You’ve Got (Junk) Email
The first computers were used primarily to manage information for large companies and perform numerical calculations for the military. Only a few visionaries saw computing as something for everyone or imagined it could become a basic service like the telephone or electric power. This failure of imagination was due in large part to the fact that the people who controlled computing in the early years weren’t the ones actually programming computers. If you worked for a large corporation or industrial laboratory, then you might have strictly limited access to a computer, but otherwise you were pretty much out of luck.
In the early years of computing, users submitted their programs to computer operators to be run in batches. You would hand the operator a stack of cards or a roll of paper tape punched full of holes that encoded your program. An operator would schedule your program to be run (possibly in the middle of the night) with a batch of other programs and at some point thereafter you would be handed a printout of the output generated by your program. You didn’t interact directly with the computer and if your program crashed and produced no output, you’d have very little idea what had gone wrong.
The people who ran computer facilities were horrified at the idea of having users interact directly with their precious computers. Computers were treated like sacred oracles and the computer operators were the acolytes and high priests who interceded on behalf of the unworthy programmers. But before long the users rebelled against the establishment and demanded access to computers. Indeed, once programmers got a chance to interact with computers they wanted unlimited direct access.
Computers were still very expensive in the 1950s and so the earliest efforts to make computers accessible involved doling out little slices of time to multiple users sitting at consoles connected up to one big computer, technology called time-sharing. Users on time-sharing systems quickly realized that they were connected not only to the computer but to one another. They found that the computer made it very easy to exchange messages with other users, and before long someone had written the first emailprogram.1
In the 1960s, the circle of users able to exchange email was still limited to those sharing a particular machine. The 1970s saw the creation of the first continent-spanning computer network and the advent of the personal computer. Led by an eclectic group of visionaries who saw computing as a means of communication and computing devices as a way to augment intelligence, forward-thinking computer scientists were soon visualizing online interactive communities, teleconferencing, computer-aided meetings and electronic documents enhanced with multiple fonts, graphics and hyperlinks.
Email is often called the “killer application” for the Internet, the application that made it obvious that the Internet was here to stay. But it didn’t take long for people to see the dark side of email: unsolicited, unwanted and even downright offensive junk email. It’s inevitable that a technology for communicating will soon be used for advertising, filibustering, insulting, swindling, proselytizing and every other possible form of human discourse, good or bad.
The combination of computers and communication, however, poses some particularly insidious problems. It’s almost as easy to send email to millions of people as to one person. You can even customize a message to thousands of recipients by using simple scripts that insert the recipient’s name, address and other personal information, making it appear to come from a friend or business associate.
It takes me just a few seconds each time I read my email to scan the new messages and delete the junk. If you read your email often you hardly notice it. However, if you’re away for a few days, you can return to hundreds of email messages, most of them junk. It’s annoying to have to filter the deluge, separating the messages you want to read from the advertisements, solicitations and other unwanted and often virus-ridden junk email.
But if you can use computers to automate sending email, you can also use them to automate filtering email. Early advocates of computer-mediated communication anticipated that the new technology would create problems for users unable to cope with huge volumes of information and limited by the relatively slow pace of human thought, and they imagined automated surrogates that would protect us and act on our behalf. Today, such surrogates, sometimes called agentsor bots(a shortening of “robot” or “knowbot” indicating a disembodied software- or knowledge-based robot), are cropping up in all sorts of applications. There are “auction bots” that issue thousands of bids per second in online auctions and “avatars” that provide a computer-enhanced presence for participants in online games and virtual reality environments. The technology driving these agents comes from a variety of disciplines including artificial intelligence.
8.1 Artificial intelligence
According to John McCarthy, who is generally said to have coined the name, artificial intelligence(AI) is “the science and engineering of making intelligent machines, especially intelligent computer programs.” Responding to the obvious next question, McCarthy goes on to say, “it is related to the similar task of using computers to understand human intelligence, but AI does not have to confine itself to methods that are biologically observable.” The above characterization leads immediately to the question, “What is intelligence?” and McCarthy admits it has no agreed-upon definition. However, many of us think it reasonable to adopt the stance that we’ll recognize intelligence when we see it.
Actually, this stance is complicated by the phenomenon that to many people, as soon as a computer can perform a given task, such as playing chess, that task no longer seems intelligent, or at least intelligent in an interesting way. Many AI researchers prefer to steer clear of this sort of hair-splitting and focus their attention on developing programs that analyze data, make decisions, learn from their mistakes and adapt to a changing environment. Now more than ever, the interesting applications of computer science seem to require such capabilities.
Some of the topics studied in artificial intelligence are rather esoteric and (I gather from experience in broaching them in polite conversation) somewhat dry and academic. Learning or rather machine learningis, however, a good topic for party conversations as long as you don’t delve into the theory or get too wrapped up in the philosophical implications. Machine learning is about getting machines to acquire skills, adapt to change and, generally speaking, improve their performance on the basis of experience. Effective machine-learning techniques are already used in a wide range of applications from detecting credit-card fraud to making your car run better.
One of the most thoroughly studied areas of machine learning is supervised learning, in which the program doing the learning is given a set of clearly marked training examples. Suppose you’re a scientist trying to understand the migration habits of fish and suppose you need to be able to distinguish arctic char from atlantic salmon. The first thing you’d do is observe these fish carefully and probably add various descriptive terms to your vocabulary to capture the differences in coloring, scales, fins and other characteristics useful for making distinctions.
Since initially you can’t distinguish between the two kinds of fish, you need an expert to provide a set of training examples: fish clearly marked as char or salmon. You’d probably figure out pretty quickly that some characteristics are shared by both kinds of fish, others are not terribly useful or may even be misleading in trying to make distinctions, but some, called diagnostic characteristics, are perfectly suited to distinguishing one type of fish from the other. After a while, you’ll learn to ignore the misleading or useless characteristics and become skilled at using the diagnostic ones.
If you started distinguishing arctic char with orange-red bellies from arctic char with predominantly silver bellies, you’d be wasting your time if what you wanted was to distinguish salmon from char. Humans are good at seeking out diagnostic characteristics for making all sorts of distinctions and we seldom waste time making distinctions that serve no useful purpose. If we find a particularly useful characteristic, such as the different ways in which the lower jaws of the two fish protrude, we often abandon the other characteristics and seize on the particularly diagnostic one. Machine learning is all about turning this process of looking at data and searching for diagnostic characteristics into algorithms that can be used to automate learning.
One common application of machine learning nowadays is distinguishing junk email, or spamas it’s often called, from non-spam, or ham(for “human acceptable mail”) as we’ll refer to it here.2 The various approaches to building spam filters, as they have come to be called, all have in common looking at a lot of email messages and learning to separate the spam from the ham. In some approaches the learning is done by humans painstakingly analyzing data and in other cases it is done by computers.
Learning to filter spam is an example of supervised learning not unlike distinguishing arctic char from atlantic salmon. Our scientist learning to distinguish different types of fish needs an expert to provide training examples that clearly distinguish char from salmon. In filtering spam, the user can provide the training examples. Since each user’s notion of spam is different (you may want to be alerted every time a new album by Destiny’s Child is released but I’d just as soon not be bothered), it’s important for a spam filter somehow to learn a user’s preferences.
The challenge is to create a filter that learns these preferences without requiring too much work of the user, since the whole idea is to save time and avoid aggravation. The user of a spam filter relying on supervised learning might have to mark several thousand messages as spam or ham before the learning program could make distinctions acceptably on its own. A prospective user of such a program might well not want to take the trouble. An alternative to making a single user supply all the training examples is to collect examples from many users with similar preferences and use them to train the spam filter. This is an example of collaborative filtering, which identifies patterns in user preferences in order to guide users in finding goods and services and to guide sellers in marketing those goods and services. You see collaborative filtering at work when you visit an online retailer and see something like, “Customers who bought this book (or CD or DVD or video game) also bought:” followed by a list of similar products.
Most email clients keep your email messages in a file typically called an INBOX. There are all sorts of email protocols, for example POP and IMAP, and all sorts of clients and servers that implement these protocols, but sooner or later a spam filter is going to have to grub around in an INBOX file full of messages in some format or possibly in multiple formats. Message formats differ in how they deal with headers (the "To:", "From:" and "Subject:" fields that you see at the top of every message), message content (some email clients allow embedded HTML or other text formatting), and attachments (the different ways that binary files corresponding to images and documents are encoded, compressed and attached to a message). Before we can do any learning, we’re going to have to make sense of these formats.
A point about the applications of artificial intelligence is probably in order before we go too much further. AI technologies embedded in applications have been likened to raisins in raisin bread:without the raisins you still have bread, it just ain’t raisin bread. The machine-learning algorithms in a spam filter are like the raisins in the raisin bread; they add value to the product but you still need all the dough around them to sell it. A spam filter needs tools to analyze and parse the contents of INBOX files, a user interface to communicate with the user, and an applications programming interface so that the filter can coordinate with the email client. The amount of code involved in machine learning, while important to the product, could be pretty modest. Before examining the raisins more closely, let’s take a quick look at some of what is needed in the surrounding dough.
The first thing you might want to do with an INBOX is to identify the pieces of the file that are relevant to your application, spam filtering in this case. A lexical analyzer or lexerscans an input stream such as that produced by reading a file one character at a time and applies a collection of rules to convert the stream into a sequence of meaningful tokens. Each rule specifies a pattern and an action. If the lexer scanning the input stream sees a group of characters that match the pattern for a given rule, then it performs the action associated with the rule. For example, a set of lexer rules for making sense of an INBOX might include a rule that looks for the sequence of characters "From:" and converts it into a FROM token.
Other tokens might include BEGIN-MESSAGE, END-MESSAGE, ADDRESS, SUBJECT, URL, etc. In some cases, the tokens take the place of pieces of the input stream; for example, the string "From:" is replaced by the token (FROM), as is the string "FROM:" (it’s irrelevant whether the characters are upper- or lowercase). In other cases, the tokens are attached to actual pieces of the input stream; for example, tld@cs.brown.edu is replaced by (ADDRESS "tld@cs.brown.edu"). A lexer typically strips away irrelevant information such as spaces, tabs and carriage returns and emphasizes the meaningful content.
Here’s an email message I got recently (MIME, for “multipurpose internet mail extensions,” is a widely used standard for encoding binary files as email attachments):
From: "Sulee Jenerika" <ejls@cs.brown.edu> To: "Tom Dean" <tld@cs.brown.edu> Subject: Re: Artemis Brochure Hi Tom, We've got a revised draft for the Artemis 2003 Brochure. Take a look and tell us what you think. Sulee [MIME-ATTACHMENT ...]
A lexical analyzer for a spam filter might turn this message into the following sequence of tokens: (BEGIN-MESSAGE), (BEGIN-HEADER) (FROM), (WORD "Sulee"), (WORD "Jenerika"), (ADDRESS "ejls@cs.brown.edu"), (TO), (WORD "Tom"), (WORD "Dean"), (ADDRESS "tld@cs.brown.edu"), (SUBJECT), (WORD "RE:"), (WORD "Artemis"), (WORD "Brochure"), (END-HEADER), (BEGIN-BODY), (WORD "Hi"), (WORD "Tom"), ..., (BEGIN-MIME-ATTACH), ..., (END-MIME-ATTACH), (END-BODY), (END-MESSAGE).
There’s more structure in an INBOX file than is immediately evident in a sequence of tokens. For example, the subsequence (FROM), (WORD "Sulee"), (WORD "Jenerika"), (ADDRESS "ejls@cs.brown.edu") is analogous to a prepositional phrase, indicating that the enclosing message is from (the preposition) someone identified by the supplied words (the proper noun serving as the object of the preposition) and described by the given address (an adjective of sorts further qualifying the object of the prepositional phrase).
The structure in email messages and INBOX files can be described by a grammar with rules not unlike those you may have learned in grade school — for example, a prepositional phrase consists of a preposition and a noun phrase. However, unlike the rules of English grammar, which we’re told by grammarians and style mavens alike serve only as guidelines, the grammar of messages and INBOX files is firmly adhered to, making it relatively easy to extract their content. A parsertakes the output of a lexical analyzer and applies a set of grammatical rules to transform a sequence of tokens into a structured object capturing the content and structure of the original input stream.
Continuing with our example, the parser turns the token sequence generated by the lexical analyzer into the following structured object:
(MESSAGE
(SENDER (NAME "Sulee Jenerika")
(ADDRESS "ejls@cs.brown.edu"))
(RECIPIENT (NAME "Tom Dean")
(ADDRESS "tld@cs.brown.edu"))
(SUBJECT "Re: Artemis Brochure")
(BODY (TEXT ("Hi" "Tom" ...))
(MIME-ATTACHMENT (FORMAT PDF)
(COMPRESSION ZIP)
(DOCUMENT ...))
...))
It may not seem that we gained much, but this format makes it much easier for a program to extract the pieces of an email message relevant for spam filtering. I used a lexical analyzer called lexand a parser called yacc3 (which stands for “yet another compiler compiler”) to convert my INBOX (actually several INBOX files) into a set of structured objects that I could feed into various learning programs written in C, Lisp and Mathematica.
8.2 Machine learning
Let’s suppose that we’ve analyzed and parsed our files of full of email messages, interfaced with the user, interoperated with the email client, prestidigitated the whoozits and whatsits and generally done everything except separate the spam from the ham. The bread is rising and now we need to come up with some nice plump raisins. How do we get our spam filter to tell the difference between spam and ham?
You might imagine there is a general-purpose learning algorithm that can take a raw email message as input and decide on the message’s spamishness without our supplying any background knowledge or hints about what’s important to attend to and what’s not worth worrying about. While learning algorithms exist that are capable of such a feat, they tend to require a large number of training examples in order to perform well. The reason is that they’re trying to learn from first principles — they don’t have any a priori idea of what’s important and what’s not, and so they have to look at more data and work harder.
It often requires fewer training examples and results in better performance to give a learning algorithm a good idea of what data features are likely to be worth attending to. In trying to distinguish between arctic char and atlantic salmon, an expert might tell a novice to look first at the color of the skin on the underbelly and then at the lower jaw. It’s rare in life that we have to learn something entirely new with no outside help, and so it makes sense to give our learning algorithms whatever hints we can manage.
What features might be appropriate for a spam filter? In distinguishing spam from ham, it’s often useful to know whether the email came from someone at a company (a “dot com”) or a school (a “dot edu”). Other designators, for example organizations (a “dot org”) or the government (a “dot gov”), may also prove relevant. If the subject line indicates that someone is replying to an earlier message from you, for example, the subject contains "Re:" or "RE:", that could indicate a legitimate email message — unless a clever spammer is trying to fool you. If the subject line or body of the message includes any of the words "buy", "sell", "winner", "prize", "sale", and the like, then the message may be an advertisement or promotion. Messages with attached images or compressed files with the extension "EXE" are generally, though not always, unwanted.
After you’ve thought about this for a while, you might think you could write a spam filter yourself. You could specify a bunch of features such as, SENDER-DOT-COM, which is true (#t) if the address of the sender ends with the string "com" or "COM" and false (#f) otherwise. You could process each message to assign values to each of the features you’ve identified as relevant and then summarize the message as the set of these assignments. For example, our sample message above might look something like this Scheme list:
((SENDER-DOT-COM #f) (SENDER-DOT-EDU #t) (SUBJECT-IS-REPLY #t) (SUBJECT-CONTAINS-FREE-WORD #f) (BODY-CONTAINS-SALE-WORD #f) (BODY-CONTAINS-BUY-WORD #f) (BODY-FORMATTED-HTML #f) (ATTACHED-PDF-DOC #t) (ATTACHED-JPG-IMG #f) ...)
Given this set of features, your hand-written spam filter might look thus:
if SUBJECT-IS-REPLY
HAM
else if SENDER-DOT-COM
if BODY-CONTAINS-SALE-WORD
SPAM
else if BODY-CONTAINS-BUY-WORD
SPAM
else if SUBJECT-CONTAINS-FREE-WORD
SPAM
else HAM
else if SENDER-DOT-EDU
if ATTACHED-JPG-IMG
SPAM
else HAM
else if BODY-FORMATTED-HTML
SPAM
else HAM
So why wouldn’t this or something like it work? One reason is that if the program got much larger and more complicated it would be impossible to understand. It’s really difficult for a programmer to keep track of all the cases, especially if, as is likely, there are hundreds of possibly relevant features instead of the half dozen or so in our small example. But the biggest problem is that, however good our intuitions about features signifying spam, we’ll probably miss some features or combine them in the wrong way and end up with a filter that allows too much spam to pass.
What we need is a learning algorithm that can analyze a lot of data, consider a lot of different features and come up with a high-performance filter. Somehow our learning algorithm must search in the space of possible programs of the sort described above. Think about the set of all such programs using only if-then-else statements and a fixed set of features as variables. Let’s say there are n features. How many such programs are there? The answer is lots: there are 2n possible assignments to the n features and hence 2n possible email messages that we can distinguish. A spam filter divides the set of messages into two classes, spam and ham, and hence there are as many programs as there are ways of dividing 2n messages into two classes, which for any reasonably large n is a very big number.
For a given training set, the set of examples on which we’ll base our spam filter, very likely more than one program will correctly classify all the examples, identifying spam as spam and ham as ham. For example, suppose that spam can be reliably identified by determining that the sender is a dot com and the body of the message contains HTML formatting and an attached JPG image. Here’s a filter implementing this characterization of spam:
if SENDER-DOT-COM
if BODY-FORMATTED-HTML
if ATTACHED-JPG-IMG
SPAM
else HAM
else HAM
else HAM
Assuming that our characterization of spam is correct, you could use additional features in implementing a spam filter, such as whether or not there are PDF attachments, but they wouldn’t help. Might they hurt? Yes, for a couple of reasons.
One reason is that the extra features might result in a large, slow spam filter. If you use all n features, you would construct a filter of size 2n, which would certainly be impractical for reasonably large n. A more important reason from the standpoint of learning, however, is that the extra features might be misleading and make it more difficult to generalize beyond the training examples.
Keep in mind that it’s this generalizing beyond what you’ve already seen that you’re really after. You’ve already classified all the training examples as spam or ham, and you’re unlikely see these exact messages ever again. You want to classify future messages. Suppose all of the messages in your training set containing the word “free” in the subject line just happen to be messages you want to read and so you write the following filter:
if SUBJECT-CONTAINS-FREE-WORD
HAM
else if SENDER-DOT-COM
if BODY-FORMATTED-HTML
if ATTACHED-JPG-IMG
SPAM
else HAM
else HAM
else HAM
With this filter, you’ll misclassify spam messages that have “free” in the subject line. The first if-then-else statement in the classifieris not only superfluous, it leads to misclassification. In practice, the best classifiers appear to be the simplest, most compact and reliant on the fewest features. This observation is in accord with Occam’s razor, a heuristic or rule of thumb harking back to William of Ockham’s principle of parsimony: simpler theories are better than more complex ones. There is no fundamental justification for believing that simpler theories are in general better and indeed there are theorems, aptly called no-free-lunch theorems, that suggest there is no best (or universally optimal) method of choosing classifiers. That said, learning algorithms that employ some variant of Occam’s razor to choose among classifiers tend to perform well in practice.
How might we design a learning algorithm to select a classifier in accord with Occam’s razor? Here’s a simple recursive algorithm that is the basis for one of the most widely used and practical methods for machine learning.
The input to our learning algorithm is a set of examples labeled spam or ham. The output is a classifier consisting of nested if-then-else statements. Each if-then-else statement uses one of the n features as its condition or test, and the then and else branches contain either another (nested) if-then-else statement or a classification, spam or ham.
The algorithm, which we’ll call build, works recursively as follows. build takes two arguments: a set of examples that have yet to be classified and a set of features that have yet to be used. If all the examples yet to be classified are spam, then build returns SPAM. If all are ham, it returns HAM. If some are spam and some are ham, build chooses a feature and constructs an if-then-else statement by inserting the selected feature as the test and computing the then and else branches by calling build recursively on the remaining features and the examples split according to those in which the selected feature is true (the then branch) and those in which the selected feature is false (the else branch).
Here’s what build might look like implemented in Scheme. This code uses the Lisp quasi-quotenotation (“‘”), which is particularly useful in programs that produce other programs as output. We looked at various quoting mechanisms for use in shell scripts in Chapter 2. The Lisp quasi-quote notation is similar to the quoting options available in shells in that it includes mechanisms for both suppressing and forcing evaluation. The quasi-quote mark suppresses evaluation in the expression that immediately follows except when it encounters a comma (“,”), which forces the evaluation of the immediately following expression. So, for example, the expression ‘(1 ,(+ 1 1) 3) evaluates to (1 2 3). Here’s a somewhat more complicated example a little closer to our present application:
> (let ((feature 'SENDER-DOT-COM) (yes 'HAM) (no 'SPAM))
(if #f
'HAM
`(if ,feature ,yes else ,no)))
(if SENDER-DOT-COM HAM else SPAM)
Be careful to distinguish the single-quote character or apostrophe, “’”, from the back-quote character or quasi-quote mark, “‘”; the apostrophe suppresses all evaluation in the expression that immediately follows. Here’s the implementation of build in Scheme using the quasi-quote mechanism:
(define (build examples features)
(if (all-spam? examples)
'SPAM
(if (all-ham? examples)
'HAM)
(let ((feature (choose-feature examples features)))
`(if ,feature
,(build (true-examples feature examples)
(remove feature features))
else ,(build (false-examples feature examples)
(remove feature features))))))
This code should give you a pretty good idea of how build produces a classifier, but it doesn’t explain how it produces compact classifiers that use few features. A key part of this algorithm is in the choose-feature function, which considers how each of the remaining features would split the examples into then and else branches and chooses the feature producing the “best” split. I’ll give you some examples illustrating how one split might be considered better than another.
Suppose choose-feature finds a feature such that the then branch would end up with all spam and the else branch with all ham. That’s a great split; you can’t do any better than that. Suppose choose-feature finds a feature such that the then branch ends up with half spam and half ham and ditto for the else branch. That’s a lousy split since it made no useful distinctions among the remaining examples; you can’t do any worse.
In general, splits that yield then and else branches in which the remaining examples have more of one type of message than the other are good and those in which the numbers of spam and ham are approximately equal are bad. There are a number of functions ranging from zero (equal proportions of spam and ham) to one (all spam or all ham) that work about equally well for selecting a good split. It’s quite amazing that such a simple algorithm is so effective in such a wide range of problems.
Of course, you had to do some of the work: you had to select a set of possibly relevant features. The more features you select, the more likely build will find a good set of features with which to implement a classifier. But more features also make build work harder, and it’s always possible that you’ll overlook important features. There’s no easy solution to this problem: finding good features is hard and that’s why experts capable of making fine distinctions for particular problems are in such demand.
The build function implements an instance of what are called decision-tree algorithmsbecause the if-then-else structures of the resulting classifiers look like trees whose branches are features that help decide the classification of the input to the classifier. Decision-tree algorithms are among the most common learning algorithms, but there are other algorithms and other approaches to machine learning.
8.3 Learning with probabilities
Research in machine learning often looks like a branch of applied mathematics. Ideas from probability and statistics are often used directly in learning algorithms or in analyzing and justifying techniques that at first blush seem to have nothing to do with probability or statistics. We’ll take a peek at how to apply this sort of mathematics to spam filtering. This section is a little more technical than earlier ones and you may want to skip it if you don’t enjoy playing around with equations and manipulating mathematical symbols.
You probably don’t want a primer on probability theory and so I’ll go easy on the formalities. Let’s say that Pr(SPAM) is the fraction of all email messages that are spam; we’ll call this the probability of spam. According to this definition, since all messages are either ham or spam, Pr(HAM) = 1 - Pr(SPAM) is the fraction of all email messages that are ham. Let’s say that Pr(COM,HTML) is the fraction of all email messages such that the sender is a dot com and the body of the message contains HTML. In general, Pr(X1, X2,..., Xk) is the fraction of all email messages satisfying X1 through Xk.4
Finally, let’s say that Pr(SPAM|HTML) is the fraction of email messages containing HTML that are also spam; this is called the conditional probabilitythat a message is spam given that it contains HTML (you can read the vertical bar as “given that”). Stated in another way, Pr(SPAM|HTML) is the ratio of Pr(SPAM,HTML) to Pr(HTML): divide the fraction of messages containing HTML by the fraction of messages that are both spam and contain HTML. With these simple definitions, we can do quite a lot of practical mathematics.
To make things simple, suppose our set of features consists of HTML, which is true if a message contains HTML, COM, which is true if the sender’s email address is a dot com, and SALE, which is true if the word sale appears in the message. We’ll put the negation symbol ¬ in front of a feature to indicate that that feature is not present: thus COM corresponds to (SENDER-DOT-COM #t) and ¬COM corresponds to (SENDER-DOT-COM #f). Note that Pr(HAM) = Pr(¬SPAM) and similarly Pr(SPAM) = Pr(¬HAM).
Given a message summarized by the assignment (BODY-FORMATTED-HTML #t), (SENDER-DOT-COM #t) and (BODY-CONTAINS-SALE-WORD #f), we’re interested in calculating Pr(SPAM|HTML,COM,¬SALE), the probability that the message (characterized as containing HTML, sent by someone at a dot com, and not containing the word sale) is spam. We’d use this quantity in a spam filter by establishing a threshold, say 0.9, such that if Pr(SPAM|HTML,COM,¬SALE) > 0.9, we classify the message as spam and eliminate it from the user’s INBOX.
Why the threshold? By using probabilities, we’ve implicitly given up on distinguishing spam from ham with certainty. Sooner or later we have to choose to treat a message as ham and send it along to the user or treat it as spam and delete it. The threshold determines an important tradeoff. If we set the threshold too high, then nothing is classified as spam and we’re likely to send along a lot of it. If we set the threshold too low, then everything looks like spam and we’re likely to eliminate some ham. It may make sense to let the user set the threshold; some may prefer losing an occasional piece of ham to wading through a lot of spam, and others may be willing to accept some annoying spam rather than miss a critical piece of correspondence.
Now we don’t know Pr(SPAM|HTML,COM,¬SALE) and so we’ll have to calculate it using the probability calculus, a set of rules for manipulating probabilities. It turns out that while we don’t have Pr(SPAM|HTML,COM,¬SALE) it’s pretty easy to calculate reasonable estimates of probabilities such as Pr(HTML|SPAM), Pr(COM|SPAM) and Pr(¬SALE|SPAM) from looking at a set of training examples. For example, the estimate for Pr(HTML|SPAM) is just the ratio of the number of training examples that contain HTML and are spam to the number of examples that are spam. Using these probabilities and certain assumptions about the probability that features co-occur, we can calculate Pr(SPAM|HTML,COM,¬SALE) using Bayes’ rule, a particularly useful rule of the probability calculus named to recognize the Reverend Thomas Bayes(1701–1761), an English cleric and mathematician. The implications of Bayes’ rule are so important that an entire branch of probability and statistics is called Bayesian probability theory.
In medicine, the conditional probability that a patient exhibits a particular symptom given that the patient has a particular disease can often be estimated. This is called causal knowledge since it provides evidence on whether or not the disease causes the symptom. Hospitals keep records to track patients, their diseases and their symptoms. A reasonable estimate of the probability that a patient exhibits a particular symptom given that the patient has a particular disease is just the ratio of the number of patient records showing both the disease and the symptom to the number of patient records showing the disease (whether or not the patient exhibited the symptom).
In treating patients, however, as in identifying spam, we’re interested primarily in diagnostic knowledge: the probability that a patient has a particular disease given that the patient exhibits a particular symptom. We could estimate this as the ratio of the number of patient records showing both the disease and the symptom to the total number of patient records showing the symptom, but this estimate tends to be more fragile. If there is an outbreak of the disease, the hospital will suddenly start seeing more patients with the symptom, but until these patients are diagnosed, the physicians won’t be able to update their diagnostic knowledge accurately. The causal knowledge, on the other hand, will be unaffected.
Here’s the basic formula for Bayes’ rule:
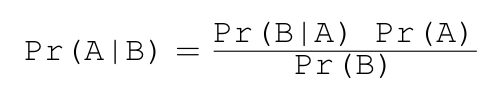
Substitute “symptoms” for B and “disease” for A and you’ll see how Bayes’ rule applies to medical diagnosis. Substitute “features” for B and “spam” for A and you’ll see how Bayes’ rule applies to spam filtering. You’ll also notice that to get Pr(A|B) from Pr(B|A) you need Pr(A) and Pr(B). Think about diseases and symptoms and imagine how you’d estimate the probability of a patient exhibiting a given symptom or the probability of a patient having a given disease by using hospital records.
We can derive Bayes’ rule using only the definition of conditional probability. The last line (4) of this derivation is the simplest formulation of Bayes’ rule.

In order to use Bayes’ rule to calculate Pr(SPAM|HTML,COM,¬SALE), we’ll also rely on the rule of probability Pr(B) = Pr(B|A) + Pr(B|¬A), which we now justify informally. Think about the probability that a message contains HTML. If we know the probability that a message contains HTML given that it’s spam (the proportion of spam messages containing HTML) and the probability that a message contains HTML given that it’s ham (the proportion of ham messages containing HTML), then, since a message must be either spam or ham, the sum of these two probabilities is the proportion of all messages containing HTML, that is the probability that a message contains HTML.
Finally, we’re going to need a way of calculating Pr(HTML,COM,¬SALE|SPAM). If we had enough training examples we could do this directly, but if we have many more features, and we probably will in order to build any really effective spam filter, then we will need far too many training examples to get accurate estimates for all the probabilities of this form. Think about how many probabilities of this form you would actually need; for just three features we’d need

and so on for all eight possible combinations. If you have only ten features (and that’s probably not enough) and you need even ten examples to estimate each probability (and that’s not nearly enough), then already you’d need at least 10,000 training examples, and there are probably some rare combinations for which you still won’t have enough examples.
As an expedient, we’ll assume that all our features are mutually independent, given the status of a message as spam or ham. This would mean that the presence of HTML in a document is completely independent of it coming from a dot com. This assumption of independence is unlikely to be true for all pairs of features; for instance, if we see the word sale in the subject line of a spam message, it is far more likely to be from a dot com than from a dot edu, so COM and SALE are not independent of one another given spam. Even so, such assumptions are often made on the justification that they won’t hurt too much, and practically speaking there aren’t many alternatives. If we accept this assumption, then we can calculate Pr(HTML,COM,¬SALE|SPAM) as the product of Pr(HTML|SPAM), Pr(COM|SPAM) and Pr(¬SALE|SPAM), all relatively easy to estimate. So, given the above derivations and assumptions, we can calculate the desired probabilities as:

The assumption that all the features are mutually independent given their designation as spam or ham, which is what allows us to compute Pr(HTML,COM|SPAM) as the product of Pr(HTML|SPAM) and Pr(COM|SPAM), is a concession to computational considerations that warrants great care in its application. Other concessions are implicit in the approach described above. In practice, it is likely that for some of the features you decide to use very little data will be available to estimate the required probabilities. You can choose to throw such features out or you can use them with care. Quantifying the consequences of using such questionable features is the province of applied statistics.
Clearly there are complications and problems to overcome in using lessons from probability theory to design a good spam filter. Spam filters already on the market tout their use of Bayesian probability theory. But there are also spam filters using neural networks, decision trees, genetic algorithms and any of a host of other techniques and algorithms studied in artificial intelligence. The engineers and practitioners in the field keep pushing the envelope of what computers can learn. And little bits of machine learning, like raisins in raisin bread, are finding their way into more and more applications. Machine learning may not work in the same way that human learning does, but it’s learning nonetheless. Today, computers can play chess, schedule commercial aircraft, identify credit-card fraud and diagnose problems in automobiles better and faster than humans. Tomorrow, who knows what they’ll be able to do better than we can?
8.4 Learning more about learning
I’m often asked to suggest books to read for a good introduction to artificial intelligence and machine learning in particular. Several years ago I co-authored an introductory artificial intelligence text covering both theory and practice. The text features a brief introduction to programming in a dialect of Lisp called Common Lisp and gives readers the opportunity to connect algorithms to working programs and theory to practice. All the algorithms are specified in both pseudocode and Common Lisp and a supplement available on the web provides all the code described in the book plus examples. The supplement also provides support for translating the Common Lisp code to Scheme. It’s still a good beginning textbook but artificial intelligence, like the larger field of computer science, is evolving rapidly.
About the same time as my book came out, Stuart Russell and Peter Norvig published a more comprehensive and detailed textbook. The second edition of their book, which came out in 2003, is even more comprehensive than the first and I’ve just got to say it is a wonderful text. Extensive supplements include implementations of the algorithms in Common Lisp, Python (which is similar in some respects to Perl but was designed from the bottom up as an object-oriented programming language), Prolog, C++ and Java. It is an excellent introduction to the field accessible to most college students and also containing advanced material of interest to graduate students.
If you’re interested primarily in machine learning, Tom Mitchell’s Machine Learning gives a good basic introduction to machine-learning theory and algorithms. Relevant to the applications covered in this chapter, the web site for the book features code supplements for learning decision trees (written in Common Lisp) and Bayesian learning to classify articles posted to news groups (written in C).
It probably sounds like a typical sort of academic remark, but I can’t emphasize enough the advantages of a thorough grounding in basic mathematics including graph theory, linear algebra and, especially if you’re interested in machine learning, probability and statistics. For a solid two-semester introduction to probability and statistics, DeGroot’s Probability and Statistics is my favorite textbook. I consult DeGroot’s text and refer my students to it regularly. A third edition is now available.
1 Tom Van Vleck, an MIT undergraduate, wrote one of the first email programs for the Compatible Time-Sharing System (CTSS) developed as part of MIT’s Project MAC (for “multiple access computer” and “machine-aided cognition”). CTSS was one of the first operating systems that supported multiple users and time sharing. Ray Tomlinson, a computer scientist at Bolt Beranek and Newman (BBN), sent the first email message between two computers. Tomlinson had already written an email program for an early time-sharing system that was running on most machines on the ARPANET (ARPA is the federal government’s Advanced Research Projects Agency), which was the precursor to the Internet and the World Wide Web. In 1971, Tomlinson took the next logical step and sent an email message from one machine to another connected by the ARPANET.
2 SPAM is a registered trademark of the Hormel Foods Corporation. The product from Hormel is marketed as a luncheon meat and has nothing to do with electronic mail.
3 The programs lex and yacc are old warhorses: they’re still widely used but they’re not the latest lexical analyzers and parsers available. If you’re interested in playing with such programs, you might want to check out flexand bison, analogous tools available from the GNU Project and the Free Software Foundation.
4 Suppose that X1 = (1/2) is the probability that a coin lands heads up the first time you flip it, X2 = (1/2) is the probability that the same coin lands heads up the second time you flip it, and so on. Assuming that the coin flips are independent of one another in the sense that one flip doesn’t influence any other, Pr(X1, X2,..., Xk) = ((1/2))k = (1/2k) is the probability that the coin lands heads up all k of the times you flip it. Why do you think many people wrongly believe that a fair coin (not a trick coin from a magic store) that has come up tails many times in a row is likely to come up heads the next time you flip it?