Lecture 18: Race Conditions and Synchronization
» Lecture video (Brown ID required)
» Lecture code
» Post-Lecture Quiz (due 11:59pm Monday, April 13)
Race conditions
Recall that in the last lecture we showed that updating shared memory variables in concurrent threads requires synchronization, otherwise some update may get lost because of the interleaving of operations in different threads.
Here's an example, in which two threads are trying to both increment an integer x
in memory that is originally set to the value 7. Recall that each thread needs to (i)
load the value from memory; (ii) increment it; and (iii) write the incremented
value back to memory. (In the actual processor, these steps may happen in microcode instructions,
but we're showing them as x86-64 assembly instructions operating on a register %tmp
here.)

This interleaving is bad! It loses one of the increments, and ends up with x = 8
even though x has been incremented twice. The reason for this problem is that T2's
movl (&x), %tmp instruction runs before T1's increment (addl), so
the processor running T2 stores (in its cache and registers) an outdated value of x
and the increments that value. Both threads write back a value of x = 8 to memory.
To see that this is indeed a race condition, where the outcome only depends on how the executions of T1 and T2 happen relative to each other, consider the below schedule, which happens to run the operations without interleaving between the threads:
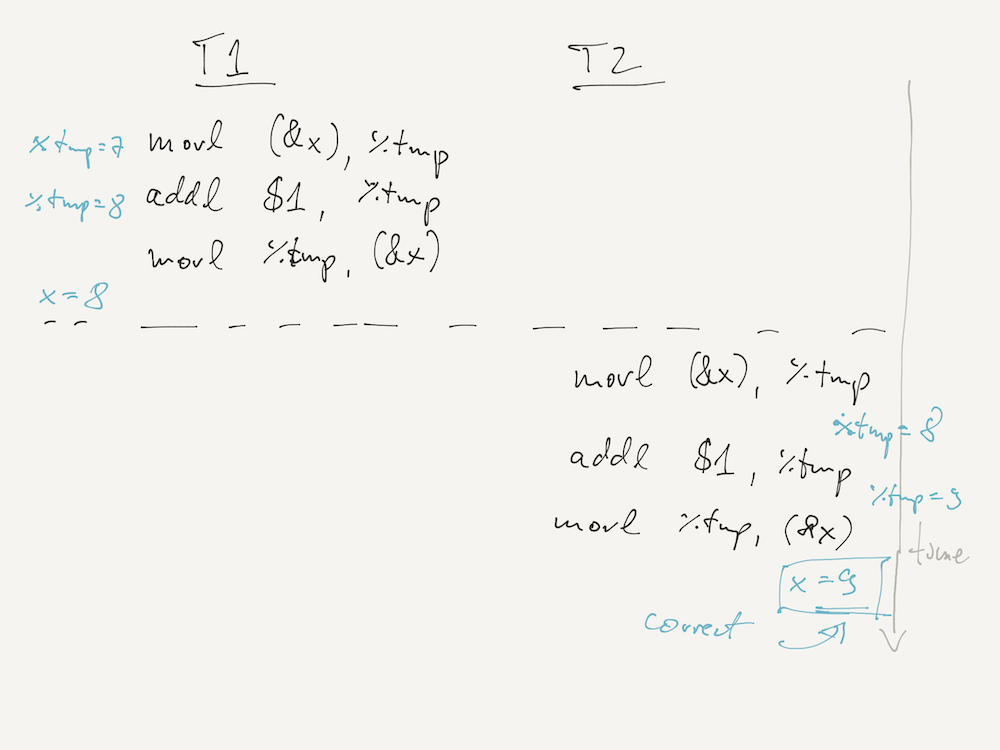
In this execution, we get the correct value of x = 9 (7 incremented twice)
because the T1's increment completes and writes x = 8 back to memory before T2
reads the value of x.
Having the outcome of our program depend on how its threads' execution randomly interleaves is terrible, so we better synchronize the threads to restrict executions to "good" interleavings.
Synchronization Objects
Synchronized updates for primitive types (like integers) can be achieved by using the C++
std::atomic template library, which automatically translates the addl
instruction used to perform the update into a lock-prefixed instruction that behaves
atomically.
C++'s std::atomic library is powerful (and also great progress in standardization
of atomic operations), but it works only on integers that are word-sized or smaller. To synchronize
more complex objects in memory or perform more complex synchronization tasks, we need abstractions
called synchronization objects.
Synchronization objects are types whose methods can be used to achieve synchronization and
atomicity on normal (non-std::atomic-wrapped) objects. Synchronization objects provide
various abstract properties that simplify programming with multi-threaded access to shared data.
The most common synchronization object is called a "mutex", which provides the mutual
exclusion property.
Mutexes
Mutual exclusion means that at most one thread accesses the shared data at a time.
In our multi-threaded incr-basic.cc example from the last lecture, the code does
not work because more than one thread can access the shared variable at a time. The code would
behave correctly if the mutual exclusion policy is enforced. We can use a mutex
object to enforce mutual exclusion (incr-mutex.cc). In this example, it has the same
effect as wrapping *x in a std::atomic template:
std::mutex mutex;
void threadfunc(unsigned* x) {
for (int i = 0; i != 10000000; ++i) {
mutex.lock();
*x += 1;
mutex.unlock();
}
}
The mutex (a kind of lock data structure) has an internal state (denoted by state),
which can be either locked or unlocked. The semantics of a mutex object is as follows:
- Upon initialization,
state = unlocked. mutex::lock()method: waits untilstatebecomesunlocked, and then atomically setsstate = locked. Note the two steps shall complete in one atomic operation.mutex::unlock()method: asserts thatstate == locked, then setsstate = unlocked.
The mutual exclusion policy is enforced in the code region between the
lock() and unlock() invocations. We call this region the critical
section.
A mutex ensures that only one thread can be active in a critical section at a time. In other
words, the mutex enforces a thread interleaving like the one shown in the picture below, where
T1 waits on the mutex m while T2 runs the critical section, and then T1 runs the
critical section after it acquires the mutex once T2 releases it via m.unlock().

How do atomic operations come into the mutex? Consider the implementation of
m.lock(): there must be an operation that allows the thread calling
lock() to set the lock's state to locked without any chance of another
thread grabbing the lock in between. The way we ensure that is with an atomic operation: in
particular, a "compare-and-swap" operation (CMPXCHG in x86-64) atomically reads the
lock state and, if it's unlocked, sets it to locked.
Implementing a mutex with a single bit and
cmpxchgExtra material: not examinable in 2020.
Internally, a mutex can be implemented using an atomic counter, or indeed using a single atomic bit! Using a single bit requires some special atomic machine instructions.
A busy-waiting mutex (also called a spin lock) can be implemented as follows:
struct mutex { std::atomicspinlock; void lock() { while (spinlock.swap(1) == 1) {} } void unlock() { spinlock.store(0); } }; The
spinlock.swap()method is an atomic swap method, which in one atomic step stores the specified value to the atomicspinlockvariable and returns the old value of the variable.It works because
lock()will not return unlessspinlockpreviously contains value 0 (which means unlocked). In that case it will atomically stores value 1 (which means locked) tospinlockand prevents otherlock()calls from returning, hence ensuring mutual exclusion. While it spin-waits, it simply swapsspinlock's old value 1 with 1, effectly leaving the lock untouched. Please take a moment to appreciate how this simple construct correctly implements mutual exclusion.x86-64 provides this atomic swap functionality via the
lock xchgassembly instruction. We have shown that it is all we need to implement a mutex with just one bit. x86-64 provides a more powerful atomic instruction that further opens the possibility of what can be done atomically in modern processors. The instruction is called a compare-exchange, orlock cmpxchg. It is powerful enough to implement atomic swap, add, subtract, multiplication, square root, and many other things you can think of.The behavior of the instruction is defined as follows:
// Everything in one atomic step int compare_exchange(int* object, int expected, int desired) { if (*object == expected) { *object = desired; return expected; } else { return *object; } }This instruction is also accessible as the
this->compare_exchange_strong()member method for C++std::atomictype objects. Instead of returning an old value, it returns a boolean indicating whether the exchange was successful.
Example: bounded buffer
A bounded buffer is a common abstraction in computer systems: memory is finite, so we need to cap the amount of space we use for our buffers. However, we may not know in advance how much data we need to store in the buffer, so we may need to allow some data to be consumed out of the buffer before we can insert more.
This idea is efficiently implemented using a cyclic buffer, in which writes (and reads) wrap around the end to continue at the beginning. A cyclic buffer is efficient because it never requires any data (bytes) to be moved within the buffer unless those bytes are read or written.
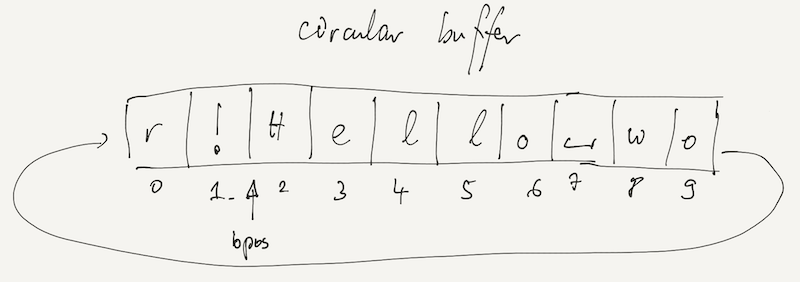
In the example above, the cyclic buffer contains the data !Hello wor.
The bounded buffer we look at here is a synchronized object that supports the following operations:
read(buf, n): reads up tonchars from the bounded buffer tobuf;write(buf, n): writes up tonchars into the bounded buffer frombuf.
Bounded buffers are the abstraction used to implement pipes in the kernel. In our example, though, we're looking at a bounded buffer in user-space and between threads (you can think of Go's channels as such bounded buffers, for example).
Summary
Today, we took another look at examples of race conditions, which lead to undefined behavior in multi-threaded programs. We then learned about mutexes, a kind of synchronization object that allows us to ensure that only one thread can operate on a shared datastructure at a time. Mutexes ensure that only one thread can execute in a critical section at the time – implementing "mutual exclusion" between threads.
We saw the API of a mutex and how to use it. Importantly, it's the responsibility of the application
programmer to ensure that lock() and unlock() get called on the right mutexes in the
right places.
Finally, we started looking at the example of a bounded buffer, which we'll use to explore mutexes and other synchronization objects.