Lecture 20: Networking, Scalability
S1: Networking system calls
A networking program uses a set of system calls to send and receive
information over the network. The first and foremost system call is called
socket(). It creates a "network socket", which is the key
endpoint abstraction for network connections in today's operating systems.
socket(): Analogous topipe(), it creates a networking socket and returns a file descriptor to the socket.
The returned file descriptor is non-connected -- it has just been initialized
but it is neither connected to the network nor backed up by any files or
pipes. You can think of socket() as merely reserving kernel state for a
future network connection.
Recall how we connect two processes using pipes. There is a parent process
which is responsible for setting everything up (calling pipe(), fork(),
dup2(), close(), etc.) before the child process gets to run a new program
by calling execvp(). This approach clearly doesn't work here, because there
is no equivalent of such "parent process" when it comes to completely
different computers trying to communicate with one another. Therefore a
connection must be set up using a different process with different
abstractions.
In network connections, we introduce another pair of abstractions: a client and a server.
The client is the active endpoint of a connection: It actively creates a connection to a specified server. Example: When you visit
google.com, your browser functions as a client. It knows which server to connect to!The server is the passive endpoint of a connection: It waits to accept connections from what are usually unspecified clients. Example:
google.comservers serve all clients visiting Google.
Client- and server-sides use different networking system calls.
Client-side system call -- connect
connect(fd, addr, len) -> int: Establish a connection.fd: socket file descriptor returned bysocket()addrandlen: C struct containing server address information (including port) and length of the struct- Returns 0 on success and a negative value on failure.
Server-side system calls
On the server side things get a bit more complicated. There are 3 system calls:
bind(fd, ...) -> int: Picks a port and associate it with the socketfd.listen(fd) -> int: Set the state of socketfdto indicate that it can accept incoming connections.accept(fd) -> cfd: Wait for a client connection, and returns a new socket file descriptorcfdafter establishing a new incoming connection from the client.cfdcorrespond to the active connection with the client.
The server is not ready to accept incoming connections until after calling
listen(). It means that before the server calls listen() all incoming
connection requests from the clients will fail.
Among all these system calls mentioned above, only connect() and accept()
involves actual communication over the network, all other calls simply
manipulate local state. So only connect() and accept() system calls
can block.
Differences between sockets and pipes
One interesting distinction between pipes are sockets is that pipes are one way, but sockets are two-way: one can only read from the read end of the pipe and write to the write end of the pipe, but one are free to both read and write from a socket. Unlike regular file descriptors for files opened in Read/Write mode, writing to a socket sends data to the network, and reading from the same socket will receive data from the network. Sockets hence represents a two-way connection between the client and the server, they only need to establish one connect to communicate back and forth.
Connections
A connection is an abstraction built on top of raw network packets. It presents an illusion of a reliable data stream between two endpoints of the connection. Connections are set up in phases, again by sending packets.
Does all networking use a connection abstraction?
No, it does not. Here we are describing the Transmission Control Protocol (TCP), which is the most widely used network protocol on the internet. TCP is connection-based. There are other networking protocols that do not use the notion of a connection and deal with packets directly. Google "User Datagram Protocol" or simply "UDP" for more information.
A connection is established by what is known as a three-way handshake process. The client initiates the connection request using a network packet, and then the server and the client exchange one round of acknowledgment packets to establish the connection. This process is illustrated below.
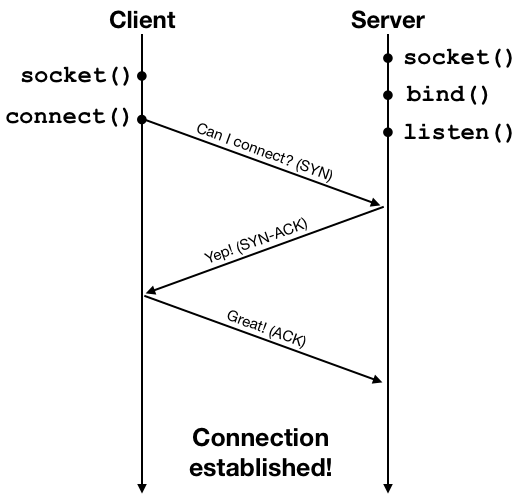
Once the connection is established, the client and the server can exchange data using the connection. The connection provides an abstraction of a reliable data stream, but at a lower level data are still sent in packets. The networking protocol also performs congestion control: the client would send some data, wait for an acknowledgment from the server, and then send more data, and wait for another acknowledgment. The acknowledgment packets are used by the protocol as indicators of the condition of the network. The the network suffers from high packet loss rate or high delay due to heavy traffic, the protocol will lower the rate at which data are sent to alleviate congestion. The following diagram shows an example of the packet exchange between the client and the server using HTTP over an established connection.
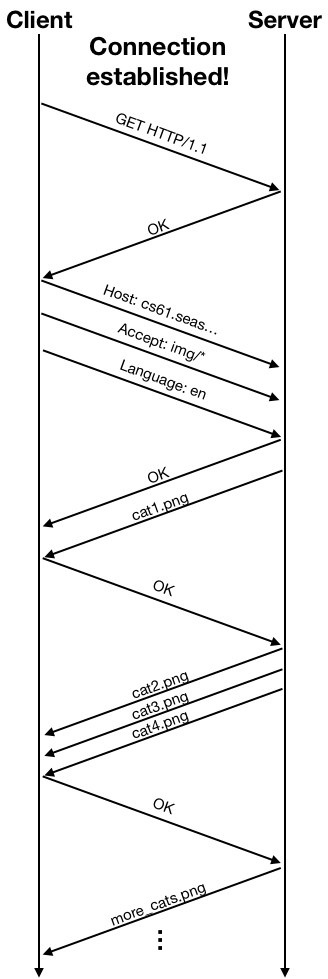
S2: Key-Value Stores
Many modern websites rely on distributed storage systems.
S3: Scaling a server
Summary
Today, we learned the sequence of system calls that computers acting in the client and server roles use to establish network connections. We also saw a time sequence diagram for the TCP three-way-handshake, and understood how data gets sent between clients and servers. We also looked at WeensyDB, a simple networked key-value store. WeensyDB is similar to real-world key-value stores such as memcached, Redis, or RocksDB. However, the first version we considered lacked any support for concurrent clients, something we rectified using threads. In addition, the original WeensyDB didn't contain any synchronization, a problem that we solved by adding bucket-granularity locks that server threads must take before the modify the hash table datastructure.
Finally, we discussed scalability – i.e., the ability for a server to accept more and more load – in terms of the overhead of adding more threads, and in terms of the impact of locking granularity on scalability.
