Do Robots Sleep?
While writing the previous chapter, I got to thinking about concepts in computer science that connect the microscopic, bit-level world of logic gates and machine language to the macroscopic world of procedures and processes we’ve been concerned with so far. In listing concepts that might be worth mentioning, I noticed that I was moving from computer architecture, the subdiscipline of computer science concerned with the logical design of computer hardware, to operating systems, the area dealing with the software that mediates between the user and the hardware.
In compiling my list, I was also struck by how many “computerese” terms and phrases have slipped into the vernacular. Interrupt handling (responding to an unexpected event while doing something else) and multitasking(the concurrent performance of several tasks) are prime examples. The common use of these terms concerns not computers but human information processing. I don’t know what you’d call the jargon used by psychologists and cognitive scientists to describe how humans think. The word “mentalese” is already taken: the philosopher Jerry Fodor postulates that humans represent the external world in a “language of thought” that is sometimes called “mentalese.” Fodor’s mentalese is more like machine language for minds. I’m interested in the language we use to describe how we think, how our thought processes work — a metalanguage for talking about thinking.
Much of what I came up with in compiling my list had to do with how multiple computer processes (and mental processes) can operate concurrently and how we manage both computer and mental processes. Have you ever tried to write down your thoughts? It’s an interesting exercise. At first, you may find it easy to concentrate on a single thread of thought and the mechanics of writing down the words, but quickly your mind will stray and you’ll hear different thoughts competing for attention: “I don’t get the point of this exercise”, “The word ‘attention’ doesn’t look right to me”, and so on.
You may find your thoughts complicated by recursion and self-reference: “I’m thinking about my thinking about my thinking about this silly exercise.” You may imagine one part of you listening to another part, critically evaluating a stream of words issuing from some other mysterious thought generator. You may try to push some of your thoughts to the background so as not to be overwhelmed. Soon you are likely to stir up a cacophony of thoughts, whispering, nagging, suggesting, and otherwise vying to be heard. The richness and multitude of our thoughts is amazing even when we’re thinking about the most mundane of things.
Computer processes are far less exotic, but they are interesting nonetheless. And, while it’s sometimes difficult to harness your own thoughts or quiet the noise in your head when your brain is really buzzing, you can exercise precise control over the processes in your computer.
10.1 Stacks and subroutines
Before we get into juggling processes, let’s start with the simpler but related problem of what happens when one procedure calls another. The basic issue is to stop doing one thing in order to do another without losing track of whatever you need to keep in mind in order to finish the first thing. More concretely: how does C or Java or Scheme manage passing arguments to a procedure being called by another procedure, returning values produced by the called procedure to the calling procedure, and setting aside the contents of memory locations that are used in the calling procedure prior to the procedure call, that may be overwritten by the called procedure and that will be needed by the calling procedure when the called procedure returns? The trickiest part is doing all of this with a single central processing unit (CPU) that executes one instruction at a time.
The robot program in Chapter 9 written in machine language and then in assembly language was a particularly simple sort of program: it had a loop implemented with a JUMP instruction and a single conditional implemented with a BRANCH instruction. Most interesting programs involve additional structure in the form of subroutines. Programmers create subroutines for tasks that are performed often. Procedures and functions are special cases of subroutines, but typically the word “subroutine” is used to refer to blocks of reusable code at the machine- or assembly-code level. The compilers for high-level languages like C, Java and Scheme convert procedures defined in these languages into more readily executed subroutines. The code for a subroutine in a machine- or assembly-language listing, whether written by hand or generated by a compiler, looks similar to other blocks of instructions. The real difference is that the blocks of instructions corresponding to subroutines are ones that get called frequently from other blocks of instructions.
To explain how subroutines are handled, we’ll need a method for organizing computer memory called a stackor, in other contexts, a queue. The idea is that if you’re planning to go off and do something other than what you’re currently doing, then you place on the stack anything you’ll need to remember later when you resume whatever you were doing. The stack is organized so that the items associated with the last (most recently set aside) uncompleted thing you were doing are the items most readily available.
In terms of subroutines, the things you’ll want to remember correspond to the contents of registers. The CPU maintains its own stack, which is managed by two machine instructions. The PUSHinstruction puts the contents of a specified register on the top of the stack and the POPinstruction removes the top item from the stack and loads it into a specified register. Each time you POP something off the stack, it has one less item and each time you PUSH something on the stack, it has one more item. The stack is like a Pez dispenser that you can press candies into or pop them out of. We’ll refer to items on the stack as “words” corresponding to binary numbers of the size that fits into a register. Here’s what a stack and the PUSH and POP operations might look like in Scheme:
(define stack (list))
(define (push word)
(set! stack (cons word stack)))
(define (pop)
(let ((word (car stack)))
(set! stack (cdr stack)) word))
The invocation (list) returns an empty list, (cons item list) returns a new list whose first element is item and whose remaining items are the items in list, (car list) returns the first item in list, and (cdr list) returns the list consisting of all the items in list except the first. Here are some examples of how PUSH and POP work:
> (push "A") > (push "B") > (pop) "B" > (pop) "A" > (push "C") > (push "D") > (pop) "D" > (push "E") > (pop) "E" > (pop) "C"
In machine language, PUSH and POP could be implemented by using other machine instructions such as LOAD and STORE to move words to and from memory and ADD and SUB to increment and decrement the address pointing to the top word on the stack. But PUSH and POP are just so useful that it makes sense to make them separate machine instructions.
The next step is to look at a pair of machine instructions that allow the CPU to jump to a subroutine (the JSRor “jump to subroutine” instruction) and then return from it (the RTSor “return from subroutine” instruction). Each time the CPU jumps to (or calls) a subroutine, the JSR instruction pushes the program counter onto the top of the stack; when the subroutine is finished, the RTS instruction pops the top item off the stack and thereby restores the program counter to where the CPU left off before calling the subroutine.
This technique works even if you call one subroutine in the midst of executing another. You can “nest” subroutine calls as deeply as you like (one subroutine calls another subroutine that calls yet another that calls still another ...), or at least as deeply as you’ve set aside stack space in memory for the necessary register contents. The stack is also used to keep track of the values of arguments and local variables when calling subroutines, or when the operating system must perform some routine task in the midst of running a user program. Here’s how the JSR instruction might be described in an assembly-language manual. PC refers to the program counter (or next-instruction-address register) in the CPU.
INSTRUCTION NAME
JSR - Jump to SubRoutine
CALLING PATTERN
JSR address
FUNCTION
Pushes the address of the instruction immediately
following the JSR instruction onto the stack.
The PC is loaded with the supplied address (the
only argument to the JSR instruction) and program
execution continues at the address now in the PC.
And here’s the relevant information about the RTS instruction:
INSTRUCTION NAME
RTS - ReTurn from Subroutine
CALLING PATTERN
RTS
FUNCTION
Pops the word on the top of the stack and loads
it into the PC. Program execution continues at
the address now in the PC.
Like PUSH and POP, JSR and RTS can be implemented in terms of existing machine instructions, but they are so useful and so often employed that it makes sense to make them specialized instructions.
Of course, when a subroutine call crops up in your code you may be in the midst of doing some very important stuff and perhaps even have some registers full of operands on which you have yet to do some computations. You may even be in the midst of an earlier digression, executing a subroutine call that was called from some other block of code. If the registers contain important stuff, then the programmer writing the code or the compiler generating the code has to take care of it, since JSR doesn’t save the contents of any registers except the program counter. Any contents of registers that you’re going to need after the subroutine call can be pushed on the stack before the call and popped back off after it.
Imagine how the following fragments of Scheme code might be translated into machine code. The important features of this dummy procedure are, first, that it has information stored in registers that it will need when the factorial procedure returns and, second, that it calls the factorial procedure with an argument that has to be passed to the block of code implementing the factorial procedure.
Here’s the Scheme code:
(define (dummy)
(let ((r 0) (n 6))
... do some stuff ...
(set! r (factorial n))
... do more stuff ... ))
(define (factorial n)
... definition ... )
| |
| Figure 12: Assembly code for the dummy procedure | |

Figure 12 sketches the assembly code for the dummy procedure (looking at the machine code would be just too painful). The variables introduced by let are handled by setting aside locations in memory at the beginning of the DUMB subroutine. We’re assuming that the missing instructions indicated by “do some stuff” perform calculations and store intermediate results in registers 1 and 2 that will be needed when factorial (implemented by the FACT subroutine) returns and executes the missing instructions indicated by “do more stuff.” We use register 1 to pass FACT the value for its single argument and register 2 to obtain the result returned by FACT.
| |
| Figure 13: Assembly code for the factorial procedure | |

Figure 13 shows the assembly code for the factorial procedure.1 The operation of the MOVE, DECR and MULT assembly-code instructions should be clear from the comments. This implementation of FACT assumes that the value of its single argument is passed to it in register 1 and that the calling procedure knows to look in register 2 for the result. The JSR and RTS instructions implicitly handle pushing addresses on the stack, popping them back off, and assigning the program counter to the appropriate address to ensure that the CPU does the right thing at the right time.
The method of passing results and arguments (or parametersas they are called in this context) illustrated in DUMB and FACT is not considered good programming practice. It is generally easier to keep track of all the necessary bookkeeping if you use the stack to pass information to a subroutine or to return information from a subroutine call. Passing parameters and return values on the stack involves allocating space for them on the stack. As an exercise, think about how you’d modify the code in Figures 12 and 13 in order to pass parameters and values using the stack. (Hint: before executing the JSR instruction, you’ll have to allocate extra space on the stack to store the parameters and the return values; then in the subroutine you’ll have to dig below the top item on the stack both to retrieve the parameters and to store the returned values.)
If all this sounds messy and potentially error-prone, you’re right, it is. Indeed, it’s the pain of this sort of nitpicky bookkeeping that discourages many people from programming in machine and assembly language. Modern programming languages and their associated compilers manage this kind of busywork automatically. Juggling registers to orchestrate subroutine calls may seem terribly complicated, but the code for doing it is not all that difficult and once you (or the person who wrote your compiler) have written it you never have to juggle registers again. Compilers do all sorts of tedious mechanical stuff so that we don’t have to bother. In the next section we’ll see how another complicated juggling act is accomplished.
10.2 Managing tasks
In most computers, processes only appear to be running at the same time: in fact, they are running on the same processor (its CPU to be specific) by switching back and forth very quickly among the processes. I was thinking about this largely because of the robot example in the machine-language program in the previous chapter. A robot often has to perform several tasks at the same time: controlling its motors while looking for a bright light, while avoiding obstacles, while checking its batteries, and so on. How can a single CPU accomplish this juggling feat?
In operating-systems terminology, processesare relatively heavy-duty computations that function independently of one another for the most part. These heavyweight processes are powerful but generally take a fair bit of time and memory to create and maintain. There are also lightweight processes, often called threadsto distinguish them from their heavyweight counterparts, that are easier to create and maintain but don’t have so many bells and whistles.
Processes of all sorts can procreate and commit mayhem. A process can put itself to sleep for a time or it can kill itself.2 Processes can also create their own child processes, and, terrible as it sounds, a parent process can kill its children. An application such as a word-processing program is typically implemented as a single heavyweight process with several lightweight threads of control to handle such tasks as spelling and grammar checking, reading keystrokes and mouse movements, and managing text and graphics display.
The CPU can handle only one instruction per CPU cycle, and processes vie for those cycles.3 Every process is assigned a priority that determines what share if any of the CPU’s cycles it is allocated. If you’re a process with low priority, you have to wait until all processes with higher priority are done before you get your shot at the CPU. If you’re one of several processes with the same priority and no processes with a higher priority are ready to run, then you’ll get a slice of the CPU equal to that assigned to all the other processes in your cohort. Short intervals of time are doled out to each process; for example, you may be allowed to execute a few hundred or a few thousand instructions before your allotment is up. But the CPU will switch between the processes so quickly that each process will seem to have its own CPU. The part of the operating system responsible for switching between processes is called the task manager.4
Each process corresponds to a running program. Think about the machine-language program in the previous chapter. To interrupt a program corresponding to one process in order to allow the program corresponding to another process to run, what would we have to do? For a simple program like the light-seeking program in Chapter 9, we’d have to remember where we left off — the address currently in the program counter — and we’d have to remember whatever the program was working on — the current contents of the other registers. Then, the next time the program gets a chance at the CPU, we’d restore the program counter and the other registers and let the program run for another time slice.
The operating system uses a specially designated portion of memory to keep track of this information in much the same way the stack was used for implementing subroutine calls. There are a couple of differences, though. With subroutine calls, the programmer or compiler generating the code is aware of what registers besides the program counter must be saved to restore state following a subroutine call. When the operating system interrupts a running process, however, it doesn’t have the time to figure out which registers are likely to contain useful information, so it’s forced to save them all.
Another difference is that a stack organization doesn’t work in keeping track of processes. For subroutine calls, you push the relevant register information on the stack and pull it off in last-in-first-out order; this is exactly what you want for nested subroutine calls. But you can’t predict in advance exactly the order in which processes will be allocated CPU cycles, so a stack won’t work. Information on processes is stored so it can be easily retrieved using indices associated with each process. The process identifier(PID) for a given process serves as the index for that process. You can think of the memory used by the operating system to track processes as being divided into blocks, one block allocated for each process and identified by its process identifier. It should be obvious that each process needs its own separate stack to keep track of subroutine calls.
We’ll need some extra hardware to keep track of the short time intervals that the operating system doles out to processes. The processor clockserves as a metronome to beat out time for all the other hardware components, in order to synchronize the operations of the CPU and the hardware responsible for reading from and writing to memory. Even more importantly, the clock has a critical role in the digital abstractionby ensuring that the analog signals propagating through logic gates have “settled” before interpreting them as binary values.
The processor clock generates a steady stream of pulses, one pulse per clock cycle. A clock cycle differs from a CPU cycle: indeed, a CPU cycle may require a different number of clock cycles depending on the instruction being executed. If the clock pulses a billion times per second (1 gigahertz), then in order to give each process a time slice of 1 millisecond (an eternity in computer terms), we need a counter that can be set to one million at the beginning of each time slice, decremented by one on each pulse of the clock, and then signal when it reaches zero. This is relatively simple hardware to add to the CPU and most computers have several such counters.
We keep the program counter and other registers of each process not currently running in the portion of memory allocated for storing information about processes. Then we have a strategy for cycling through all of the processes. If all the processes have the same priority, then we just cycle through them. Each time the counter signals it has reached 1 million, we write out to the specially allocated block of memory the contents of the registers of the currently running process, read in the most recently stored contents of the registers for the process next in line, reset the program counter, and restart the process.
This reading out and writing in of register contents is called a context switch, a prime example of computerese that has entered the lexicon because of the cachet of computer literacy. Context switching takes time to store the registers of the current running process and restore the registers of the process chosen to run next. The CPU has to be careful not to divide time up too finely, since otherwise it will spend all its time context switching.
The most glaring gap in this explanation involves this “we” I keep referring to. The only entity capable of doing anything inside the computer is the CPU. But the CPU has its hands full executing instructions, a billion or more per second. If we’re going to handle multitasking, we’ll need some additional hardware to help orchestrate this switching between processes.
We’ll need circuitry to implement the counter and a gate that signals when the counter reaches zero. We can add primitive instructions to the computer’s machine language to start the timer and specify how many clock cycles it should count off. Then we’d also arrange for circuitry that, whenever the timer reaches zero, resets the program counter to the address of a special program — the program that handles switching between processes. Aside from what it actually does, this program really isn’t all that special; it looks pretty much like any other subroutine written in machine code. This program takes care of writing out the contents of the registers used by the current process, choosing what process to run next, reading in the most recently stored contents for the process chosen to run, and resetting the program counter to give the chosen process its chance to run. And that’s pretty much it; that’s how multitaskingis implemented on most computers.
The mechanism whereby the CPU is interrupted by the clock and made to execute a special program is actually quite common. It’s called an interrupt— the general technical term for stopping the CPU and redirecting the flow of control. There are many types of interrupts and interrupt handlers (the pieces of code run when a particular type of interrupt occurs). Interrupts are used to signal the CPU when some event occurs outside of the computer — a robot’s bump sensor is hit, a key on a keyboard is pressed, another computer wants to communicate, or a relatively slow peripheral like a disk drive deposits data in memory. Interrupts are also used to handle unexpected internal events (often called exceptions), such as when a program contains gibberish (something other than an instruction that the CPU understands) or tries to write into some forbidden part of memory (in most modern computers, memory is partitioned and protected by the operating system so that a poorly written or malicious program can’t overwrite those parts of the operating system required to keep things running smoothly).
10.3 Multithreaded robots
Let’s take a somewhat more detailed look at multitasking and lightweight threadsin robotics. Chapter 9 featured a simple program to make a little robot seek and drive toward a light. Now we’d like to modify that program so that the robot isn’t so single-minded (or single-threaded in this case). Specifically, we’d like the robot to watch out for collisions by detecting when its front bumper switch is depressed by contact with a wall or someone’s foot. This requires the robot to do two things at once, like walking and chewing gum at the same time. We’re going to consider two different methods for managing this feat, but we’ll start with a little more background on the Cprogramming language.
Every C program must have a function called mainthat is called when the program is started. The main function is run in a separate process from the one in which it is invoked, and any child processes it spawns are its children. The execifunction5 (defined as part of an open-source operating system for the RCXmicrocomputer that comes with the Lego MindstormsRobotics Invention System), creates a new process (a lightweight thread) in which it calls the function that appears as its first argument. execi returns a reference for the process (think of it as the PID for that process) that the parent process can use to kill the process when it’s done what it was created for. As usual, squint at the rest of the syntax and ignore the details. The seek_light function is exactly as we described it in Chapter 9 except that its formal parameters and return type have been changed to meet the requirements of the execi function.
In this first implementationthat combines seeking light and watching for collisions, the main function works by controlling a thread to seek light, killing it off when a collision is detected and it’s time for evasive action and creating it anew when the danger is past:6
int main(int argc, char *argv[]) {
/* declare a variable of type process identifer */
pid_t seeker_thread ;
/* start the light-seeking thread */
seeker_thread = execi( &seek_light, 0, 0, ... );
/* loop forever watching for a collision */
while (1) {
if ( front_bumper > 1 ) {
/* if you detect a collision then kill the seeker */
kill(seeker_thread);
/* take some appropriate evasive action */
take_evasive_action() ;
/* and then resume seeking the light */
seeker_thread = execi( &seek_light, 0, 0, ... );
}
/* otherwise put the parent thread to sleep
and and let the seeker do its thing */
else sleep(1) ;
}
}
This is the first code fragment long enough that I thought in-line commentary would help supplement the surrounding text. In documenting large blocks of code, good programmers sprinkle around pieces of prose to explain what the code does and how it is to be used. The prose can precede or follow a code fragment for a procedure or it can be interspersed with the statements comprising a procedure definition. These bits and pieces of prose are called commentsand the process of annotating code with comments is referred to as commenting or documentinga program. Since the file containing a program is read by various other programs such as compilers and interpreters, we need some way of distinguishing code from comments. Almost all programming languages have syntactic conventions for indicating comments. In both C and Java, any text between an opening /* and a closing */ is treated as a comment and is ignored by the compiler.
Most of the time, main just sleeps, waking up from time to time to check on the front bumper. I haven’t bothered to define the take_evasive_action function — let’s assume it just backs up a random distance, turns a random angle and then sets off in a new direction (performing random actions is quite useful in programming robots).
Here is the seek_light function we saw in Chapter 9 modified to accept the arguments and return the type required by the execi function:
int seek_light(int argc, char *argv[]) {
int on = 100 ;
int off = 0 ;
while (1) {
if (left_sensor > right_sensor) {
right_motor = on ;
left_motor = off ;
}
else {
right_motor = off ;
left_motor = on ; }
}
}
This implementation works well enough, but creating and destroying processes with such abandon seems somewhat inelegant. In the second implementation, we’re going to have the main function spawn two processes, one that seeks light and a second that watches for collisions. But now we have a problem: both the light-seeking and the collision-detection threads want to control the motors (collision detection indirectly by calling take_evasive_action when it senses that the switch attached to the front bumper has been depressed). This is actually quite a common situation in programming: it occurs whenever you have a resource — whether a portion of protected memory or a peripheral device — that only one program at a time can use. Resolving the problem requires some means for asynchronous communicating processes(see Chapter 2) to communicate and coordinate with one another.
To illustrate the problem and one possible solution, we’ll turn to a classic example of what can go wrong when independent processes try to use a critical resource at the same time. Whenever you use an automated teller machine (ATM) to make a cash withdrawal, it checks on your current balance and debits your account by the amount of the withdrawal before giving you the cash. Suppose the ATM machine runs this code to perform the checks and debits:
if (withdrawal < balance) {
balance = balance - withdrawal ;
issue_cash(withdrawal) ;
}
Now imagine that you and a confederate each go to separate ATMs and, at exactly the same time, make withdrawals to the tune of $90; let’s say your current balance is $100. What if the bank processed the statements for the two threads corresponding to the two separate transactions as follows?
ATM 1: (withdrawal < balance) => 90 < 100 ATM 2: (withdrawal < balance) => 90 < 100 ATM 1: balance = balance - withdrawal => balance = 10 ATM 2: balance = balance - withdrawal => balance = -80
Voilà, each of you gets $90 in cash. Now, you can’t carry out this particular bit of petty larceny because the program that processes transactions wraps the problematic code fragment in a pair of statements: the first requests exclusive control over the location in memory where your balance is stored and the second relinquishes control after the code fragment has conducted its business. If ATM 1 executes its code fragment first, then ATM 2 will find its request denied and will be forced to sleep until ATM 1 has completed its business, at which point ATM 2 will be awakened and allowed to finish. Of course, in this scenario, whichever one of you is at ATM 2 will be disappointed. We’ll illustrate this technique for coordinating processes in next version of main by using a global value so that the two threads vying for control of the motors can communicate with each other.
The next version of main starts two threads, one for seeking light and one for detecting collisions. These two threads then run independently. We could just put main in an infinite loop, but this would take up CPU cycles; instead, we put it to sleep for however long we want the robot to seek light and avoid obstacles and then kill off the threads when the time is up and we want to terminate the program. I’ve rewritten seek_light and put the bump-detection code in a separate function called avoid_bumps. The functions seek_light and avoid_bumps communicate through the global variable evasive_action_in_progress; in particular, seek_light goes to sleep if it sees that evasive_action_in_progress is 1.
int main(int argc, char *argv[])
{
pid_t seeker_thread, bumper_thread ;
/* start light-seeking and collision-detecting */
seeker_thread = execi( &seek_light, 0, 0, ... );
bumper_thread = execi( &avoid_bumps, 0, 0, ...)
/* then go to sleep for a couple of minutes */
sleep(120);
/* finally kill the two threads and halt */
kill ( seeker_thread );
kill ( bumper_thread );
return 0;
}
Here we declare the global variable evasive_action_in_progress that will coordinate seek_light and avoid_bumps:
int evasive_action_in_progress = 0 ;
Notice how the seek_light function now avoids conflicting with the take_evasive_action function:
int seek_light(int argc, char *argv[]) {
int on = 100 ;
int off = 0 ;
while (1) {
/* if evasive action is in progress, sleep */
if ( evasive_action_in_progress == 1 )
sleep(1) ;
/* otherwise seek the light */
else if ( left_sensor > right_sensor ) {
right_motor = on ;
left_motor = off ;
}
else {
right_motor = off ;
left_motor = on ; }
}
}
The function avoid_bumps signals seek_light using the the global variable evasive_action_in_progress:
int avoid_bumps(int argc, char *argv[]) {
while (1) {
if (front_bumper == 1) {
/* if you detect a collision, take over the motors */
evasive_action_in_progress = 1
/* make whatever evasive action seems appropriate */
take_evasive_action() ;
/* and then relinquish control of the motors */
evasive_action_in_progress = 0
}
/* otherwise sleep and let the seeker do its thing */
else sleep(1) ;
}
}
This implementation has a bug that is not likely to cause major problems for our robot but is worth pointing out since in other contexts (such as our ATM example) it could be more serious. I’m assuming that the function take_evasive_action takes some time to run, perhaps a couple of seconds actually to negotiate its evasive maneuvers. It’s possible that seek_light could modify the motor control parameters, left_motor and right_motor, after take_evasive_action is called. To see this, think about how the variable evasive_action_in_progress is checked (==) in the seek_light function and set (=) in the avoid_bumps function, and imagine the operating system interleaving the instructions for these two functions as it switches back and forth between the two processes running them.
The C-language semaphorelibrary makes it much easier to coordinate access to critical resources required by multiple processes. The semaphores implemented in the C library manage access to resources so that even if several processes request access to a resource at the “same time”, only one process is granted access and the others have to wait their turn. After using the shared resource, a process then releases its access and the routines in the semaphore library ensure that all other processes waiting for access get their turn.
There are all sorts of clever solutions to this simple robot problem that involve multiple threads of control, semaphores, interrupt handling, and the ability to make threads go to sleep or alter their priority. Solutions involving lots of threads can be pretty complicated, especially when they’re running on tiny little computers with slow clocks and little memory. The RCX microcomputer that comes with the Lego Mindstorms Robot Invention System is based on the Hitachi H8 family of microcontrollers, which have a top clock speed of 16 megahertz(that’s 16 million cycles per second). The RCX comes with 32 kilobytes of memory. Compare this with modern PCs that typically have processors rated at 1 gigahertz or more and come with 256 megabytes or more. If you have a slow processor running lots of processes, you’ll probably find some of your processes starved for CPU cycles. In general, programs that involve lots of threads can be tricky to manage.
We’re already seeing educational and entertainment robots on the market with much faster CPUs and lots more memory; however, there is a tradeoff. It might seem that that you can never have too much memory or too fast a processor. Unfortunately, fast clocks and large memories are expensive both in cost and in the power they require. Even a little Lego robot can wear down its batteries in a matter of minutes if it’s running its motors a lot or using its infrared port to communicate with another robot. Some of these robot-implementation problems may seem merely temporary inconveniences; after all, you may say, processors will get faster, batteries will last longer and everything will get cheaper. However, this rosy picture of the future is cold comfort when you’re trying to get a robot to do something today. And it’s my guess that our aspirations to build better robot programs will continue to outpace hardware technology for some time to come.
10.4 Allocating resources
In Chapter 2 we introduced the command ps(for “process status”) that lets us inspect running processes. Now that we know a little more about how processes are handled by the operating system, we’re going to use ps to look at some more interesting processes in terms of allocating system resources. In Chapter 2 we created two processes by running this shell script:
% sleep 10 | sleep 20 & [1] 1453 1454
|
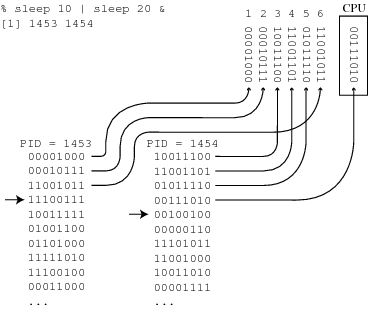
Figure 14 shows what’s going on in the hardware. Each process is associated with a process identifier, 1453 and 1454 in this case, and with a portion of memory used to keep track of the process and, in particular, the instructions that comprise the associated program. This portion of memory also maintains a pointer to the next instruction to be executed in running the program. The CPU runs a few instructions from the first process, a few instructions from the second process, back to the first process and so on. The pointer to the next instruction associated with each process identifier makes sure that the CPU won’t lose track of where it is in executing each program.
Figure 14 is a little misleading in that the “next” instruction is defined by the running program; executing instructions like JUMP and JSR cause the next instruction to jump around in memory. The situation is made more complicated (and more interesting) by the fact that generally a lot of processes need to be run and some of those processes are the very ones that decide which processes to run and when. The entire operating system that is responsible for creating and managing processes is itself just a bunch of programs running as separate asynchronous communicating processes.
The sleep command is not terribly interesting, since the operating system has a simple expedient for handling processes that wish to pause in their execution for a period of time. When the operating system encounters a sleep command, it sets an alarm clock for the required sleep interval, puts the sleeping process aside, and then forgets about it until the alarm goes off, at which point it throws the process back in with the rest of the processes waiting for a chance at the CPU. If we really want to tax the CPU, we’ll need to give it a task involving significant computation.
One relatively easy way to get the CPU to work hard is to make it perform a strenuous numerical calculation. The basic calculator command bccomes as standard equipment with many shells and is very handy for numerical calculations. bc has its own special-purpose programming language with a syntax that makes it particularly accessible to C programmers. I’m going to write a little bc program to calculate the sum of the first million integers (∑i=1106i) and I’ll store the program in a shell variable:
% set p = "r = 0 ; for ( i = 1 ; i < 10^6 ; ++i ) r += i"
There are more efficient methods7 of computing 1 + 2 + ... + n. In particular, it can be done almost trivially using the equivalence ∑i=1ni = (n2 + n)/2. However, right now we’re trying to make bc do more work, not less, in order to demonstrate how the operating system allocates resources to processes. Even so, it will take bc only a few seconds to do this calculation, just barely enough time for me to invoke the ps command to get some idea what the CPU is doing and how the operating system is allocating resources to different processes.
% echo "$p" | bc & [1] 1981 1982 % ps -o "pid %cpu command" PID %CPU COMMAND 893 0.0 -bin/tcsh 1982 98.1 bc
I used echo to pipe the program to bc and then, as quickly as I could manage, I asked ps to display, for each process, its process identifier (PID), the percentage of time (averaged over some small interval) that the CPU is dedicated to the process (%CPU) and the name of the command associated with the process (COMMAND). echo $p did its business so quickly it didn’t even appear in the list of processes. Obviously the CPU on my laptop doesn’t have a lot of work to do, given that it’s dedicating over 98% of its effort to executing the bc program (and negligible effort to running the shell I’m working in).
Now watch what happens when we get a couple of processes competing for the CPU:
% echo "$p" | bc | echo "$p" | bc & [6] 1985 1986 1987 1988 % ps -o "pid %cpu command" PID %CPU COMMAND 893 0.0 -bin/tcsh 1986 56.8 bc 1988 35.6 bc
Again, by the time I typed typed the process status command, the two echo processes 1985 and 1987 had already completed. As expected, the two bc processes are occupying most of the CPU’s time, with the rest allocated to processes associated with the operating system. If we check a few seconds later, the picture has changed somewhat as the operating system tries to balance the work load to be fair to all processes:
% ps -o "pid %cpu command" PID %CPU COMMAND 893 0.0 -bin/tcsh 1986 37.6 bc 1988 51.6 bc
Operating systems have to allocate not only time, as determined by the CPU percentage a process is allowed to use, but also space, as determined by the amount of memory a process is allowed to use. Memory is complicated in modern computers, but most people have heard of two types: magnetic or optical disk storage and RAM. Disk storage is measured in the tens or hundreds of gigabytes while most people count themselves as very fortunate if they have more than one gigabyte of RAM. RAM can be quickly read from or written to, and programs and data have to be in RAM for the CPU to use them. RAM is typically the scarce resource when dealing with computations that require a great deal of space.
Now you might have heard about virtual memory, a feature of most modern operating systems that lets you run programs requiring more memory than you have RAM. Virtual memory accomplishes this by using disk storage to simulate a larger RAM memory. If you need to run a program that requires say twice as much memory as you have RAM, you store half of the program and its associated data in RAM and the other half on disk. As long as the CPU is operating on the part that’s in RAM, you’re in business. If, however, the CPU needs to access the part of the program that’s on disk, the operating system has to transfer the part of the program currently in RAM onto the disk before transferring the part of the program that is currently on disk to RAM. There are all sorts of clever ways to make this happen fast, but compared to how fast the CPU can execute instructions that are in RAM, transferring programs and data to and from disk is glacially slow.
All this preliminary discussion is meant to impress on you that memory (and RAM in particular) is a scarce resource, one that the operating system will take pains to allocate carefully. When you start a process, the operating system allocates to it whatever virtual memory it needs; it also allocates an initial portion of RAM to the process. As the process runs, the operating system can choose to allocate it more or less RAM. A process can also request additional virtual memory if it needs more space for its computations.
When you open a large document in a word-processing program, the process in which the word processor is running asks the operating system for more virtual memory to store the document; the process requesting memory will always be granted its request (within reason) but that doesn’t mean the process is allocated more RAM. If you’re not given enough memory to store your entire document in RAM, then you’re likely to experience a delay when you run the spell checker on the entire document or rapidly scan through all its pages. (This characterization of memory management is somewhat cartoonish, especially as concerns word-processing programs, but it conveys the basic idea without bogging us down in hairy details.)
Numerical calculations can be memory hogs. The memory requirements for numerical calculations can quickly grow from a small initial requirement to many times the available RAM. In order to demonstrate the operating system allocating more memory to a process, we’ll need a process that uses significant memory. Here I create another make-work task for bc by asking it to build a list (technically it’s called an arraybut you can think of it as a list) consisting of 216 - 1 items such that the ith item in the list is the number ii:
% set p = "for ( i = 1 ; i < 2^16 ; ++i ) a[i] = i^i"
I chose 216 - 1 because that is the maximum array size allowed by the version of bc on my laptop. 216 - 1 = 65535 is not terribly large for an array; however, the numbers I’m storing in this array are large; they start off small and then quickly, very quickly, become quite large. To illustrate, we can ask bc to tell us how large some of the numbers are. The length function in bc computes the number of significant digits required to represent a given number, giving us a measure of the space required by the computation. bc first computes the number corresponding to, say, (212)(212) and then applies length to determine the number of significant digits required to represent the number. For example, given (23)(23) = 16777216, length((2^3)^(2^3)) returns 8.
% echo "length((2^12)^(2^12))" | bc 14797 % echo "length((2^13)^(2^13))" | bc 32059 % echo "length((2^14)^(2^14))" | bc 69050 % echo "length((2^15)^(2^15))" | bc 147963 % echo "length((2^16)^(2^16))" | bc 315653
So by the time our little program is only part way through filling in the array, it’s storing some pretty large numbers and bc needs a fair bit of memory to store the array and its contents. I’ll set bc to running our program.
% echo "$p" | bc & [1] 1995 1996
I’m going to check on process 1996 periodically by using ps to display status information for just this process. In addition to looking at the percentage of the CPU (%CPU) as we did earlier, I’ve also told ps to display the percentage of the total memory (averaged over some small interval of time) that the operating system has allocated to 1996 (%MEM) and the total accumulated CPU usage (TIME):
% ps 1996 -o "pid %cpu %mem time command" PID %CPU %MEM TIME COMMAND 1996 90.4 0.2 0:08.68 bc
As time passes, the average memory allocation is increasing:
% ps 1996 -o "pid %cpu %mem time command" PID %CPU %MEM TIME COMMAND 1996 95.5 0.6 1:04.41 bc
And over time, the memory allocated to this process increases to more than 6% of the total RAM:
PID %CPU %MEM TIME COMMAND 1996 92.9 1.0 2:21.00 bc 1996 85.6 1.9 6:25.40 bc 1996 80.2 4.2 22:25.26 bc 1996 69.6 5.1 29:05.34 bc 1996 87.7 6.4 40:21.44 bc
You might experiment with creating processes and using ps to explore how your operating system responds to various resource requests. See how much memory you can tie up with calculations running in several processes. In these experiments, you’re seeing the operating system in action, adapting to the needs of the processes it’s responsible for managing. Its adjustments in allocating CPU time and memory constitute a primitive sort of homeostatic system designed to maintain system parameters within allowable limits, much as your body constantly makes adjustments to maintain your internal temperature within a range you can tolerate. As additional processes are created and require increasing amounts of memory, the operating system reallocates its resources so as to run those processes while not sacrificing essential services.
This image of a modern operating system as an animated, self-regulating organism is not too wide of the mark. Indeed, computer scientists are designing self-healing systems that detect and repair problematic software and virus-detection schemes that mimic the human immune system. There are even efforts afoot to build virus-resistant computer systems by simulating evolution and natural selection to create the software equivalent of antibodies. Given the rise of malicious viruses in computer networks, it may not be long before we regularly experience days when our computers are “under the weather” or “recovering from a bout of whatever is going around.”
10.5 Metaphorically speaking
The stack of threads in my head is not like the stack of threads the operating system on the computer in front of me uses to support multitasking. My computer will never lose track of a thread (at least assuming the operating system doesn’t crash), and eventually even the lowest-priority thread will rise to the top of the heap and be executed. Not so with me. I can sense threads in my head becoming thinner, more tenuous, less emphatic. There is a rough analog in computer systems; a piece of code can “time out” and terminate or “kill” its respective thread of control. But the analogy is very rough, given that my ideas can lie dormant or below the threshold of conscious thought for long periods of time, and they appear to continually evolve and feed off other thoughts.
We pride ourselves on our ability to handle interrupts and switch contexts smoothly. We prioritize everything we have to do and we coordinate and synchronize our activities to try to perform at peak efficiency. And sometimes these attempts to optimize our behavior produce pathological behavior. Imagine the mental equivalents of these computer pathologies: “crosstalk” when two signals destructively interfere with one another, “thrashing” when a CPU has so many processes to run that it spends all of its time context switching (this generally happens when there is limited memory and part of context switching involves moving programs and data from disk to RAM and back again), “deadlock” when two processes find themselves stuck each waiting for something that the other one has, and “segmentation fault” (or “segfault”) when a program crashes as a result of trying to write or read in a protected part of memory.
I don’t think that my brain operates anything like a modern computer, but I do think that the notions of processes and threads, multitasking and thrashing, deadlocking and segfaulting have some metaphorical value in analyzing human thinking. In Faster: The Acceleration of Just About Everything, James Gleick99 talks about how such notions have influenced how we think about time. If you’re interested in models of the mind with a computational flavor, you may enjoy the writings of Marvin Minsky87, Allen Newell90 and Daniel Dennett98. And we’ll return to some related issues in the philosophy of mind in Chapter 16. David Lodge’s novel Thinks and Richard Powers’ Galatea 2.2 provide interesting insights into the relationship between human and computer processes. (By the way, the title of this chapter, “Do Robots Sleep?,” was inspired by Philip K. Dick’s “Do Androids Dream of Electric Sheep?” adapted for the movies by Ridley Scott as “Blade Runner.”) To learn more about modern operating systems, I recommend the text by Silberschatz, Galvin and Gagne as a good solid introduction.
1 This listing simplifies how Scheme handles multiplication. Also, while the FACT subroutine is defined iteratively, the Scheme definition could have been recursive. Conversely, an iterative version of the factorial function in C could end up being compiled into a recursive assembly-code implementation.
2 If you’re running a shell in a window, you can use ps to identify the PID (process identifier) of the process in which the shell is running. You can then kill this process by typing kill -KILL pid, substituting the PID you identified for pid. Needless to say, don’t try this unless you’re sure that you won’t lose any work by killing your shell process. When you kill a process you also kill its children, so keep this in mind if your text editor has an open file running in a child process of your shell process.
3 Actually this isn’t generally true: many modern computers have multiple arithmetic and logic units (ALUs) and special circuitry that lets them carry out multiple instructions at the same time. But even so there are generally many more things to be done than there are things to do them on.
4 The strategy for scheduling processes described here is based strictly on priority. Most modern operating systems use a “throughput-scheduling” strategy in which high-priority processes get a larger fraction of CPU time than low-priority processes but all processes receive some allocation of CPU time on any sequence through all processes.
5 The execi function is a convenient means of spawning new processes. It bears only a distant relationship to the exec family of routines in Unix for managing processes. The operating system that contains execi, called brickOS(based on Markus Noga’s legOS), is described in several online tutorials as well as Baumetal00’s Extreme Mindstorms: An Advanced Guide to Lego Mindstorms.
6 The ellipsis indicated by the ... in the code for creating the light-seeking thread refers to two additional arguments to execi that seem even more distracting than usual. These arguments determine the priority of the newly created thread and the size of the stack allocated to keep track of the subroutine calls invoked while running this thread. In a full specification, unless the programmer is getting really fancy, these arguments are typically assigned to default values provided by the system. For example, the complete call to execi might look something like execi(&seek_light, 0, 0, PRIORITY_NORMAL, DEFAULT_STACK_SIZE).
7 The example bc program also requires bc to compute 106 every time it evaluates the test, i < 10^6, in the for loop. An alert programmer would correct this inefficiency by assigning a variable to 106 outside the loop, say m = 10^6, and then using it in the test, say i < m.