|
|
|
|
Forest for the Trees |
|
|
|
|
As soon as I finished yesterday's entry, it occurred to me that, while I briefly introduced the idea of "data structure" in the context of designing and analyzing algorithms, I haven't talked about a related (and actually more common) use of the term in the context of programming languages. In defining functions in Scheme, we only considered functions that take integer arguments with a only very brief, but not particularly illuminating foray into functions that take strings as arguments. Strings and integers are among the simplest of "primitive data types".
Other primitive data types include characters (which in addition to alphanumeric characters of the sort that can be embedded in strings also include special characters for the end of a line, end of a file, punctuation mark such as commas and the quotation mark itself, and language-specific characters such as Chinese characters and characters with umlauts and other diacritical marks), other varieties of number (single and double floating point numbers, rationals, short integers and long integers), and pointers that allow you to directly address locations in memory. In Scheme, I can, for the most part, remain blisfully unaware of the many different flavors of numbers and I seldom worry about characters, though they are becoming increasingly important in developing web applications that support multiple languages. In my own computing, I deal primarily with numbers and strings.
In addition to the primitive data types, there are "composite" data types that allow you organize multiple instances of the same data type or combine instances of several primitive (or composite) data types. All the obvious compositing mechanisms are generally available including bags (which assume no particular order), lists (which assume a linear ordering and are often called "arrays"), and tables (in which items are arranged vertically and horizontally in a grid and which generally are called "two-dimensional matrices"). There are also more specialized composites like association lists (which, like telephone books, store information, e.g., telephone numbers, under various keys, e.g., people's names) and the records and relational tables that we encountered when we played with the MySQL database.
Finally, no discussion of computer science data structures is complete without some mention of graphs and the various important specialized subclasses of graphs, including directed graphs, directed acyclic graph and, perhaps the most important and useful class of graphs of all, trees. This wasn't what I imagined I'd be working on today but now that I'm getting into it, this seems like a fine day to talk about trees and I'm looking forward to another chance to use the interactive LCD tablet to make some drawings of trees and graphs.
Where to begin? With graphs I suppose. Graph theory is a subarea of discrete mathematics (that's mathematics that deals with discrete, separable and often countable objects rather than, say, the continuous variables of calculus and real analysis) which is particularly relevant to computer science. The mathematics can be pretty abstract but the applications are everywhere and very concrete. As we'll see, each of the following, a network of computers, a web site, the entire World Wide Web, and a filesystem containing directories (folders) and files, can be thought of as a graph.
Mathematically a graph is a set of nodes (also called vertices) and a set of links (also called edges). A link is specified by a pair of nodes and the link can be either one-way (unidirectional) or two-way (bidirectional). The distinction between one-way and two-way links can be used to model the difference between connections that allow information to flow in both directions or in only one direction. Graphs are usually drawn with the nodes depicted as circles and the the links drawn as lines (bidirectional) or arrows (unidirectional). Sometimes the nodes are labeled with the labels appearing either inside the circle or nearby and sometimes the links are labeled as well with the labels attached or proximal in some way as to make the association clear. Looks like it's time to draw a picture.
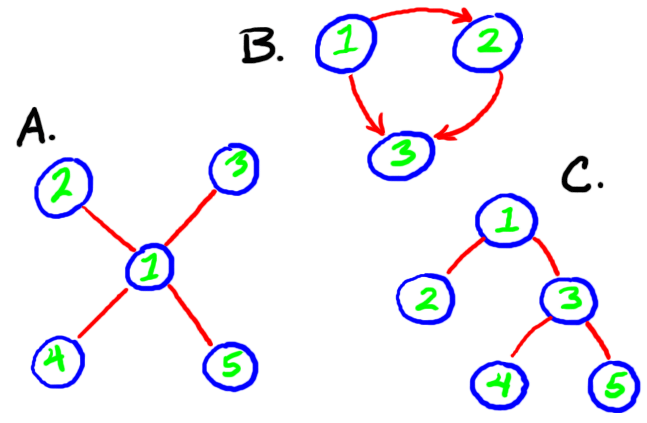
|
There are three graphs, labeled A, B and C, shown in the figure above. Generally, in a particular graph all of the links are either one-way or or all of them are two-way and we refer to a graph with all one-way links as "directed" and a graph with all two-way links as "undirected". (Note that you can simulate an undirected graph with a directed graph by using two two-way links in the directed graph (one pointing in each direction) to represent each one-way link in the undirected graph.) If we assume that we have only one link connecting any two nodes (or, in the case of directed graphs, one link connecting two nodes in any particular direction), then we can unambiguously specify any link as a unordered (the order doesn't matter) pair of nodes in the case of undirected graphs or an ordered pair in which the the "arrow" points from first node in the pair to the second node in the case of directed graphs. We can represent the undirected graph A as a set of five nodes {1,2,3,4,5} using the labels to specify the nodes and a set of four links {{1,2},{1,3},{1,4},{1,5}}. Similarly, we can represent the directed graph B as a set of three nodes {1,2,3} and a set of three (directed) links {{1,2},{2,3},{1,3}}. Graph theory is full definitions; I'll give you a little taste.
A path from one node to a second node in a graph is defined as a sequence nodes and links of the form, node1, link1, node2, link2, ..., linkn-1, noden (read, "node sub n") where node1 is the beginning of the path and noden is the end of the path and where each of the nodes is in the set of nodes for the graph and each of the links is in the set of links for the graph. Paths can be directed or undirected depending on the graph. In graph A, there is an undirected path from the node labeled 2 to the node labeled 4 defined by, {2,{1,2},1,{1,4},4}. In graph B, there is a directed path from the node labeled 1 to the node labeled 3 defined by {1,{1,2},2,{2,3},3}. There is also an undirected path from 2 to 4 in A defined by {4,{1,4},1,{1,2},2} but there is not a directed path from 3 to 1 in graph B. We might imagine an undirected version of B, call it B', where all of the one-way links are replaced by two-way links and such that there is an undirected path in B' from 3 to 1. A graph is said to be "connected" if for each pair of nodes in the graph there is path between the two nodes in the undirected version of the graph.
A connected graph (directed or undirected) in which for any two nodes in the graph there at most one path between the nodes is called a tree. A and C are trees but B is not because there are two paths between 1 and 3 ({1,{1,2},2,{2,3},3} and {1,{1,3},3}). A cycle in a directed graph is path that begins and ends at the same node and has at least one link. Almost as important as trees are DAGs (for Directed Acyclic (doesn't contain any cycles) Graphs); B is a DAG.
Sometimes it's helpful to talk about trees in terms used to describe their organic namesakes. In a tree corresponding to an undirected graph, any node in the tree can be specified as the (generally, there is only one so specified) root. In a tree corresponding to a directed graph, any node in the tree that has only outgoing links can be specifed as the root. Imagine a directed version of C, call it C', with all of the links pointing down (toward the bottom of the page); in this version of C, the node labeled 1 is the only candidate for naming the root of the tree. In a directed graph, the "parents" of a node are all those nodes that have links pointing to the node, and the "children" of node are all those nodes that have links pointed to starting from that node. Note that a node can have 0, 1, 2 or more parents and any number of children including none at all. In C', the node labeled 1 has no parents and two children, 2 and 3, while the node labeled 5 has one parent, 3, and no children.
Sometimes it's useful to refer to part of a graph as a subgraph. The graph consisting of the nodes {3,4,5} and the links {{3,4},{3,5}} is a subgraph of C, indeed, it's a subtree of C. Graph theorists (and computer scientists) also like to refer to the topology of a graph: A is an example of a graph with a star topology, the undirected version of B has a ring topology and C has a tree topology.
You've probably had enough of definitions and terminology but it does take a bunch of definitions before you can really get started in graph theory. Mathematicians like graph theory because both the mathematics and the graphs themselves can be beautiful. Computer scientists like graph theory for the same reasons plus the fact that they can use graph theory to analyze algorithms that operate on graphs (or things like computer networks that can be represented as graphs). For example, there is an algorithm that can fine the shortest path between any two nodes in a graph and the number of primitive computer operations this algorithm requires scales polynomially with respect to the size of graph. Recalling our analysis of algorithms for computing the nth element of the Fibonacci sequence, polynomially is much better than exponentially (our worst performing fibonacci algorithm) but significantly worse than linearly (our best performing fibonacci algorithm). Moreover you can prove that there is no algorithm that scales linearly, so you might as well not keep looking.
This result is important because it tells us that routing (finding paths for) packets (the pieces that comprise messages) in networks, which requires finding paths from the source for the packet to the destination for the packet, can be done relatively efficiently. We generally say that if something can be carried out by an algorithm that scales linearly or polynomially then it can be performed efficiently. If there is something for which all all algorithms scale exponentially (at best) then we say the problem is intractable. So graph theory tells us that routing packets in networks can be done efficiently, it's tractable.
Lets look a little more closely at how we might represent a computer network as a graph. Simplifying somewhat, computers are connected via cables to various kinds of equipment including other computers and specialized connection boxes variously called switches, hubs, routers and bridges (you'd need a short course in computer networks - or a browser, a search engine and a little patience - to understand the differences between these). Some of the "cables" might be a little complicated, e.g., a serial cable from a computer to a modem which uses a phone line to communicate with a second modem which is connected by another serial cable to second computer, but the basic idea is that there is some way of sending information back and forth along the cable between the devices attached to either end. Note that in this case the connections are bidirectional.
Typically, computer networks are configured (hierarchically) at multiple levels so that whole chunks of the network at one level correspond to the simplest atomic components at the next higher level. Computers in the same building might be connected via hubs and switches to form a local area network (LAN). LANs are typically organized in graphs that have star, ring or tree topologies. Computers within a company might be arranged as a wide area network (WAN) containing one or more LANs. In some cases, it makes sense to think of a WAN as a graph whose nodes consist of LANs. Then there are metropolitan area networks (MANs) and (presumably) one or more global area networks some of whose connections might be via satellite or cables laid along the beds of oceans. The graphs corresponding to these larger, continent-spanning networks, might be thought of as consisting of WANs and MANs for nodes.
So how would you actually go about representing a graph in a form (data structure) that a computer could make use of? We could use the mathematical notation that we introduced earlier almost directly. Indeed, Mathematica would be quite happy representing graph B as a pair,
{{1,2,3},{{1,2},{1,3},{2,3}}},
where the first element of the pair is the list of nodes and the second element is the list of links. And Lisp (or Scheme) would have no trouble using its notation for lists to represent graph B, with "curly brackets" replaced by parentheses (what else!) and commas replaced by spaces,
((1 2 3) ((1 2) (1 3) (2 3)))
Another convenient representation is as a list of pairs, one for each node, where the first element of each pair is the node (or the label for the node) and the second element is a list of nodes (possibly empty) that the node is linked to. This is called the adjacency list represention as it includes for each node in the graph a list of the nodes that are adjacent to the node. Here is graph B using this representation,
{{{1,{2,3}},{2,{3}},{3,{}}}}
or in Lisp
((1 (2 3)) (2 (3)) (3 ()))
Note that we no longer need to keep around a separate list of all the nodes since each node is represented as a pair consisting of the label of the node along with a list of the labels of all of its adjacent nodes.
Graphs algorithms are just algorithms that operate on graphs and they
form a particularly important subarea of algorithms. It might be
interesting playing with a couple of algorithms as long as I don't get
carried away. It's often useful to determine whether or not there is a
path from one node to another in a graph, and algorithms that make
such determinations of actually find and return paths are called
graph-searching algorithms. Let's take a look at a Scheme version of
one the most basic (and important) such algorithms for determining if
a path exists in graph; it's called dfs_path? because it
answers the question whether or not a path exists using depth-first search
(DFS), a strategy for searching graphs that we'll explain
shortly. I'll just paste this function into a shell running Scheme.
> (define (dfs_path? graph queue goal max_steps)
(if (or (empty_queue? queue)
(= max_steps 0))
"no"
(if (= (first_node queue) goal)
"yes"
(dfs_path? graph
(append (get_links (first_node queue)
graph)
(remaining_nodes queue))
goal
(- max_steps 1)))))
And also some auxiliary functions whose definitions I hope you won't
look at because I don't want to explain them and they're not necessary
for you to understand in order to follow along - just interpret the
functions names as you would english, e.g., (first_node queue) means
return the first node off the queue and (remaining_nodes queue) means
return all the rest of the nodes on the queue (minus the first).
> (define (first_node queue) (car queue)) > (define (remaining_nodes queue) (cdr queue)) > (define (empty_queue? queue) (null? queue)) > (define (initialize_queue node) (list node)) > (define (get_links node graph) (cadr (assoc node graph)))
Here's a paraphrase of what function dfs_path? does. The
function is called with four arguments: a graph in adjacency-list
format, a queue of nodes to explore next (this queue initially
contains only the starting node), a destination (or goal) node, and an
integer indicating the maximum number of steps to take before calling
it quits; dfs_path? returns the string "yes"
if there is a path and the string "no" if it can't find
one.
The function operates as follows: If the queue is empty of you've used
up your allowance of steps, then you're done, return
"no". Otherwise, if the first node on the queue is the
goal node, then you're also done but this return "yes".
If neither of these conditions describe the current situation, then
max_steps must be greater than zero and there's at least
one more item on the queue, so call dfs_path? with the
same graph, a new queue which consists of all the nodes reachable by
following a link starting at the first node on the queue appended to
the list of all the nodes remaining on the queue (minus the first
node). The goal is the same in the recursive call but don't forget to
decrement the maximum number of steps left. Now let's see if it works.
Let's load in the adjacency-list representations for the three graphs
that we described above. In the following, we use the single quote,
"'", to tell Scheme to leave the expression immediately
following (delimited by the opposite balancing parenthesis) alone,
and, in particular, not treat it like an attempt to call a function. I
don't want to get into how Scheme is using lists as data structures,
since you should be able to understand what's going on here without
knowing the details. Just remember that "'" means to
treat the expression following the "'" literally, don't
try to evaluate it!
> (define A '((1 (2 3 4 5)) (2 (1)) (3 (1)) (4 (1)) (5 (1)))) > (define B '((1 (2 3)) (2 (3)) (3 ()))) > (define C '((1 (2 3)) (2 (1)) (3 (1 4 5)) (4 (3)) (5 (3))))
Is there a path from 1 to 3 in graph B? Let's give it a maximum of 10 steps to try to find an answer where each step corresponds to traversing a link in the graph.
> (dfs_path? B (initialize_queue 1) 3 10) "yes"
Sure enough. What about from 3 to 1?
> (dfs_path? B (initialize_queue 3) 1 10) "no"
Right again. What about from 1 to 5 in graph C?
> (dfs_path? C (initialize_queue 5) 1 10) "yes"
We're on a roll. DFS is mighty useful and you'll find it cropping up as part (often called a subroutine) in all sorts of algorithms. But DFS has some drawbacks and isn't the method of choice for searching all graphs. Time to draw another bunch of graphs.
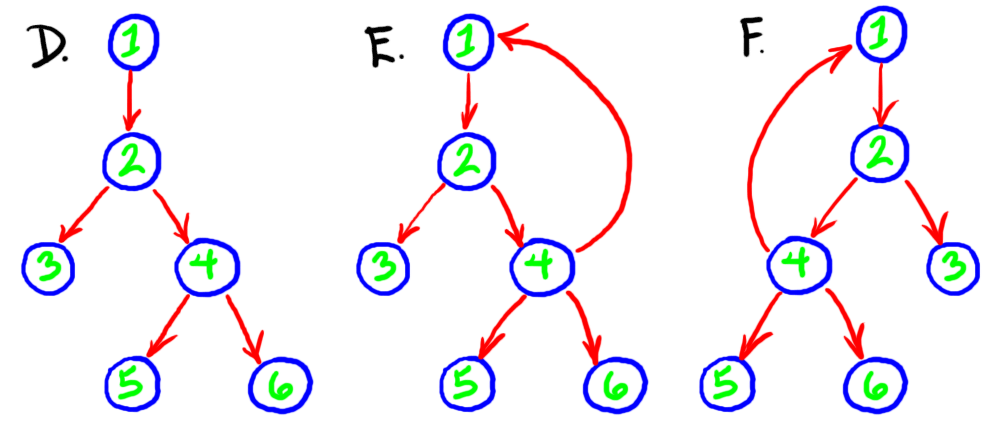
|
This drawing shows three graphs labeled D, E and F. D is a tree and in our original format (lists of nodes and links) it would be described as
{{1,2,3,4,5,6},{{1,2},{2,3},{2,4},{4,5},{4,6}}}
and in the adjacency-list format it would be described as
{{1,{2}},{2,{3,4}},{3,{}},{4,{5,6},{5,{}},{6,{}}}}.
E is just like D except that it has a cycle introduced by adding a link from 4 to 1. However, E is not tree nor is it a DAG (directed acyclic graph). It's a pretty common sort of graph however. E in the original format would looke like
{{1,2,3,4,5,6},{{1,2},{2,3},{2,4},{4,1},{4,5},{4,6}}}
and in the adjacency-list format
{{1,{2}},{2,{3,4}},{3,{}},{4,{1,5,6},{5,{}},{6,{}}}}
Finally, F is really the same as E except that I've drawn it as the mirror image of E and, in the adjacency-list format,
{{1,{2}},{2,{4,3}},{3,{}},{4,{1,5,6},{5,{}},{6,{}}}}
I've reversed the order in which 3 and 4 appear in the lists of nodes adjacent to 2; as we'll see, this turns out to make a crucial difference to DFS. We define these graphs in Scheme as follows.
> (define D '((1 (2)) (2 (3 4)) (3 ()) (4 (5 6)) (5 ()) (6 ()))) > (define E '((1 (2)) (2 (3 4)) (3 ()) (4 (1 5 6)) (5 ()) (6 ()))) > (define F '((1 (2)) (2 (4 3)) (3 ()) (4 (1 5 6)) (5 ()) (6 ())))
Let's see if there is a path from 1 to 4 in D.
> (dfs_path? D (initialize_queue 1) 4 10) "yes"
Yep. How about in E?
> (dfs_path? E (initialize_queue 1) 5 10) "no"
That can't be right! E has all of D's links plus one.
If there's a path from 1 to 5 in D there has to be a path in
E. We can modify dfs_path? just slightly so that
it will detect the path in E. The following function, called
bfs_path? for breadth-first
search (BFS), is defined the same as dfs_path?
with the exception of the order of the arguments in the call to
append. This small change results in BFS exploring the
graph by traversing links in the order in which they are loaded onto
the front of the queue. BFS looks at all of the nodes reached by
paths of length n before it looks looks at any of the nodes
that are only reachable by a path of length greater than n. DFS
searches by plunging deeper and deeper into the graph and hence the
name depth-first search. Also neither DFS nor BFS can tell when
they've visited a node in the graph previously and so starting from
node 1 both algorithms may return to 1 having followed the path
{1,{1,2},2,{2,4},{4,1},1} and then again having followed
{1,{1,2},2,{2,4},{4,1},1,{1,2},2,{2,4},{4,1},1} and so ad nauseam. We
can fix this however by just having both algorithms remember where
they've been. Or - more effective in some cases - just specify a
maximum number of steps, a resource limitation, as we've done here.
> (define (bfs_path? graph queue goal max_steps)
(if (or (empty_queue? queue)
(= max_steps 0))
"no"
(if (= (first_node queue) goal)
"yes"
(bfs_path? graph
(append (remaining_nodes queue)
(get_links (first_node queue)
graph))
goal
(- max_steps 1)))))
> (bfs_path? E (initialize_queue 1) 5 10) "yes"
If we were to remove the link from 4 to 1 in F, and ask to check for a path from 1 to 6, DFS would traverse the graph in depth-first order, 1, 2, 4, 5, 6, 3, and BFS would traverse the graph in breadth-first order, 1, 2, 4, 3, 5, 6. Try to think of cases in which DFS is the better choice (hint: consider graphs without cycles in which the goal is of some considerable distance from the starting node) and cases in which BFS is the better choice (hint: consider very large graphs in which the goal is not far from the starting node and each node has few children). Graphs are easy to sketch on paper and such sketches help a lot in settling your intuitions.
Often, in addition to knowing whether or not a path exists, you'd like
to see the paths, perhaps multiple paths if there are several. We
could modify dfs_path? and bfs_path? to
return paths but I thought I'd show you an alternative way of writing
a search algorithm in Scheme which illustrates another model of
computation.
In dfs_path? and bfs_path?, The recursive
call picked out one node to follow from the queue and put rest off
'til later. This method requires that all of the information regarding
the search has to be carried along in the arguments to the single
recursive call; it can be done but it requires a somewhat different
data structure to take care of the bookkeeping. Suppose that we could
generate a separate recursive call for each possible new link to
follow; then we could generate a recursive call with a new starting
node and include the path information as an additional argument. We
wouldn't even need to keep a queue around since we'd immediately spin
off a recursive call for each possible link out of the current node.
Scheme provides a nice abstraction for spinning off such recursive calls, or, more generally, applying a procedure multiple times to different sets of arguments. The abstraction involves what are called mapping operators and is part of a more general approach to programming called functional programming. Mapping operators have appeared in many different programming languages over the years and once you start using them it's hard to stop.
The special operator map takes a procedure that has some
number of formal parameters, n, and a set of n lists
each of length m for some arbitrary m. You can think of
map as applying the procedure not to each list of
arguments but to each cross section of all the lists. First the
procedure is applied to first cross section consisting of the first
item in the first list, the first argument of the second list, etc.,
then the procedure is applied to the second cross section consisting
of the second item in the first list, the second item in the second
list, etc., and so on until the procedure has been applied to all
m of the cross sections. In the expression (map + '(1 2
3) '(1 2 3)), the procedure + is applied as
follows, (+ 1 1), (+ 2 2), and (+ 3
3) and the results are returned as a list.
> (map + '(1 2 3) '(1 2 3)), (2 4 6)
The operator map will accept any procedure including one with
no name, the sort we can specify using lambda.
> (map (lambda (x y z) (- (* x y) z))
'(2 3)
'(3 4)
'(1 2))
(5 10)
Here's the definition of our procedure to search for and report as many paths as is possible. Note that we can no longer count all the steps taken in all of the recursive calls but we can do something which in many cases is even better, we can put a limit on how deep (the number of links traversed) we want any recursive call to search. This procesure explores the graph in breadth-first search and so inherits both the advantages and disadvantages of that method.
> (define (find_all_paths graph begin end path max_depth)
(if (= begin end)
(display_path (extend_path end path))
(if (> max_depth 0)
(map (lambda (new_begin)
(find_all_paths graph
new_begin
end
(extend_path begin path)
(- max_depth 1)))
(get_links begin graph))))
"done")
We'll also need some auxiliary functions which hide details that you
don't need to know in order to understand how
find_all_paths works.
> (define (display_path path) (printf "Path: ~A~N" (reverse path))) > (define (initialize_path) (list)) > (define (extend_path node path) (cons node path))
Let's give it a whirl on graph B.
> (find_all_paths B 1 3 (initialize_path) 10) Path: (1 2 3) Path: (1 3) "done"
It doesn't do any better than dfs_path? or
bfs_path? on graphs with cycles; in fact it can be down
right distracting.
> (find_all_paths E 1 3 (initialize_path) 24) Path: (1 2 3) Path: (1 2 4 1 2 3) Path: (1 2 4 1 2 4 1 2 3) Path: (1 2 4 1 2 4 1 2 4 1 2 3) Path: (1 2 4 1 2 4 1 2 4 1 2 4 1 2 3) Path: (1 2 4 1 2 4 1 2 4 1 2 4 1 2 4 1 2 3) Path: (1 2 4 1 2 4 1 2 4 1 2 4 1 2 4 1 2 4 1 2 3) Path: (1 2 4 1 2 4 1 2 4 1 2 4 1 2 4 1 2 4 1 2 4 1 2 3) "done"
But we could fix this by keeping an extra argument remembering all the places we've visited before.
It's getting late in the day and I seem to be wired and punchy at the same time. The wired part of me wants to press on. As soon as I started writing about the adjacency-list format, I resolved to say something about another representation for graphs called adjacency matrices. But before we can represent an adjacency matrix, it might be a good idea to learn how to represent a regular old matrix. An n by m matrix (and we'll confine our attention to two-dimensional matrices even though we can construct matrices of any dimension), is a table consisting of (n * m) numbers arranged in n rows and m columns; typically we represent such a matrix as n lists each of length m, so that a 2 by 3 matrix all of whose entries are 1 would look like {{1,1,1},{1,1,1}}.
To represent a graph with n nodes as an adjacency matrix, you associate the nodes in the graph with the integers 1 through n and construct an n by n matrix such that the (numeric) entry in the jth column of the ith row is 1 if there is a (directed) link in the graph from the ith node to the jth node and is 0 otherwise. Remembering that graph B looks like {{1,2,3},{{1,2},{1,3},{2,3}}}, it's adjacency matrix using the labels of the nodes as the associated numbers for the nodes would be the following:
{{0,1,1},
{0,0,1},
{0,0,0}}
Adjacency matrices are useful for representing small graphs and larger graphs that are dense in the sense that they have lots of links. A graph with n nodes can have as many as n2 links (for each pair of nodes there could be two directional links linking them together) and an adjacency matrix for a graph with n nodes has exactly n2 entries. Mathematica likes graphs represented as adjacency matrices just as I entered the matrix for B. Mathematica even has nifty functions for displaying matrices so they are easy to decipher.
In[1]:= TableForm[{{0,1,1},{0,0,1},{0,0,0}}]
Out[1]//TableForm= 0 1 1
0 0 1
0 0 0
Mathematica also has very convenient operators for combining matrices and vectors (one dimensional matrices) that are very useful in performing linear algebra, another branch of mathematics which is important in computer science and graphics and robotics in particular. I can use Mathematica's ability to handle symbolic operations to show you what it means to add two 2 by 2 matrices together
In[2]:= TableForm[{{a,b},{c,d}} + {{e,f},{g,h}}]
Out[2]//TableForm= a + e b + f
c + g d + h
and to take their inner product (also called the dot product, hence the dot represented by a period between the two matrices in the following invocation).
In[3]:= TableForm[{{a,b},{c,d}} . {{e,f},{g,h}}]
Out[3]//TableForm= a e + b g a f + b h
c e + d g c f + d h
You'll need a larger example to generalize, so I'll throw in the dot product of two 3 by 3 matrices.
In[4]:= TableForm[{{a,b,c},{c,d,e},{f,g,h}} . {{i,j,k},{l,m,o},{p,q,r}}]
Out[4]//TableForm= a i + b l + c p a j + b m + c q a k + b o + c r
c i + d l + e p c j + d m + e q c k + d o + e r
f i + g l + h p f j + g m + h q f k + g o + h r
Think about the interpration of the matrix that results from taking the dot product of an adjacency matrix with itself.
In[5]:= TableForm[{{a,b},{c,d}} . {{a,b},{c,d}} ]
Out[5]//TableForm= a a + b c a b + b d
a c + c d b c + d d
The entry in the jth column and ith row tells us if it's possible to get from i to j by traversing a path consisting of exactly one link. In general, if Mn is the matrix that we obtain by taking the dot product of an adjacency matrix with itself n times, then its entry in jth column and ith row tells us if it's possible to get from node i to node j by traversing a path consisting of exactly n links. If you add together all of the matrices M1, M2, ..., Mn you get a matrix such that the entry in jth column and ith row tells us how many different paths there are connecting node i to node j by traversing n or fewer links.
This might have been a somewhat misguided foray into linear algebra on my part but my point is that there are programming languages in which it's extremely easy to manipulate complex mathematical objects and perform operations on such objects very simply. You can call up the power of very powerful mathematics by only knowing the basic spells or formulas. And if you also understand the underlying mathematics then you can do truly amazing things.
This isn't all that amazing but here's the adjacency matrix for the graph labeled F in the last drawing.
In[6]:= F = {{0,1,0,0,0,0},
{0,0,1,1,0,0},
{0,0,0,0,0,0},
{1,0,0,0,1,1},
{0,0,0,0,0,0},
{0,0,0,0,0,0}}
In[7]:= TableForm[F]
Out[7]//TableForm= 0 1 0 0 0 0
0 0 1 1 0 0
0 0 0 0 0 0
1 0 0 0 1 1
0 0 0 0 0 0
0 0 0 0 0 0
And this matrix describes the numbers of paths connecting pairs of nodes of length four or less.
In[8]:= TableForm[F . F + F . F . F + F . F . F . F + F . F . F . F . F]
Out[8]//TableForm= 1 1 2 2 1 1
2 1 1 1 2 2
0 0 0 0 0 0
1 2 1 1 1 1
0 0 0 0 0 0
0 0 0 0 0 0
It's just another small example of the sort of powerful spells that you can cast by weaving together other spells that were written by lots of other very clever people. And it's a whole lot easier just understanding what the mathematics can do than it is writing the programs that perform the mathematical steps effortlessly for you. If you go on in computer science, you'll probably take course in graphics or robotics that has a short introduction to linear algebra and matrices.
I can't leave a discussion of graphs and trees without talking about one of the most obvious examples of trees involving computers: directory structures and files systems. Well, I could leave it out but I just thought of a simple way of illustrating trees by traversing directories and I can't help myself.
Directories in most file systems in most operating systems are
arranged as trees. Using a shell (a command line oriented interface)
or, more typically nowadays, some sort of a graphical interface, you
can create (mkdir) or remove (rmdir)
directories (also called folders), you can connect
(chdir) to a directory and list (ls) the
contents of a directory.
I have an alias (think of it as a little program) called
cd which I use instead of chdir and that in
addition to allowing me to connect to directories changes my prompt
every time I call it to help me keep track of where I am in the file
system (you can easily get lost if you don't keep track). I've listed
the program below; it first initializes my prompt and then defines
(alias is a little like define in Scheme)
cd as a program that first calls
chdir and then resets the prompt by referring to a
so-called "environment" variable $cwd which the system
uses to keep track of my current working directory.
set prompt = "$cwd % " alias cd 'chdir \!* ; set prompt = "$cwd % " '
This little program resides in a file with a lot of other useful little programs that are evaluated (define) and made available every time I start up a shell. I use it many times a day and hardly ever think about it until just now when I wondered how it would handle graphs with cycles - yes, you can create cycles in filesystems.
I'm going to invoke mkdir and create a tree just as in
graph D above. In the following ".." always refers to
the parent directory of the directory you're currently in. With the
exception of symbolic links (which we'll get to in a moment), each
directory has a unique parent directory. Here's how I create the tree
shown as graph D.
/u/tld % mkdir one /u/tld % cd one /u/tld/one % mkdir two /u/tld/one % cd two /u/tld/one/two % mkdir three four /u/tld/one/two % cd four /u/tld/one/two/four % mkdir five six /u/tld/one/two/four % ls five six /u/tld/one/two/four % cd .. /u/tld/one/two/ % ls four three /u/tld/one/two/ % cd four /u/tld/one/two/four % ls five six
Notice that each time I invoked cd it correctly redisplayed the
prompt indicating my location in the directory structure. Now I'm
going to create a symbolic link using the link command
(ln) with the soft (-s) qualifier (the only
option when linking one directory to another). The link command takes
as arguments the path to the destination directory (the destination of
the link) and a name for the link (which is said to symbolically
represent the destination). We'll set the name to be the same as the
name of the destination directory.
/u/tld/one/two/four % ln -s /u/tld/one one /u/tld/one/two/four % ls five one six
Now we have a graph with a cycle in it which is exactly the same as graph E above (and graph F since E and F are really just different drawings of the same graph). But now watch what happens as we walk around on the graph traversing edges.
/u/tld/one/two/four % cd one /u/tld/one/two/four/one % cd two /u/tld/one/two/four/one/two % cd four /u/tld/one/two/four/one/two/four % cd one /u/tld/one/two/four/one/two/four/one % cd two /u/tld/one/two/four/one/two/four/one/two % cd four /u/tld/one/two/four/one/two/four/one/two/four/ %
Just as find_all_paths was fooled by cycles in graph
E so my little cd program has become confused
thereby confusing me as well with its prompt that encodes my entire
cyclic traversal. Luckily another program called pwd
provides a more reasonable and cycle-free reporting of my working
directory as the shortest path from the root, "/", to my
working directory. It turns out "u" was another link that I
didn't even know about.
/u/tld/one/two/four/one/two/four/one/two/four/ % pwd /home/tld/one/two/four
That's it for trees and graphs. We also used a couple of other data structures that I didn't comment on. Certainly we used lists everywhere with different syntax, e.g., (1 2 3) and {1,2,3}.
We also used a very useful data structure called an association list which can be enormously useful. Association lists are called hashes in Perl for the way in which they are implemented in Perl, namely, using another very useful data structure called a hash table.
> (assoc 4 '((1 (2)) (2 (4 3)) (3 ()) (4 (1 5 6)) (5 ()) (6 ()))) (4 (1 5 6))
Recall earlier I said we could use association lists like telephone books to recall phone numbers from names. Imagine what we'd use the following variation on an association list for:
> (define rolo '((fred ((phone 401-863-5715) (dorm foster)))
(sally ((phone 401-863-5708) (dorm grant)))))
But that's more than enough for today. Jo's telling me that she's going to go to the beach without me if I don't come right this minute.