Lecture 18: Synchronization (II)
» Lecture code
» Post-Lecture Quiz (due 11:59pm Wednesday, March 31)
S1: Bounded Buffer, continued
Recall from last time that a bounded buffer is a data structure often used in computer systems for efficient temporary storage of data. Pipes, for example, are backed by a bounded buffer in the kernel.
In the following, we will use a bounded buffer that is accessed by multiple threads as an example for a data structure that requires synchronization. In the examples, we use two threads: one writer thread and one reader thread. The writer (also called "producer") writes data into the bounded buffer, and the reader (also called "consumer") reads data from it.
The buffer can hold up to CAP characters, where CAP is the capacity
of the buffer. The API of the bounded buffer is specified as follows:
read(buf, sz):- Reads up to
szcharacters from the bounded buffer intobuf - Removes characters read from the bounded buffer
- If the bounded buffer is empty, it should block until it becomes nonempty or closed
- Returns the number of characters read
- Reads up to
write(buf, sz):- Writes up to
szcharacters, frombufto the end of bounded buffer - Writes up to bounded buffer capacity
CAPcharacters - If bounded buffer becomes full, it should block until buffer becomes nonfull
- Returns the number of characters written
- Writes up to
Example: Assuming we have a bounded buffer object bbuf with CAP=4.
bbuf.write("ABCDE", 5); // returns 4
bbuf.read(buf, 3); // returns 3 ("ABC")
bbuf.read(buf, 3); // returns 1 ("D")
bbuf.read(buf, 3); // blocks
The bounded buffer preserves two important properties:
- Every character written can be read exactly once
- The order in which characters are read is the same order in which they are written
Each bounded buffer operation should also be atomic, just like read() and
write() system calls.
Unsynchronized buffer
Let's first look at a bounded buffer implementation bbuffer-basic.cc, which does
not perform any synchronization.
struct bbuffer {
static constexpr size_t bcapacity = 128;
char bbuf_[bcapacity];
size_t bpos_ = 0;
size_t blen_ = 0;
bool write_closed_ = false;
ssize_t read(char* buf, size_t sz);
ssize_t write(const char* buf, size_t sz);
void shutdown_write();
};
ssize_t bbuffer::write(const char* buf, size_t sz) {
assert(!this->write_closed_);
size_t pos = 0;
while (pos < sz && this->blen_ < bcapacity) {
size_t bindex = (this->bpos_ + this->blen_) % bcapacity;
size_t bspace = std::min(bcapacity - bindex, bcapacity - this->blen_);
size_t n = std::min(sz - pos, bspace);
memcpy(&this->bbuf_[bindex], &buf[pos], n);
this->blen_ += n;
pos += n;
}
if (pos == 0 && sz > 0) {
return -1; // try again
} else {
return pos;
}
}
ssize_t bbuffer::read(char* buf, size_t sz) {
size_t pos = 0;
while (pos < sz && this->blen_ > 0) {
size_t bspace = std::min(this->blen_, bcapacity - this->bpos_);
size_t n = std::min(sz - pos, bspace);
memcpy(&buf[pos], &this->bbuf_[this->bpos_], n);
this->bpos_ = (this->bpos_ + n) % bcapacity;
this->blen_ -= n;
pos += n;
}
if (pos == 0 && sz > 0 && !this->write_closed_) {
return -1; // try again
} else {
return pos;
}
}
This implements a circular buffer, because reads and writes logically wrap
around at the end of the buffer. Every time we read a character out of the buffer, we
increment bpos_, which is the index of the next character to be read in the
buffer. Whenever we write to the buffer, we increment blen_, which is the
number of bytes currently stored in the buffer. To make the buffer circular, we perform
all index arithmetic modulo the total capacity of the buffer.
When there is just one thread accessing the buffer, it works perfectly fine.
But does it work when multiple threads are using the buffer at the same time?
In our test program in bbuffer-basic.cc, we have one reader thread reading
from the buffer and a second writer thread writing to the buffer. We would
expect everything written to the buffer by the writer thread to show up
exactly as it was written once read out by the reader thread.
In particular, the example writes the string Hello world! one million
times over, so we would expect to read one million strings, composed of 13 million total
characters.
When we try this, it does not work! The reason is that there is no synchronization over
the internal state of the bounded buffer.
bbuffer::read() and bbuffer::write() both modify internal state of
the bbuffer object (most critically bpos_ and blen_),
and such accesses require synchronization to work correctly in a multi-threaded environment –
recall the fundamental rule of sychronization, which says that if state is accessed by
multiple threads and at least one thread may write to the state, synchronization is required.
One way to fix the bounded buffer is to turn the function bodies of the read()
and write() methods into critical sections using a mutex.
Correctly Synchronized buffer
To figure out what state we need to protect through synchronization, let's look at the definition of the bounded buffer:
struct bbuffer {
static constexpr size_t bcapacity = 128;
char bbuf_[bcapacity];
size_t bpos_ = 0;
size_t blen_ = 0;
bool write_closed_ = false;
...
};Recall the basic rule of synchronization from Lecture 17: if two or more threads can concurrently access an object, and at least one of the accesses is a write, a race condition can occur and synchronization is required.
The bounded buffer's internal state, bbuf_, bpos_, blen_, and
write_closed_ are both modified and read by read() and write() methods.
Local variables defined within these methods are not shared. We need to synchronize on shared variables
(internal state of the buffer), but not on local variables.
A correct version of a synchronized bounded buffer via a mutex is in
bbuffer-mutex.cc. Key differences from the unsynchronized version are
highlighted below:
struct bbuffer {
...
std::mutex mutex_;
...
};
ssize_t bbuffer::write(const char* buf, size_t sz) {
this->mutex_.lock();
...
this->mutex_.unlock();
if (pos == 0 && sz > 0) {
return -1; // try again
} else {
return pos;
}
}
ssize_t bbuffer::read(char* buf, size_t sz) {
this->mutex_.lock();
...
if (pos == 0 && sz > 0 && !this->write_closed_) {
this->mutex_.unlock();
return -1; // try again
} else {
this->mutex_.unlock();
return pos;
}
}
This correctly implements a synchronized bounded buffer. Simply wrapping accesses to shared state within critical sections using a mutex is the easiest and probably also the most common way to make complex in-memory objects synchronized (or "thread-safe").
Using a mutex associated with the bounded buffer object allows threads to operate on different bounded buffers in parallel (but not on the same bounded buffer). Using a single, global mutex, by contrast, would synchronize all threads operating on any bounded buffer in the program (there could be many!), an example of extremely coarse-grained synchronization Coarse-grained synchronization is correct, but it also limits concurrency.
The bounded_buffer::write() method in bbuffer-mutex.cc is implemented
with mutex synchronization. Note that we added a definition of a mutex to the
bbuffer struct definition, and we are only accessing the internal state of the
buffer within the region between this->mutex_.lock() and this->mutex_.unlock(),
which the the time period when the thread locks the mutex.
How do we identify critical sections?
One question you may wonder about is how we figured out where to put the lock()
and unlock() calls for the mutex, and even what mutex we should use in the first
place. For the latter question, the answer is that the association between mutex and shared state is
purely in the developer's (your!) head.
Association between mutexes and the state they protect
The association between the mutex and the state it protects is rather arbitrary. These mutexes are also called "advisory locks", as their association with the state they protect are not enforced in any way by the compiler, and must be taken care of by the programmer. Their effectiveness solely relies on the program following protocols associating the mutex with the protected state. In other words, if a mutex is not used correctly, there is no guarantee that the underlying state is being properly protected.
The general rule for where to put the boundaries of critical sections in the code (the lock()
and unlock() calls is that they must be placed such that all accesses to shared state are
inside the critical section. In the following, we will consider a few locking strategies that violate this
rule in subtle ways.
Consider the following code, which move the mutex lock()/unlock() pair
to inside the while loop. We still have just one lock() and one unlock()
in our code. Is it correct?
ssize_t bbuffer::write(const char* buf, size_t sz) {
assert(!this->write_closed_);
size_t pos = 0;
while (pos < sz && this->blen_ < bcapacity) {
this->mutex_.lock();
size_t bindex = (this->bpos_ + this->blen_) % bcapacity;
this->bbuf_[bindex] = buf[pos];
++this->blen_;
++pos;
this->mutex_.unlock();
}
...
}
The code is incorrect because this->blen_ is not protected by the mutex, but it should be.
What about the following code -- is it correct?
ssize_t bbuffer::write(const char* buf, size_t sz) {
this->mutex_.lock();
assert(!this->write_closed_);
size_t pos = 0;
while (pos < sz && this->blen_ < bcapacity) {
this->mutex_.lock();
size_t bindex = (this->bpos_ + this->blen_) % bcapacity;
this->bbuf_[bindex] = buf[pos];
++this->blen_;
++pos;
this->mutex_.unlock();
}
...
}
It's also wrong! Upon entering the while loop for the first time, the mutex
is already locked, and we are trying to lock it again. Trying to lock a mutex
multiple times in the same thread causes the second lock attempt to block
indefinitely.
So what if we do this:
ssize_t bbuffer::write(const char* buf, size_t sz) {
this->mutex_.lock();
assert(!this->write_closed_);
size_t pos = 0;
while (pos < sz && this->blen_ < bcapacity) {
this->mutex_.unlock();
this->mutex_.lock();
size_t bindex = (this->bpos_ + this->blen_) % bcapacity;
this->bbuf_[bindex] = buf[pos];
++this->blen_;
++pos;
this->mutex_.unlock();
this->mutex_.lock();
}
...
}
Now everything is protected, right? NO! This is also incorrect and in many ways much worse than the two previous cases.
Although this->blen_ is now seemingly protected by the mutex, it is being
protected within a different region from the region where the rest of the
buffer state (bbuf_, bpos_) is protected. Further more, the mutex
is unlocked at the end of every iteration of the while loop. This means
that when two threads call the write() method concurrently, the lock can
bounce between the two threads and the characters written by the threads
can be interleaved, violating the atomicity requirement of the write()
method.
Back to our original plan!
With the original placement of lock() and unlock(), wrapping
the whole function body, we have correctly synchronized the buffer.
Running bbuffer-mutex
provides correct output strings as well as producing the right number of total output
characters (checkable via ./bbuffer-mutex | wc -c), 13,000,000.
The only part of the bounded buffer specification that we have not yet implemented is
the part that specifies that the buffer ought to block for writing when full and
for reading when empty. Instead, our bounded buffer simply returns -1 in these
situations. The caller needs to check and retry, but this is very inefficient: threads
might spin for a long time, repeatedly calling read() or write()
only to find that it still returns -1.
To solve this problem, we need another synchronization object: a condition variable.
S2: Condition Variables
C++ Mutex Patterns
Before we talk about condition variables, let's look at a C++ pattern that both makes working with mutexes easier and forms the basis for the standard library condition variable API.
It is very common that we write some synchronized function where we need to lock the mutex first, do some work, and then unlock the mutex before the function returns. Doing this repeatedly can be tedious. Also, if the function can return at multiple points, it is possible to forget a unlock statement before a return, resulting errors. C++ has a pattern to help us deal with these problems and simplify programming: a scoped lock.
We use scoped locks to simplify programming of the bounded buffer in
bbuffer-scoped.cc. The write() method now looks like the following:
ssize_t bbuffer::write(const char* buf, size_t sz) {
std::unique_lock guard(this->mutex_);
assert(!this->write_closed_);
size_t pos = 0;
while (pos < sz && this->blen_ < bcapacity) {
size_t bindex = (this->bpos_ + this->blen_) % bcapacity;
this->bbuf_[bindex] = buf[pos];
++this->blen_;
++pos;
}
...
}
Note that in the first line of the function body we declared a
std::unique_lock object, which is a scoped lock that locks the mutex for the
scope of the function. Upon initialization of the std::unique_lock object,
the mutex is automatically locked, and when this object goes out of scope, the
mutex is automatically unlocked. These special scoped lock objects lock and
unlock mutexes in their constructors and destructors (a special C++ method on classes that
gets invoked before an object of that class is destroyed) to achieve this effect.
This design pattern is also called Resource Acquisition is Initialization (or RAII), and is a common pattern in software engineering in general. The use of RAII simplify coding and also avoids certain programming errors.
Condition Variables
A condition variable supports the following operations:
wait(std::unique_lock& lock): In one atomic step, it unlocks the lock, blocks until another thread callsnotify_all(). It also relocks the lock before returning (waking up).notify_all(): Wakes up all threads blocked by callingwait().
Logically, the writer to the bounded buffer should block when the buffer
becomes full, and should unblock when the buffer becomes nonfull again. Let's
create a condition variable, called nonfull_, in the bounded buffer, just
under the mutex. Note that we conveniently named the condition variable after
the condition under which the function should unblock. It will make code
easier to read later on. The write() method implements blocking is in
bbuffer-cond.cc. It looks like the following:
ssize_t bbuffer::write(const char* buf, size_t sz) {
std::unique_lock guard(this->mutex_);
assert(!this->write_closed_);
while (this->blen_ == bcapacity) { // #1
this->nonfull_.wait(guard);
}
size_t pos = 0;
while (pos < sz && this->blen_ < bcapacity) {
size_t bindex = (this->bpos_ + this->blen_) % bcapacity;
this->bbuf_[bindex] = buf[pos];
++this->blen_;
++pos;
}
...
The new code at #1 implements blocking until the condition is met. This is a
pattern when using condition variables: the condition variable's wait()
function is almost always called in a while loop, and the loop tests the
condition in which the function must block.
On the other hand, notify_all() should be called whenever some changes we
made might turn the unblocking condition true. In our scenario, this means we
must call notify_all() in the read() method, which takes characters out of
the buffer and can potentially unblock the writer, as shown in the inserted
code #2 below:
ssize_t bbuffer::read(char* buf, size_t sz) {
std::unique_lock guard(this->mutex_);
...
while (pos < sz && this->blen_ > 0) {
buf[pos] = this->bbuf_[this->bpos_];
this->bpos_ = (this->bpos_ + 1) % bcapacity;
--this->blen_;
++pos;
}
if (pos > 0) { // #2
this->nonfull_.notify_all();
}
With condition variables, our bounded buffer program runs significantly more efficiently:
instead of making millions of calls to read and write, it now makes
about a 100k read calls and about 1M write calls, since the threads
are blocked while the buffer is full (writes) or empty (reads).
S3: Deadlock
Locking is difficult not only because we need to make sure that we include all accesses to shared state in our critical sections, but also because it's possible to get it wrong in ways that cause our programs to get stuck indefinitely.
To explain this, let's consider a new example program. passtheball.cc contains the basic,
unsychronized code for a game in which players pass a ball between them. Each player runs in a separate
thread, and the example program has three players (P0 to P2). At the start, P0
has a ball, indicated by its has_ball member variable. The players then pass the ball by
invoking pass(), which changes the ball state (has_ball) of the target player
as well as their own ball state to move the ball.
Clearly, has_ball is shared state that gets written and read here. Consequently, it's not
surprising that passtheball.cc (which lacks synchronization) both quickly ends up going awry
when run (it either loses the ball or duplicates it because the threads can get descheduled between changing
the two ball states) and generates a bunch of race condition warnings when compiled with thread sanitizers
enabled (make TSAN=1).
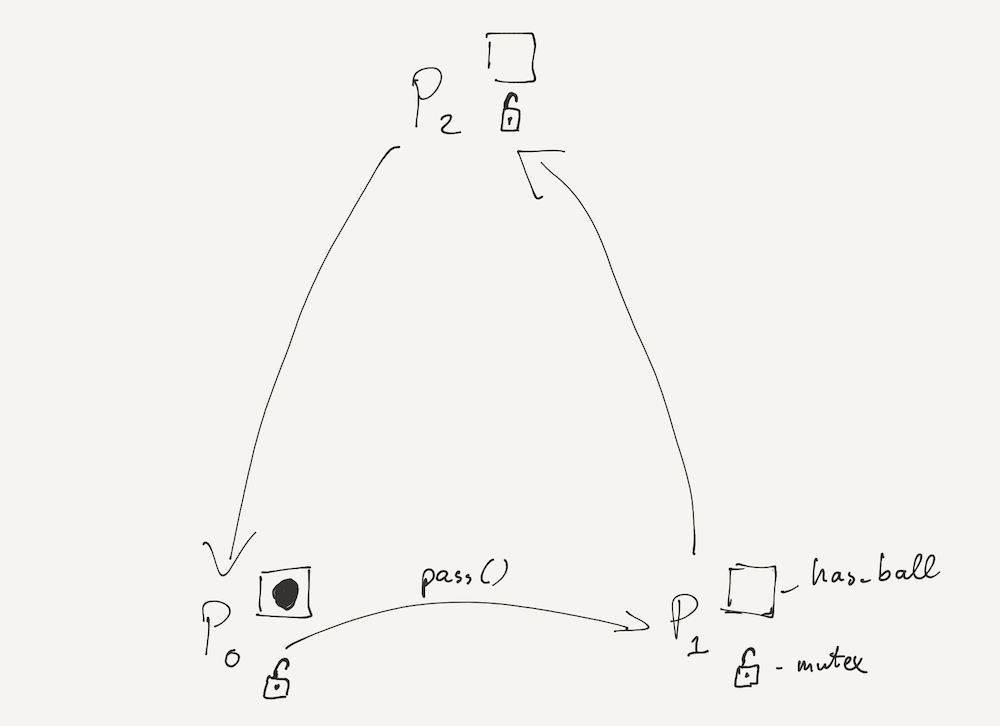
passtheball-mutex.cc implements a synchronized version of the ball game
using mutexes. This implementation works correctly for the setting with a
single ball.
Now consider a modified version of this game, where players generate a random number to decide whether to pass the ball to their left or to their right (each with a 50% likelihood), and where we additionally introduce a second ball to the game.
When we run this code (passtheball-deadlock), it quickly gets stuck in a setting similar to the
one shown below. (The specific players involved may differ if you run the code, but the overall situation will
be the same.) P0 has a ball and is trying to pass it to P2, who also has a ball and is
concurrently trying to pass that ball to P0.
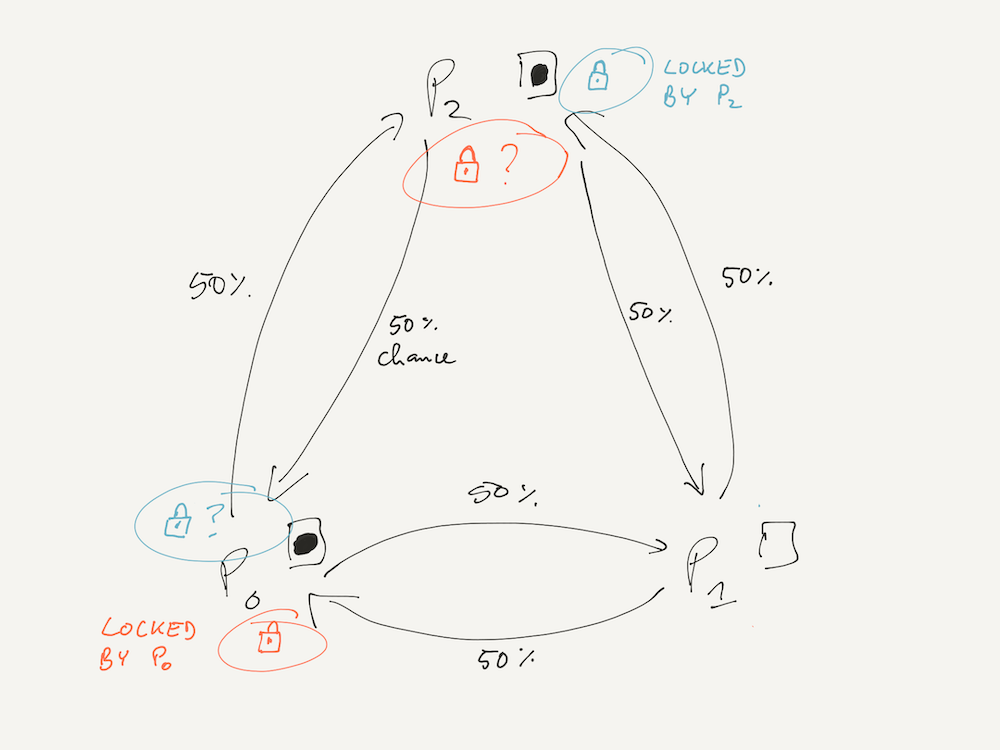
Why does the code get stuck? Consider what happens in player_threadfunc() and pass():
- First, in
player_threadfunc(), the passing player locks its own ball state mutex (theunique_lockoverme->m). - Second, in
pass(), the passing player attempts to lock the ball state mutex of the target player (target->m.lock()).
target.m is already locked in both target players! Thus,
P0's thread will block and wait for the mutex on P2's ball state to become available.
But this will never happen, because P2's thread (which would need to release its me->m
lock to unblock P0's thread) is itself stuck waiting for a mutex that P0's thread has
locked.
No thread can ever make progress again, and the program becomes deadlocked.
Summary
Today, we looked into how to correctly synchronize a bounded buffer data structure with concurrent reader and writer threads. This required identifying the shared state that is not constant (read-only) associated with the bounded buffer, and making sure that each access to that state – both reads and writes – happens in a critical section, i.e., while a mutex is locked. This ensures that only one thread can execute this code at a time.
For performance, we prefer to make our critical sections as small as possible: the more
code in a critical section, the less parallelism we can get as only one thread can run in a
critical section. But we must make the critical section large enough to make the program
correct: it needs to contain all accesses to shared state within the operation we're trying
to synchronize (read() and write() in the case of the bounded
buffer).
Condition variables are another type of synchronization object that make it possible to implement
blocking of threads until a condition is satisfied (e.g., there is space in a bounded buffer
again). This improves efficiency of the bounded buffer program, as threads no longer spin; for some
other programs that require threads to wait, condition variables are actually required for correctness.
To wait, a thread calls wait() on the condition variable while holding a mutex lock. If the
condition does not hold, the mutex is released and the thread is blocked. Any waiting threads for a
condition variable are unblocked by a call to notify_all (or notify_one) from
another thread.
Finally, we saw an example of deadlock, which occurs when a thread blocks on acquiring a lock that is already held and never given up. Deadlock can occur with two threads that try to mutually take locks on resources that they have already locked. With C++ standard library mutexes, deadlock can also happen in other situations, such as when a thread is trying to take a lock it already holds.
