|
|
|
|
Piano Movers and Social Networks |
|
|
|
|
Glancing back at Monday's entry, it seems a bit preachy or border-line textbook material. I do believe that trees and graphs are important tools for computer scientists to understand, and algorithms like depth-first and breadth-first search are about as fundamental and practical as they come. That said I'm not trying to teach you the fundamentals; I'm just trying to get you interested enough that you'll learn for yourself.
While riding in on the bus this morning, I was trying to read a paper one of my graduate students handed me a couple of days back. I'd already scanned it once and this time I was "reading for comprehension" as they say. Unfortunately, there were only two passengers on the bus when we left from Little Compton and the bus driver and the other passenger started up a conversation that continued almost the entire trip with their voices getting steadily louder to compensate for the sound of the engine and the other passengers as they got on at various stops along the way.
Part of my mind was following their conversation - occasionally early on they tried to include me but this stopped when I only smiled and nodded but didn't join in - and the other part of my mind, after reading the abstract and first few paragraphs, got wedged and ended up reading the same few lines, dense with equations and definitions, over and over. Eventually I gave up on the paper and as my mind started to wander free I noticed, again, the names of the authors and then, thinking about the content of the paper (the title "Latent Dirichlet Allocation" doesn't really tell you much), it dawned on me that here were examples of two very interesting graphs.
The paper is about models (specifically "generative models" - models that are able to generate instances of whatever it is they are modeling) that explain the presence of words and the relevance of topics in web pages or, more generally, text documents of any sort. The model proposed in this paper suggests that each web page is "generated as a mixture of topics" - that is to say the author of a web page writes the text for the page with a set of topics in mind, perhaps one major topic and a few secondary topics.
I'm writing this entry, which will soon be a web page, with the major topic of "graphs" and secondary topics including "models of computation", "World Wide Web", and "social networks". The proposed model is a probabilistic model in that it accounts for the presence of words and the influence of topics in terms of the probabilities that, say, a word appears in a document given that the author has in mind a particular topic. So, given that one of my topics is the World Wide Web, there's a pretty high probability that I'll mention the word "hyperlink".
The World Wide Web is perhaps the largest human-made artifact and it can be modeled quite naturally as a graph with the nodes being web pages and the links being hyperlinks, the pieces of text that you click on to go to another web page. (These pieces of text are attached to little pieces of code that you can't see but that specify a protocol - a language for talking with another program - and the address, also called a universal resource locator or URL, of a web server and web page that you'd like to look at.) The web graph as it is called now has billions of nodes. That's a big graph and when it comes down to searching this graph, unless you have considerable computational resources, you might as well think of this graph as infinitely large. The size of the web is complicated by the fact that large parts of it are virtual in the sense that many of its pages, e.g., pages showing merchandise at on-line stores, don't exist until someone wants to see them and then they are created on the fly and often personalized in their content and format for the particular customer.
The web graph is huge and given that people want to find useful web pages it's important to be able to search the web graph efficiently. Strictly speaking the web graph is a directed graph with cycles; hyperlinks tell you how to go from the page you're on to the page they point to but you have to do more work - search the graph exhaustively or nearly so - in order to find out for a given page what other pages point to it, i.e., those pages that contain hyperlinks to the given page. We can uncover interesting structure in the web graph by just looking at how web pages are connected to one another without even looking at the contents of the pages. We'll need a couple of technical terms and definitions to talk about this structure more precisely.
A connected component of a directed graph is the technical term for a subset of the nodes in the graph such that every node in the subset is reachable from every other node in the subset. By "reachable" we mean there is a path in the graph connecting the two nodes. A strongly connected component is a connected component that isn't contained in any larger connected component. The web graph has sinks corresponding to connected components that have incoming hyperlinks but no outgoing links so that once you enter a sink you can't exit simply by following hyperlinks. There are also large connected components that have no no incoming links so once you leave you can't get back in by traversing hyperlinks (of course, you can always just connect to a URL if you remember it). Drat! I'm late for a meeting; I've got to run.
I was just distracted by a couple of scheduled meetings that I'd almost forgotten about. Albert Huang, an undergraduate working at Brown this summer, and I had to meet someone in Neuroscience to pick up a robot arm they're going to let us use. The arm was a very nice multi-jointed (six-degrees of freedom) arm with an industrial quality controller and a force-torque sensor for the wrist that had never been installed. The arm weighed around 40Kg (around 110 pounds for the metric-challenged) and the controller about half that. In addition, we had to move a heavy table that the robot was mounted on and a bunch of crates and miscellaneous boxes. It was a good hour's sweaty work but made interesting by having to figure out how to use the ancient (and woefully undersized by modern standards) freight elevators in Metcalf Labs and maneuvering heavy and ungainly objects through doors and corridors.
I explained to Albert that our task was an instance of the general piano movers problem, a problem in the field of computational geometry, that involves moving an object, represented in terms of a set of coordinates and surfaces in three-dimensional space, from an initial location to a final destination in an environment consisting of other objects also represented in terms of points and surfaces. The objective is to find a path from the initial to the final location such that the object to be moved doesn't intersect (collide) with the objects in the environment. Some human beings (and piano movers in particular) are pretty good at this. This problem is also important in robotics; think of the problem of planning a path for a mobile robot through a crowded room or the problem faced by a robot arm used on an assembly line in trying to reach into a partially assembled widget and drill a hole or align a part.
One elegant method of solving such problems involves reformulating the problem in terms of a higher-dimensional space with one dimension for each degree of freedom. A degree of freedom in this case corresponds to the ability to move in a particular direction, e.g., back and forth along some axis, also called a translational degree of freedom, or circularly around some axis, called a rotational degree of freedom. Using an idea generally attributed to Tomas Lozano Perez at MIT, you can "shrink" the object to be moved and "grow" the objects to be avoided to obtain an equivalent problem in which the object to be moved is a point. The resulting formulation, called a configuration space, can then be "discretized" by carving up the space into a bunch of small regions. A simple example will help you to visualize this.
Suppose that that you have a mobile robot that looks like a trash can. Remember R2D2 in Star Wars? This shape is convenient as we'll assume that the robot can move in any direction and looks the same from any direction in the horizontal plane. This robot is supposed to go into your room, find the trash can and then empty it. The first thing it has to do is plan a path from the door of your room to the trashcan. To simplify things, we won't worry about the z-axis (the height of the robot) but only the x- and y-axes (the floor of your room). The robot as two degrees of freedom, translation in the x and y directions. Suppose that you have a drawing of your bedroom showing your bed, desk, chairs, etc., all the objects that might constitute an obstacle to a robot trying to navigate in your room. Now grow the all of the obstacles including the walls of the room by the radius of the trashcan-shaped robot. A drawing is desperately needed here.
The following image shows my crude drawing of a room on the left and an attempt to shrink the robot and grow the obstacles as described above. The area enclosed by the green line is called the "free space" and indicates that portion of the room that the robot can move in without bumping into things.
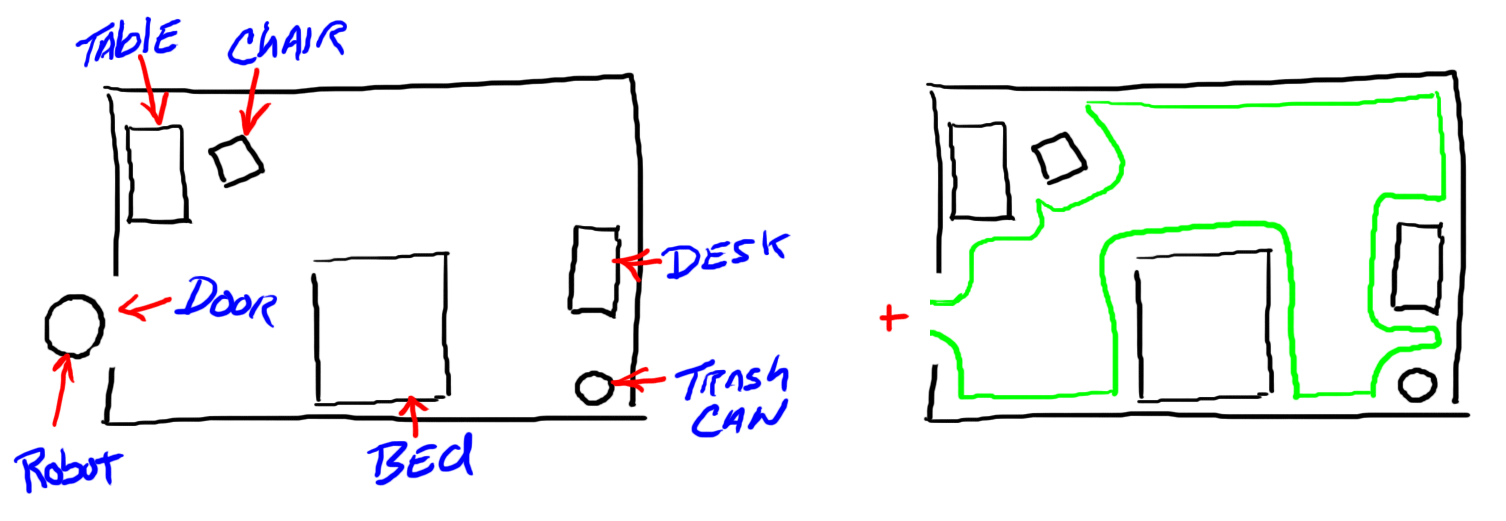
|
In the next drawing, I've penciled in a grid in blue over the room sketch. Then I filled in the elements of the grid as follows: if the region covered by a grid element is more than 50% free space then I leave it white otherwise I filled it in with magenta or whatever that purple-looking color is. (Note that I filled in the door closing the robot out of the room; that's a bug but one that can be fixed with a little adjustment.) Finally, I drew a path in red from the grid element closest to the robot's location to the grid element closest to the trashcan.
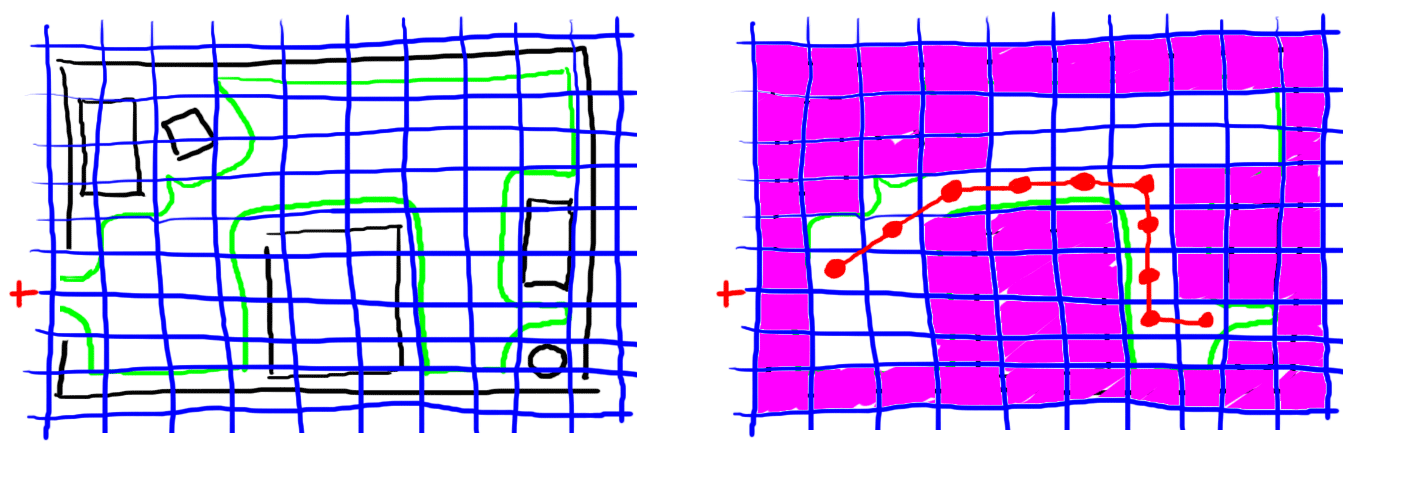
|
I realize that the reason I bring this example up now is that I'm still playing the ponderous pedant trying to teach you something. Anyway, the pedagogical point is that by laying down the grid over the continuous lines of the original drawing I've reduced a geometric problem to a problem involving graphs that I can solve by using a path finding algorithm. What's the graph? The graph consists of the square grid elements in the drawing above and the links are defined by adjacency in the grid, there's a link from one element to another just in case they are adjacent in the grid, above, below, right, left, or diagonally adjacent in any one of the four diagonal directions.
This same idea will work for all kinds of robot shapes (not just trashcan shapes), in three dimensions of physical space as well as two, and with robots capable of many degrees of freedom, but the problems are harder computationally with many degrees of freedom. The computational effort also depends on how finely you divide up the space with your grid. The size of the graph that you produce using this method is said to be of a size exponential in the number of degrees of freedom of the robot. If you slice up the space using say 1000 lines along each dimensional axis, which is not uncommon, and you want to plan paths for a robot like the one that Albert and I moved (it has six degrees of freedom) then you'll generate a graph with (103)6 or 1018 (1,000,000,000,000,000,000) nodes. Solving problems this size requires more sophisticated algorithms and data structures that we looked at earlier.
After moving the robot, I had to meet the Artemis instructors and some visitors from Goldman Sachs for lunch. Now, it's nearly 2:00PM and I've lost my earlier train of thought. Didn't help that I just spent 1/2 an hour talking about piano movers problems and drawing pictures.
I want to show you a picture of the big connected components of the web graph as they were depicted in a paper that was published a couple of years back [A.Z. Broder, S.R. Kumar, F. Maghoul, P. Raghavan, S. Rajagopalan, R. Stata, A. Tomkins, and J. Wiener, Graph structure of the web: experiments and models, Proceedings of the 9th WWW Conference, 1999]. I found the paper on line as a PDF (Portable Document Format) file using the NEC Research Institute Research Index (also called CiteSeer), opened up the PDF file using a free utility program, invoked another free utility I have sitting around for grabbing screen images to get an image of the diagram I wanted and saved the image as a GIF (Graphics Interchange Format) file, then I opened an image manipulation utility and pasted in the GIF file as a transparent layer and used this as a pattern to make my drawing in a second layer which I later saved as another GIF for this web page. Total elapsed time: about five minutes.
This is called the bowtie diagram and it's based on a snapshot of the web taken around May of 1999. The snapshot was obtained by Altavista, a company which builds search engines and offers related services, by using their search engine to crawl the web and find as many pages as possible. The web is much larger now and may or may not exhibit similar structure today; I have no doubt, however, that it exhibits some sort of fascinating structure. The blue circle in the middle is the knot of the bowtie; it's labeled SCC because it's the largest strongly connected component of the web graph, consisting of some 56 million nodes. The left side of the graph outlined in red and labeled IN is defined to be the set of nodes not in the SCC but connected to a page in the SCC by some path. There are about 44 million pages in IN. The right side, also outlined in red, and labeled OUT is a set of pages with the following property: any node in OUT can be reached by following hyperlinks starting from any page in SCC but no page in the SCC can be reached by following hyperlinks starting from a page in OUT.
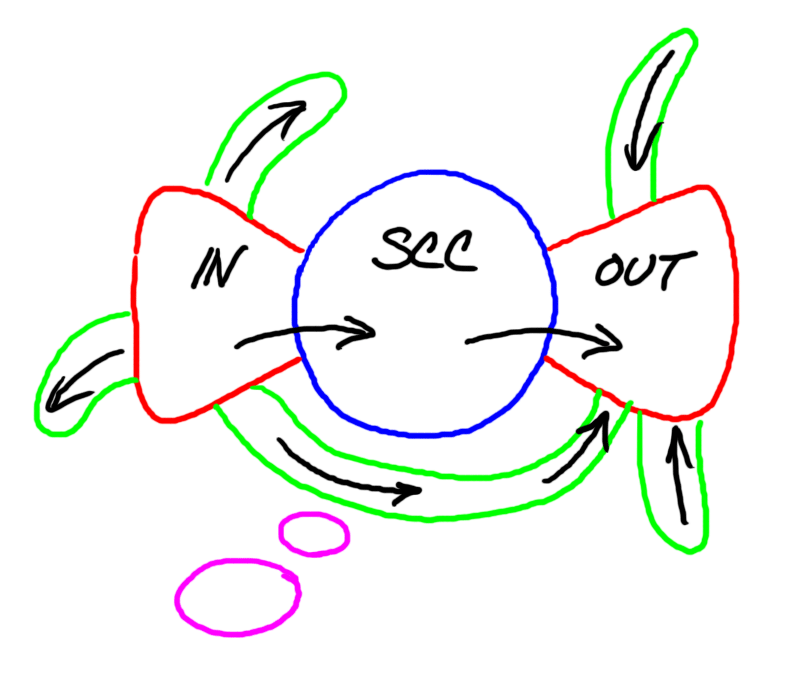
|
There are other interesting pieces of the web graph illustrated in the bowtie diagram: tendrils shown in green that lead out to "nowhere" starting from IN or start at "nowhere" and lead into OUT, or that tunnel from IN to OUT without hitting SCC. There are also completely disconnected pieces of the graph shown in purple. Since someone adding a hyperlink to a page expresses interest in that page, one might infer that pages that aren't pointed to either aren't interesting or haven't yet been discovered. Pages in SCC exist in a complex tangled web of references. The IN pages are interested in the SCC but no one in the SCC is interested in them; just the opposite for OUT pages. And, of course, this is just a snapshot; the web is quickly evolving to reflect the changing interests of people from all over the world. It used to be that people created most of the pages on the web by writing HTML (HTML stands for HyperText Markup Language and up until recently most web pages were written in HTML but now that is changing with the advent of powerful meta languages such as XML (for eXtensible Markup Language) which allow programmers to define new, more-powerful languages) directly or using programs that made it simple to compose text and pictures and produce the HTML automatically. Now most of the pages on the web are created by programs written by humans.
The day is speeding past and I also wanted to point out another interesting graph which the paper I was reading on the bus this morning reminded me of. The three authors of the paper are, in the order that they appear on the first page of the paper, David Blei, Andrew Ng and Michael Jordan all of whom are at UC Berkeley (and none of them famous basketball players). Michael Jordan is a professor at Berkeley. David and Andrew are graduate students (though Andrew is very close to finishing his thesis and going off to become a professor). What struck me as I kept being distracted by the bus driver's conversation this morning, was how these three people are related to me and that got me thinking about social networks, an interesting application of graph theory and social science.
Before the web, searching for information was done the "old fashioned way", I ask my friends and they ask theirs and eventually I get the information that I need. This notion of searching using a network of friends has been around forever but it became vogue in academia following the experimental work of Stanley Milgram and others in the social sciences in the 1960s. Milgram's work identified a so-called small-world phenomenon that seemed to indicate that there are six degrees of separation between any two people in the United States, i.e., it requires no more than six steps of indirection (someone who knows someone else) in order to get from any one person to any other person living in the U.S. Since that Milgram's early work, sociologists and psychologists have found evidence for a wide range of small-world phenomena arising in social networks.
Some of the time the connections are ones of family and friendship and some of the time they are professional (people who work in the same profession), institutional (the same institution), or technical (the same area of expertise). Being a professor at Brown makes it relatively easy for me to get the attention of a professor in some other department at Brown. And being a professor of computer science will often work as an excuse for calling a professor of computer science at some other institution. As an academic with some expertise in probability and statistics, I can usually gain an audience with mathematicians working probability and statistics whether they work in academia or industry. And then there are the networks and inner circles that you gained entrance to by dint of where you went to college, to graduate school, and the various professional and social organizations you've belonged to over the years.
You know how to navigate in these networks and you probably know of other networks that you can't navigate in but perhaps you know someone who can. Now that some of these networks are manifest in structure embedded in the web you might imagine programs that would do the navigating for you, both within networks and jumping between. What's the connection to the paper by David Blei and company? Well here are some of the networks. We'll confine ourselves to six people: David, Andrew and Michael, a couple of other "connections," namely Leslie Kaelbling and Thomas Hofmann, and then me. Three institutions: Brown, Berkeley and MIT. Michael was a professor at MIT before going to Berkeley and Leslie was a professor at Brown before going to MIT. Thomas was a postdoc (newly minted Ph.D.s often spend a few years working as "postdocs" before taking on a faculty position) with Michael at MIT and then followed him to Berkeley. Thomas is now an assistant professor at Brown. David worked with me and with Leslie when he was an undergraduate at Brown. Since David and Andrew were office mates at Berkeley, Andrew learned a lot about Brown (and probably about Leslie and me) from David. The model in the paper that David, Andrew and Michael wrote claims to be an improvement of a model in a paper that Thomas wrote. Andrew interviewed for faculty positions at both Brown and MIT. ...
Well, you get the idea; these are tangled webs of connections and this particular one gets considerably more complex after adding only a few more people. These networks are also graphs and they can be analyzed using graph algorithms and the mathematics of graph theory. Now that traces of many of these social networks are realized as subgraphs within the larger web graph it will be interesting to see what sociologists are able to tell us about ourselves by analyzing these graphs.
I'm running late today so I'll have to cut this short. The paper I mentioned above will appear in the proceedings of NIPS 14 (NIPS 14 is the 14th Conference on Neural Information Processing Systems and will be held in Vancouver, Canada in December of this year). It is a technical paper and requires a reasonably good background in statistics but it is very well written and the model is compelling. If you're interested, I expect you'll be able to find a copy of the paper on any one of the authors' home pages or by asking a friend who might know someone who ...