Lecture 25: Summary and Outlook
» Lecture video (Brown ID required)
» Post-Lecture Quiz (due 11:59pm Monday, May 11)
In this lecture, we will pull together some of the key themes of the course and recap topics that we talked about throughout the semester.
Computer Organization
At the start of the course, we looked at two very simple concepts: memory, which is organized as an array of bytes; and the processor's ability to execute a sequence of machine instructions stored in memory.
All the advanced concepts we looked at in the course are build over simple hardware primitives like memory bytes and the processor instruction sequence. Some examples are listed in the picture below.
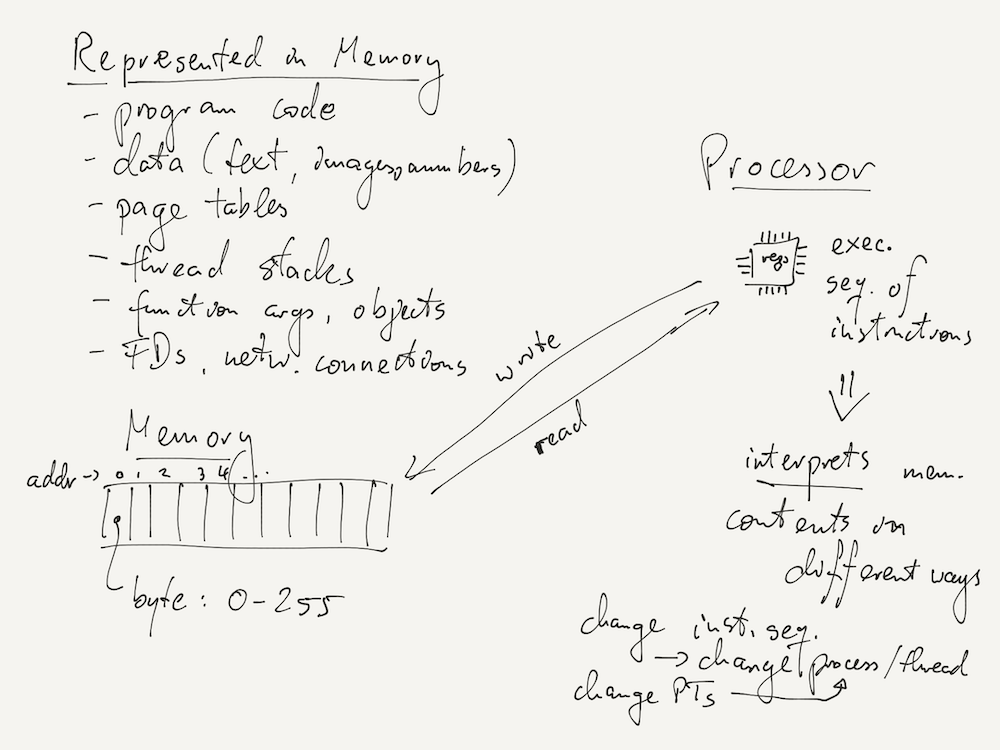
Abstractions
The ability of build higher-level abstractions from lower-level primitives (which may themselves be abstractions) is one of the reasons why computer systems have become as successful as they have.
The notion of a process is an example of an abstraction: a process really consists of memory regions (code, globals, heap, stack), kernel state (process descriptor, FD array), and virtual memory structures (page tables). It can encompass multiple threads, which are themselves abstractions!
Below, we list a few more examples of abstractions we have encountered in the course, alongside the primitives they are created from.

Virtualization
We extensively looked at virtual memory as an example of the idea of virtualization, where a part of a computer system (here, a process) accesses a virtual resource (here, virtual memory addresses) that is actually implemented in terms of other physical resources (here, physical memory). Importantly, the system component does not realize that it's using a virtualized resource rather than the real thing.
This is a powerful idea that allows further nesting of virtualization, such as virtualizing the physical memory seen by the OS kernel in order to run virtual machines (VMs) on a host machine. Your course VM works this way!
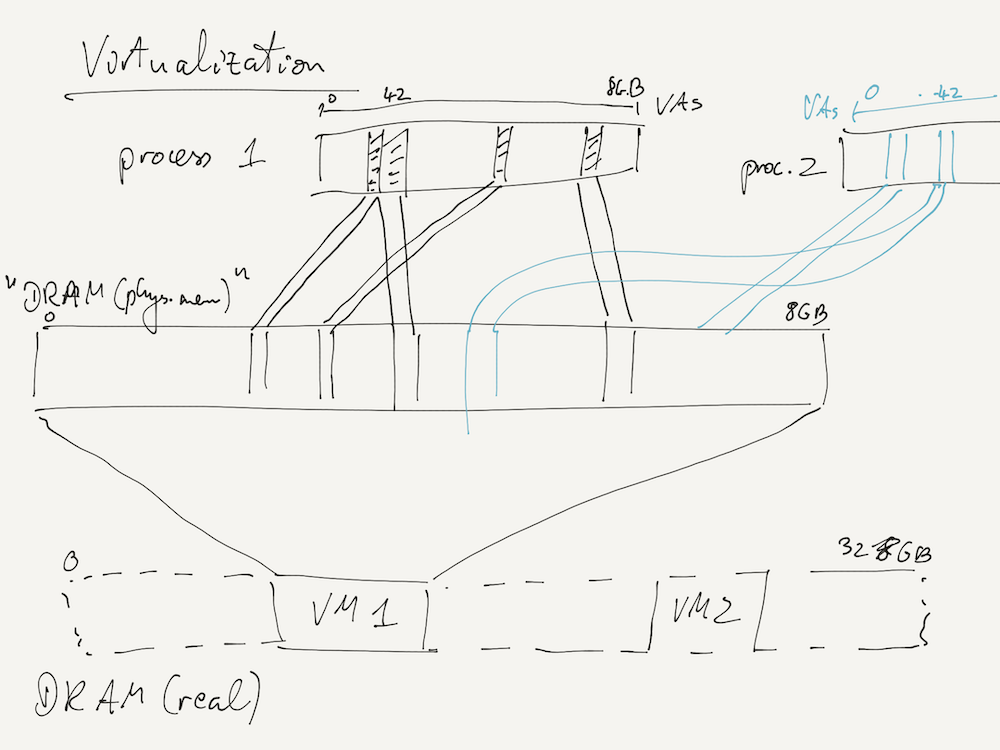
But we can also virtualize other resources, such as processor time:
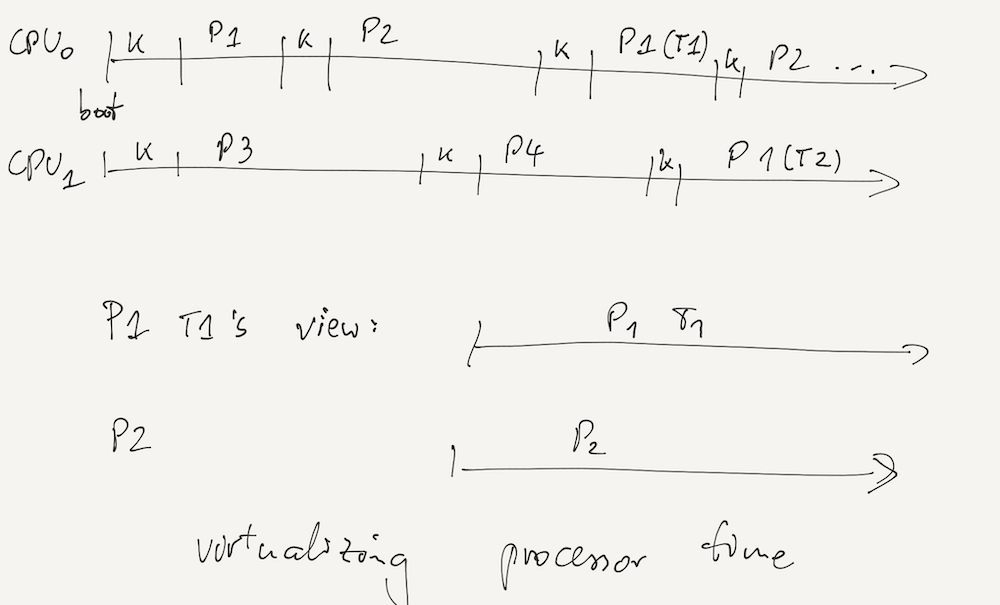
HW-SW Interface
Much of CS 131 has been about issues at the interface of hardware (e.g., organization of memory, caches) and software (in the OS kernel and in user-space programs).
Some of the concepts and abstractions we learned about in the course are purely software concepts – they can be implemented by writing either kernel or user-space code alone. Other concepts fundamentally require hardware support, and others yet achieve large performance benefits from hardware primitives that support them.
Here are some examples:
| Software-only concepts |
|
| Concepts that fundamentally require HW support |
|
| Concepts that benefit from HW support (in terms of performance) |
|
Concurrency
We saw that concurrency is both a blessing and a curse. It increases efficiency, as the processor can do work while other threads or processes are blocked (for I/O, or waiting on a lock), and it allows for parallelism on multi-processor computers. But at the same time, concurrency substantially increases the complexity of our programs, as we need to think about synchronizing access to memory between different threads. In addition, a whole new set of bugs can now occur – race conditions, deadlocks, etc.
One good way to think about concurrency is to avoid it as long as it's not strictly necessary! Good reasons for using concurrency might be if your application must handle many independent requests, or when the workload can benefit from parallel speedup.
How much speedup can an application achieve? This depends on various factors, but the fundamental limit is defined by Amdahl's Law, which computes the maximum speedup as a function of p, the fraction of the program's execution that can be parallelized. For example, if p = 0.95, the maximum speedup is 20×; for a p = 0.05, it is only 1.11×.
In practice, one big contributor to the non-parallelizable part of the program (1 - p in Amdahl's Law) is the code that runs in critical sections protected by locks: by definition, a mutex ensures that the protected code can never be executed by more than one thread at a time.

Distributed Systems
A distributed system is fundamentally also a concurrency system, as it involves computers whose processors execute instructions independently and in parallel. But distributed systems add extra complexity on top of concurrency, because we must now consider situations where some of the computers involved have failed.
Like with concurrency, a good rule of thumb is that you typically only want to use a distributed system if you cannot get away with using a centralized (single-computer) one. Reasons for this might include fault tolerance, or a workload that exceeds the resources available on one computer.
Another important aspect of distributed system design that we didn't go deeply into in the course is the threat model
of a distributed system. For example, the distributed key-value store you're building in Project 5 assumes that all participants
are trusted: any client or server can invoke a Leave RPC and unsubscribe a server, for instance. Many distributed
systems running in closed environments like a corporate datacenter are able to make this assumption, but those exposed to the wild
internet cannot. Instead, distributed systems in which anyone can participate ("open" systems) must assume that some
participants might be malicious. An example of a system that can handle arbitrarily malicious participants is the Bitcoin
cryptocurrency and its blockchain.
EOF
This is the end of CS 131! If you're thinking of courses to take next, here are some courses that dive deeper into the concepts we learned about in this course.
- CSCI 1270 looks at databases, which are an important kind of structured storage system. You'll learn more about transactions and concurrency control too.
- CSCI 1380 dives deeper into distributed systems and how to design systems that can survive even complex failures.
- CSCI 1650 looks the security issues that exist in low-level systems (such as the buffer overflow from Lab 3), and at how malicious agents can hack into computer systems.
- CSCI 1660 also covers applied computer security, but looks at slightly higher level threats as well as some policy questions about secure system design.
- CSCI 1670 (and its lab variant, CSCI 1690) are all about OS kernel programming, with a more advanced and complete OS than WeensyOS.
- CSCI 1680 covers computer networking, and looks in much more detail at how networks transmit data between computers, as well as how the global internet really works.
- CSCI 1760 is about multiprocessor synchronization, which involves both the theory and low-level details behind synchronization objects like mutexes and condition variables.
- CSCI 2390 is a research seminar that looks at how we can build systems (particularly distributed systems) that better preserve users' data privacy and data ownership rights.
