Data Scripting
The purpose of this assignment is to get you comfortable with writing clean and correct programs quickly for basic tasks. The tasks are chosen as the kind you would encounter if you are processing data sets in a data science setting; hence the name. We strongly encourage the use of higher-order functions to improve the comprehensibility (and conciseness) of your code, but do not require it (the way we required it in Placement 4).
For this homework, you are expected to do the work entirely on your own (without help from the course staff, whom you may only consult for help with names of library functions or other essential information of that sort). Though we do expect you to be able to do all the problems in this assignment, this is not the same as saying all these problems will be straightforward: we expect you to find some challenging!
Note that some of the problems use special values like 0 or -999 to delimit content. In general, you should not do this in your own programs: use properly structured data rather than embedding the shape in the data. However, sometimes you will confront real-world data sources that do this, and you may not have the freedom to change them. These problems give you a feel for working in such settings.
1 Theme Song
lofi hip hop radio - beats to relax/study by Lofi Girl
2 Examplar
There is no Examplar support for this assignment, but we do have this starter file: Template.
Please put all the solution functions in the same file.
3 Planning
Once again, we’re going to do some planning before implementing. You’ll again use a block-based interface, but with some changes and improvements from the last time you did it. Please read (and follow) these instructions before you start programming the following problems.
4 Problems
4.1 Penguins
An American zoo requests a short-term loan of healthy Gentoo penguins from a Canadian zoo. A healthy male Gentoo penguin weighs between 11lb and 19lb (inclusive), and a healthy female weighs between 9.9lb and 18lb (inclusive).
data CanadaPenguin:
| canada-penguin(name :: String,
gender :: String,
weight-in-kg :: Number)
end
The Canadians compute which penguins are a healthy weight and send only those penguins to the American zoo. When the Americans return the penguins a month later, the Canadians find that all of the loaned penguins have gained 2lbs due to a rich American diet.
after-loan :: List<CanadaPenguin> -> List<CanadaPenguin>
We provide helper functions kg-to-lb and lb-to-kg to perform the unit conversions for you. Both consume and produce numbers.
after-loan(
[list:
canada-penguin("Eduardo", "male", 5.44),
canada-penguin("Daisy", "female", 4.31),
canada-penguin("Charles", "male", 8.16)])
is
[list:
canada-penguin("Eduardo", "male", 69976/11025),
canada-penguin("Charles", "male", 99964/11025)]
4.2 Shelf Sorting
Most bookstores sort the books on their shelves by the author’s last name. Unfortunately, some bookstore patrons do not preserve this order when browsing books, and simply place books back wherever they fit.
data Shelf:
| shelf(letter :: String,
authors :: List<String>)
end
fix-shelves :: List<Shelf> -> List<Shelf>
fix-shelves([list:
shelf("r", [list: "rivest", "sussman", "ronaldo"]),
shelf("s", [list: "sanderson"]),
shelf("t", [list: "doyle", "tucker", "talie"])])
is
[list:
shelf("r", [list: "sussman"]),
shelf("t", [list: "doyle"])]
4.3 Missing Authors
“The reader does not steal, and the thief does not read.” —
missing-authors :: List<Shelf>, List<Shelf> -> List<Shelf>
Assume that both lists of shelves have the same number of Shelf values
and that they have the same letters—
missing-authors(
[list:
shelf("r", [list: "rivest", "ronaldo"]),
shelf("s", [list: "sanderson", "sussman", "solar", "stine"]),
shelf("t", [list: "tucker", "talie", "taylor"])],
[list:
shelf("t", [list: "tucker", "talie", "taylor"]),
shelf("r", [list: "rivest", "ronaldo", "rivera"]),
shelf("s", [list: "sussman", "solar", "stine"])])
is
[list:
shelf("r", [list: ]),
shelf("s", [list: "sanderson"]),
shelf("t", [list: ])]
4.4 Data Smoothing
data PHR:
| phr(name :: String,
height :: Number,
weight :: Number,
heart-rate :: Number)
end
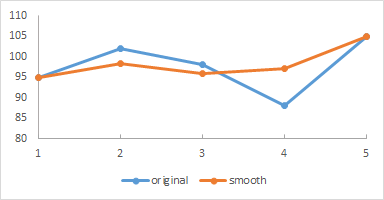
In data analysis, smoothing a data set means approximating it to capture important patterns in the data while omitting noise or other fine-scale structures and phenomena. One simple smoothing technique is to replace each internal element of a sequence of values with the average of that element and its predecessor and successor. Assuming that extreme outlier values are an aberration caused, perhaps, through poor measurement, this averaging process replaces them with a more plausible value in the context of that sequence.
For example, consider this sequence of heart-rate values taken from a list of personal health records:
95 102 98 88 105
The resulting smoothed sequence should be
95 295/3 96 97 105
102 was substituted by 295/3: (95 + 102 + 98) / 3
98 was substituted by 96: (102 + 98 + 88) / 3
88 was substituted by 97: (98 + 88 + 105) / 3
This information can be plotted in a graph such as below, with the smoothed graph superimposed over the original values.
data-smooth :: List<PHR> -> List<Number>
Example:
As given in the descriptive example above, assuming the initial sequence is instead a list of PHRs with the given values as the heart-rates.
4.5 Data Streaming
When communicating data that must be sent as a stream (a sequence of items sent one at a time), it is difficult to preserve non-linear structure. Instead, the data must be sent with special values that the recipient can recognize from which to reconstruct the original structure.
In this problem, the input is a two-dimensional table of numbers (where the rows are not necessarily the same width). The table is encoded as a list. Each row is terminated by a zero. If you find two consecutive zeros, these terminate the entire table, and any data that come after it should be ignored.
Design a program called table-sum that consumes a list of numbers representing the above kind of table, and produces a list of the sums of each row.
table-sum :: List<Number> -> List<Number>
table-sum([list: 1, 2, 0, 7, 0, 5, 4, 1, 0, 0, 6])
is [list: 3, 7, 10]
4.6 Music Sorting
data Segment:
| solo(yr :: Number)
| span(start :: Number,
stop :: Number)
end
A segment can be a singleton, representing a single year yr. The manager wants a singleton when neither x - 1 nor x + 1 is in the list. Otherwise, a segment must be a timespan, representing the (inclusive) range of contiguous years that was in the original list.
year-summary :: List<Number> -> List<Segment>
year-summary([list: 2003, 2004, 2005, 1997, 2003, 2009, 2007, 2010, 2014])
is
[list: solo(1997), span(2003, 2005), solo(2007), span(2009, 2010), solo(2014)]