);
pipe(child_to_parent);
pid_t p = fork();
if (p == 0) {
// <------- POINT A
char message[24];
read(parent_to_child[0], message, sizeof(message));
printf("child received message %s\n", message);
const char* reply = "Hi parent!";
write(child_to_parent[1], reply, strlen(reply) + 1);
printf("child wrote message %s\n", reply);
// <------- POINT B
} else {
// <------- POINT C
const char* message = "Hi child!";
write(parent_to_child[1], message, strlen(message) + 1);
printf("parent wrote message %s\n", message);
char reply[24];
read(child_to_parent[0], reply, sizeof(reply));
printf("parent received message %s\n", reply);
// <------- POINT D
}
return 0;
}
QUESTION 2A. Assign the following code segments to their correct
positions within this code. You may not end up using all of segments,
and you might use each code segment more than once. However, you must
assign exactly one segment to each of the positions labeled POINT A,
POINT B, POINT C, and POINT D. Your answer should be of the
form "Point A => Segment X, Point B => ...".
- Segment 1
close(parent_to_child[1]);
close(child_to_parent[0]);
- Segment 2
close(parent_to_child[0]);
close(child_to_parent[1]);
- Segment 3
close(parent_to_child[0]);
close(child_to_parent[0]);
- Segment 4
close(parent_to_child[1]);
close(child_to_parent[1]);
QUESTION 2B. Why will this program always print the same output? Assume that the read and write calls always succeed and read/write the expected number of bytes, and that no timer interrupts occur between read/write and printing.
QUESTION 2C. TA Aijah reads online that it’s possible to make a file descriptor (FD) non-blocking by invoking the fcntl() syscall on it. This means that operations on the FD never block waiting for data or space, but instead return immediately. A read will read as many bytes as the pipe has, up to the number asked for; a write will write as many bytes as the pipe has space for, up to the number of bytes provided.
For example, Aijah could write fcntl(parent_to_child[1], F_SETFL, O_NONBLOCK); to make one end of the parent_to_child pipe non-blocking. Excitedly, Aijah makes all the pipe FDs in the program non-blocking!
Why does Aijah’s program no longer work as intended? Give an example of a problematic execution.
3. Threads (10 points)
UTAs Alex Portland and Alex Wick ("the Alexes") are working on a
program to find a prime number amongst 100,000 random numbers. They
store the numbers in an array. Alex P suggests speeding the program up
by using threads: each thread picks a number from the array and checks
if it is prime, setting global boolean found_prime to true once it finds a
prime. Each thread regularly checks the boolean to see if another
thread has found a prime. Alex W agrees, but suggests synchronizing
access to the array with a mutex to avoid race conditions.
#include <cstdlib>
#include <mutex>
#include <thread>
#define NUM_THREADS 10
std::mutex mtx;
int numbers[100000];
bool found_prime = false;
bool check_prime(int i) { ... }
void threadfunc(int start) {
int end = start + 10000;
for (int i = start; i < end; i++) {
if (found_prime) {
return; // another thread found a prime!
}
mtx.lock();
bool is_prime = check_prime(numbers[i]);
mtx.unlock();
if (is_prime) {
found_prime = true;
}
}
}
int main() {
std::thread th[NUM_THREADS];
for (int i = 0; i < 100000; i++) {
numbers[i] = rand();
}
for (int i = 0; i < NUM_THREADS; i++) {
th[i] = std::thread(threadfunc, i * 10000);
}
for (int i = 0; i < NUM_THREADS; i++) {
th[i].join();
}
}
QUESTION 3A. Alex P’s computer is old and only has a single processor. Why does the multithreaded program see no speedup?
QUESTION 3B. When Alex P runs the program, it actually runs slower than a program without threads and synchronization. Why does this happen?
QUESTION 3C. The Alexes run the program with TSAN, which reports a
race condition on found_prime. How could they resolve this race
condition without using a (new or existing) mutex? Explain your
solution and briefly justify your answer.
QUESTION 3D. Alex W suggests removing the mutex that protects access to the array, arguing that the program will work correctly without it. Is Alex W correct, or is he making a dangerous mistake? Briefly justify your answer.
4. Race Conditions, Condition Variables, and Synchronization (8 points)
Stanley and his turtles are back! Inspired by the "Tortoise and the Hare" folktale, Stanley is now also raising a pet rabbit and starting a carrot farm, as shown in the program below. His turtles are planning on using the carrots to make a carrot cake, but his peckish rabbit is trying to steal them!
As you read the program, note the following:
- Stanley and his pets all run in individual threads that refer to
the same instance of the
Farmstruct, which tracks how many carrots are available. - Stanley notifies his pets once five carrots have grown using a condition variable.
- Turtles need at least three carrots to make a carrot cake.
- The rabbit steals carrots one at a time.
#include <mutex>
#include <condition_variable>
#include <thread>
struct Farm {
std::mutex mtx;
std::condition_variable cv;
int numCarrots;
};
Farm farm; // global variable representing the farm
void Stanley() {
while (true) {
farm.mtx.lock();
assert(farm.numCarrots >= 0); // <------------ Assertion that fails (part a)
farm.numCarrots += 1; // Grow a carrot!
if (farm.numCarrots == 5) {
farm.cv.notify_all();
}
farm.mtx.unlock();
}
}
void Turtles() {
while (true) {
std::unique_lock<std::mutex> lock(farm.mtx);
while (farm.numCarrots < 3) {
farm.cv.wait(lock);
}
farm.numCarrots = 0; // Make a carrot cake! :)
}
}
void Rabbit() {
while(true) {
std::unique_lock<std::mutex> lock(farm.mtx);
if (farm.numCarrots == 0) { // <-------------- BUG HERE!
farm.cv.wait(lock);
}
farm.numCarrots -= 1; // Steal a carrot! >:)
}
}
int main(int argc, char *argv[]) {
// Start with 0 carrots
farm.numCarrots = 0;
// Run threads
std::thread turtles = std::thread(Turtles);
std::thread rabbit = std::thread(Rabbit);
std::thread stanley = std::thread(Stanley);
turtles.join();
rabbit.join();
stanley.join();
}
Unfortunately, the code for Stanley’s farm contains a bug: sometimes, the farm has a negative number of carrots! When this happens, the program fails the assert statement marked above, causing the program to exit. Stanley traces the problem to the Rabbit implementation: rather than using a while loop around the wait() call on the condition variable, Stanley used an if statement.
QUESTION 4A. Assuming there are no spurious wakeups, give an
example of an execution order of threads’ wait() and notify_all()
calls that will cause the program to crash with an assertion failure.
Answer format:
- Turtles:
num_carrots= 0, thread callswait() - Rabbit:
num_carrots= 0, thread callswait() - Stanley:
num_carrots= 0, grows carrots untilnum_carrots= 5; thread callsnotify_all() - . . .
QUESTION 4B. Why does using a while loop instead of the if
statement around farm.cv.wait() in the Rabbit’s function fix the
bug?
5. WeensyOS (8 points)
Kazuya is confused as to why WeensyOS needs a separate implementation
of process_setup and syscall_fork, since both start new
processes. He decides to simplify his WeensyOS implementation by just
calling process_setup from his syscall_fork.
To make this work, Kazuya makes three changes:
-
He picks the new process’s PID in
syscall_forkby looking for an empty slot in theprocsarray and passes it as an argument toprocess_setup. -
He ensures that
process_setupsetsregs.reg_rax = 0in the new process and returns the child process PID fromprocess_setupandsyscall_fork. -
He adds the program file path
program_nameto theprocstruct, so thatprocess_setuphas access to the parent process’s program executable in the loader, as shown below.
// Process descriptor type
struct proc {
x86_64_pagetable* pagetable; // process' page table
pid_t pid; // process ID
int state; // process state (see above)
regstate regs; // process' current registers
char* program_name // path to program process is loaded from
};
QUESTION 5A. Give two reasons why Kazuya’s approach does not faithfully
implement the semantics of fork(). For each reason, explain your answer
(about 1-2 sentences).
[You may assume that all attempts to allocate memory pages and create
page table mappings succeed (i.e., kalloc() never returns an error,
map(), and try_map() always succeed).]
6. Assembly (8 points)
Joe Schmo writes the following C++ program:
int add(int* x) {
*x += 5;
}
int main() {
int x = 0;
std::thread t1(add, &x);
std::thread t2(add, &x);
std::thread t3(add, &x);
t3.join();
t2.join();
t1.join();
return x;
}
This is the assembly of add():
movl (%rdi), %temp
addl $5, %temp
movl %temp, (%rdi)
Joe expects the threads to execute the instructions in this order:
1. t1 executes movl (%rdi), %temp
2. t1 executes addl $5, %temp
3. t1 executes movl %temp, (%rdi)
4. t2 executes movl (%rdi), %temp
5. t2 executes addl $5, %temp
6. t2 executes movl %temp, (%rdi)
7. t3 executes movl (%rdi), %temp
8. t3 executes addl $5, %temp
9. t3 executes movl %temp, (%rdi)
However, Joe has forgotten the basic rule of synchronization, so his
code contains a race condition! When he runs main(), it returns x = 5
instead of the expected answer, 15.
QUESTION 6A. Help Joe understand why this is happening! Reorder the above assembly instructions so that x = 5 when the last instruction finishes.
Format your answer as a list of instructions 1-9. For example:
1. t1 executes movl (%rdi), %temp
2. t1 executes addl $5, %temp
...
QUESTION 6B. Explain how your answer to (6A) produces x = 5. Be sure to reference specific instructions and explain what those instructions do. For example, "x = 5 because instructions #5 and #6..." (2-3 sentences).
7. Signed Numbers (8 points)
Malte writes a function called add to add two signed ints. When
demonstrating the function in class, however, it invokes undefined
behavior and sets his computer on fire!
QUESTION 7A. For each of the below examples, determine if it
invokes undefined behavior. If so, provide a brief explanation why; if
not, provide the return value for add in hexadecimal.
int add(int a, int b) {
return a + b;
}
int main() {
int res1 = add(0x7FFF’FFDC, 40); // Example 1
int res2 = add(0xFFFF’FFFA, 15); // Example 2
}
For each example, your answer should be of the form: "Yes, <reason for undefined behavior>" or "No, <value in hex>"
QUESTION 7B. To avoid invoking undefined behavior, Malte decides
to change add to take in and add two signed longs instead, as
below:
long add(long a, long b) {
return a + b;
}
int main() {
long res1 = add(0x7FFF’FFDC, 40); // example 1
long res2 = add(0xFFFF’FFFA, 15); // example 2
}
Which, if any, of your above answers would change with this new program, and why? Explain your reasoning. If any answers do change, specify the new result.
8. Privilege Separation (8 points)
UTA Bokai is doing an internship at Skint Computer, Inc., working with
their new SKINT64 processor architecture. SKINT64 is exactly the same
as the x86-64 architecture, but with exactly one change: to save
money on chip manufacturing, the CEO suggests removing the %cs
register, which represents whether the processor is executing with
full privilege or not, from the hardware. Instead, the CEO proposes
replacing the %cs register with what he calls a "privilege page".
Here’s how the CEO’s plan works:
- The "privilege page" is at physical address 0x1ee7000 and gets mapped into the virtual memory of every userspace process at virtual address 0x1ee7000. (Similar to how the console page is mapped in every WeensyOS process.)
- The first byte of the privilege page indicates the privilege level: when the byte has value 0, execution is in privileged mode (kernel) and when it has value 3, execution is in unprivileged mode (userspace).
- On interrupts and syscalls, the hardware changes the value in the privilege page to 0; on return to userspace, the kernel sets it to 3.
Note: the kernel needs to be able to write to the privilege page, and it must be readable while executing in userspace.
QUESTION 8A. Bokai argues that the CEO’s plan is fatally flawed and could let malicious userspace processes change their privilege level. What about the page table and memory protection architecture on x86-64/SKINT64 means that Bokai is correct?
QUESTION 8B. The CEO fires Bokai and comes up with a new plan. This plan still uses the privilege page and saves even more money by removing virtual memory and page tables from SKINT64 and has processes work with physical addresses directly. For security, this plan instead introduces a notion of "write segments".
SKINT64’s write segments define a region of physical memory that each
process can write to. For example, the kernel’s write segment might be
(0x1000000, 0x1fff000), while a userspace process might have a write
segment (0x2000000, 0x2fff000). The hardware prevents any writes
outside this segment by triggering an interrupt when a process tries
to write to memory addresses outside its write segment.
Since the privilege page is in the kernel’s write segment at
0x1ee7000, the kernel can write, and no other process can modify the
privilege page.
What serious security flaw does the CEO’s new plan for SKINT64 have?
9. Networking & Distributed Systems (10 points)
TAs Doren is designing a new video-sharing platform called UTube. After taking CS 300, he wants to use sharding to improve response time on client requests to his platform.
Doren has come up with a brilliant new sharding scheme called
"popularity striping"! First, he sorts the list of all videos on their
platform by the number of views. Then, he determines a target number
of shards, k. Starting with the video with the most views, he
assigns videos to shards one at a time, snaking back and forth when
they reach the end of the list of k shards. This snaking (shown by
the blue line across the shards below) ensures that each shard has a
set of videos with roughly equal total view counts.
Here is an example of sharding videos into three shards using this method:
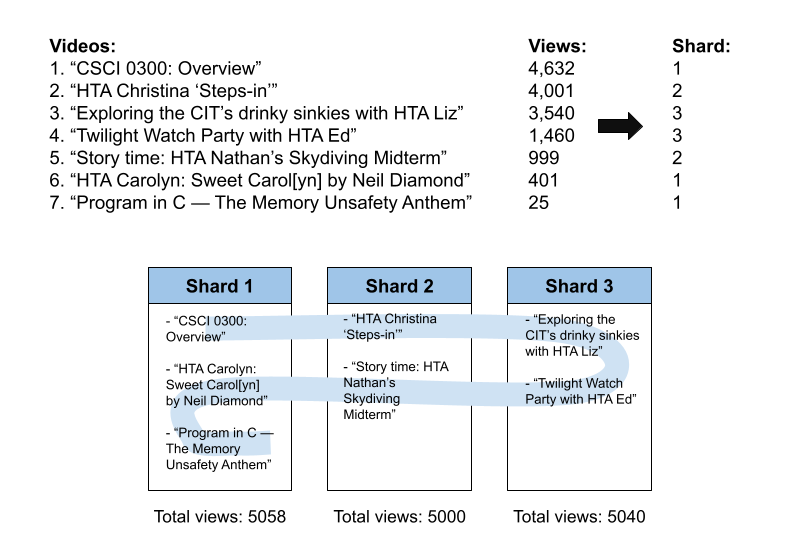
These shards then get assigned to servers by a shardcontroller, and UTube periodically re-computes the videos’ assignment to the k shards based on view counts (e.g., every minute), moving videos as necessary as their shard assignment changes.
QUESTION 9A. Explain why this sharding algorithm will make UTube’s operation highly inefficient.
[Hint: consider what happens if "Program in C — The Memory Unsafety Anthem" gets popular and racks up 6,000 views!]
QUESTION 9B. TA Sarah proposes an alternative design in which she shards videos by their unique identifiers, which are random strings like "9vXy-Qgzz3Y". A shard contains a set of videos with consecutive identifiers, such as all videos starting with "9vX" to "9vZ".
Under Sarah's sharding scheme, how could UTube handle a situation where a previously-unpopular video becomes very popular?
QUESTION 9C. Why is Sarah's sharding scheme scheme more efficient than Doren’s scheme?
10. CS 300/1310 Feedback (6 points)
QUESTION 10A. What is one aspect of CS 300/1310 that we should definitely retain for future years? Any answer but no answer will receive full credit.
QUESTION 11B. What is one aspect of CS 300/1310 (other than firing the instructors and dropping the exams) that we can improve for future years? Any answer but no answer will receive full credit.
QUESTION 11C. Which CS 300/1310 projects were your most and least favorite ones, and why? Any answer but no answer will receive full credit.
11. Submit! (1 points)
QUESTION 11A. Write "I AM DONE" in the box. (You may still continue editing other questions until the time limit expires.)
