Lecture 15: Inter-Process Communication
» Lecture code
» Post-Lecture Quiz (due 11:59pm Monday, March 22)
Inter-Process Communication
Processes, though operating in isolated virtual address spaces, often need to communicate with each other in controlled ways. This is what Inter-Process Communication (IPC) is about. We already saw simple examples of IPC in the form of process exit statuses last time. In addition, Linux provides other mechanisms for processes to communicate: they can read and write files on disk, or they can rely on a more efficient, in-memory streaming transport in the form of pipes.
The notion of multiple processes working together to achieve a goal shows up in many ways in your everday computing. Two key examples are:
- Combining multiple shell commands via the
|("pipe") character: you may have seen chains of commands such aswc -l *.cc | sort -n, which counts the lines in all C++ source files in the current directory (wc -l *.cc) and then sorts the result by the number of lines using another command (sort -n). The pipe symbol here tells the shell to set up the processes with a pipe between them and for the first command to send its output to the pipe, from where the second command reads it. - Speeding up operations that interact with a large data set or many requests by splitting the work across processes that communicate results back to a parent process. This works especially well if you're using a computer with multiple processors, where in the best case N processes achieve N× the speed or throughput of a single process.
S1: Pipe Setup
A pipe provides a unidirectional, in-order transport mechanism. A process can use a pipe
to send data to itself, but a pipe is most powerful when combined with fork(), which allows it
to be used for communication across parent and child processes.
pipe() system call. Each pipe has two user-facing file descriptors,
corresponding to the read end and the write end of the pipe. File descriptors are
identifiers that the kernel uses to keep track of open resources (such as files) used by user-space processes.
User-space processes refer to these resources using integer file descriptor (FD) numbers; in the kernel, the
FD numbers index into a FD table maintained for each process.
The signature of the pipe() system call looks like this:
int pipe(int pfd[2]);
It is the responsibility of the user-space process to allocate memory for the pfd array. The
memory can be in a global variable, on the stack, or on the heap. This follows a general principle with Linux
system calls: the memory that the kernel writes data or information to must be allocated by user-space
and a valid pointer passed into the kernel.
A successful call to pipe() creates 2 file descriptors, placed in array pfd:
pfd[0]: read end of the pipepfd[1]: write end of the pipe
How do I remember which end is which?
The default file descriptors available to each process (
stdin,stdout, andstderr) provide a useful mnemonic to remember which end of a pipe is the read end:
- 0 is the FD number for
stdin, 1 is the FD number ofstdout- Programs read from stdin and write to stdout
pfd[0]is the read end (input end),pfd[1]is the write end (output end)
Data written to pfd[1] can be read from pfd[0].
Can a pipe be used bi-directionally?
The read end of the pipe can't be written, and the write end of the pipe can't be read. Attempting to read/write to the wrong end of the pipe will result in a system call error (the
read()orwrite()call will return -1).
Let's look at a concrete example in selfpipe.cc:
int main() {
int pfd[2];
int r = pipe(pfd);
assert(r == 0);
char wbuf[BUFSIZ];
sprintf(wbuf, "Hello from pid %d\n", getpid());
ssize_t n = write(pfd[1], wbuf, strlen(wbuf));
assert(n == (ssize_t) strlen(wbuf));
char rbuf[BUFSIZ];
n = read(pfd[0], rbuf, BUFSIZ);
assert(n >= 0);
rbuf[n] = 0;
assert(strcmp(wbuf, rbuf) == 0);
printf("Wrote %s", wbuf);
printf("Read %s", rbuf);
}
This code (which doesn't contain fork()) creates a pipe, writes to it, and reads from
it within a single process. We create a pipe, write to the pipe, and then read from the pipe. Finally, we
assert that the string we get out of the pipe is the same string we wrote into the pipe.
You might wonder where the data goes after the write() system call completes, but before
the read() from the pipe is invoked. The data doesn't live in the process's address space! It
actually goes into a memory buffer located in the kernel address space.
The read() system call blocks when reading from a stream file descriptor that doesn't
have any data to be read. Pipe file descriptors are stream file descriptors, so reading from an empty pipe
will block (meaning the kernel won't schedule the reading process until there is data available in the
pipe). write() calls to a pipe block when the buffer is full (because reader the not consuming
quickly enough). A read() from a pipe returns EOF if all write ends of a pipe is
closed.
So far we've only seen pipe functioning within the same process. Since the pipe lives in the kernel, it
can also be used to pass data between processes. We can combine the fork() system
call (which copies the parent process's open file descriptors to the child process) with pipes to establish
a communication channel across processes.
S2: Pipes across processes
Since the pipe lives in the kernel, it can also be used to pass data between processes. Let's take a
look at childpipe.cc as an example:
int main() {
int pipefd[2];
int r = pipe(pipefd);
assert(r == 0);
pid_t p1 = fork();
assert(p1 >= 0);
if (p1 == 0) {
// child process
const char* message = "Hello, mama!";
printf("[child: %d] sending message\n", getpid());
ssize_t nw = write(pipefd[1], message, strlen(message));
assert(nw == (ssize_t) strlen(message));
exit(0);
}
char buf[BUFSIZ];
if (read(pipefd[0], buf, BUFSIZ) > 0) {
printf("[parent: %d] I got a message! It was “%s”\n", getpid(), buf);
}
close(pipefd[0]);
close(pipefd[1]);
}
Here, we use fork() to create a child process, but note that before forking we created a
pipe first! The fork() duplicates the two pipe file descriptors in the child, but note that the
pipe itself is not duplicated (because the pipe doesn't live in the process's address space). The child then
writes a message to the pipe, and the same message can be read from the parent. Interprocess communication!
Note that in the scenario above we have four file descriptors associated with the pipe, because
fork() duplicates the file descriptors corresponding to two ends of a pipe. The pipe in this case
has two read ends and two write ends. The animated picture below (courtesy of Eddie Kohler) illustrates the
situation in terms of the FD table maintained for both processes:
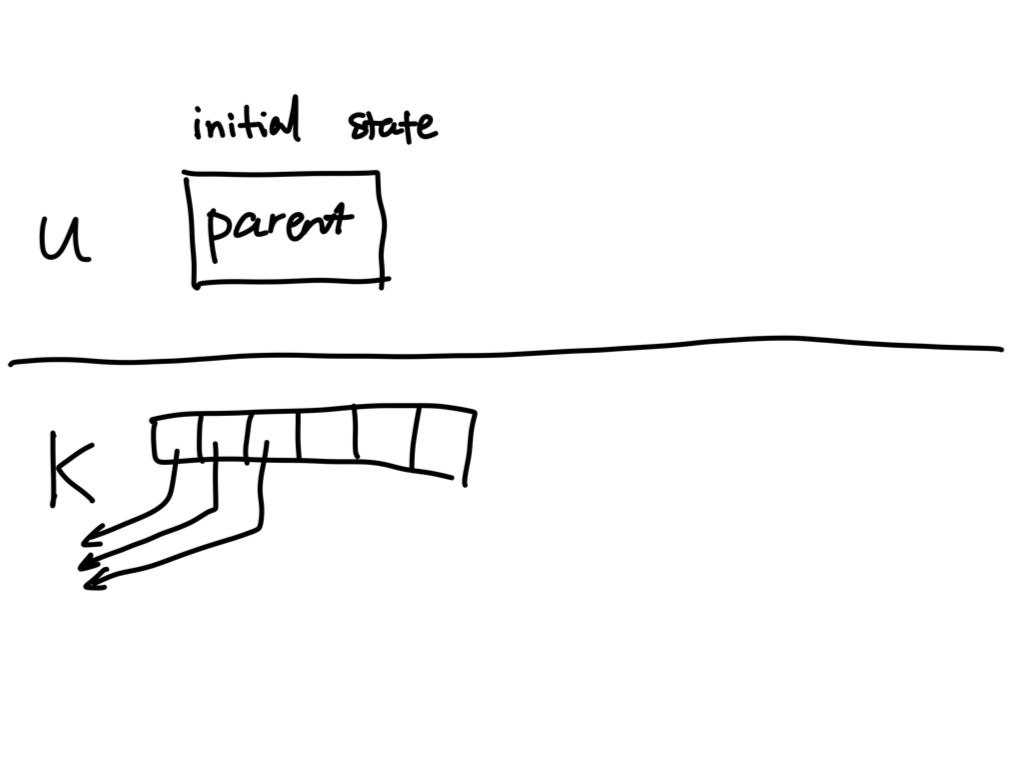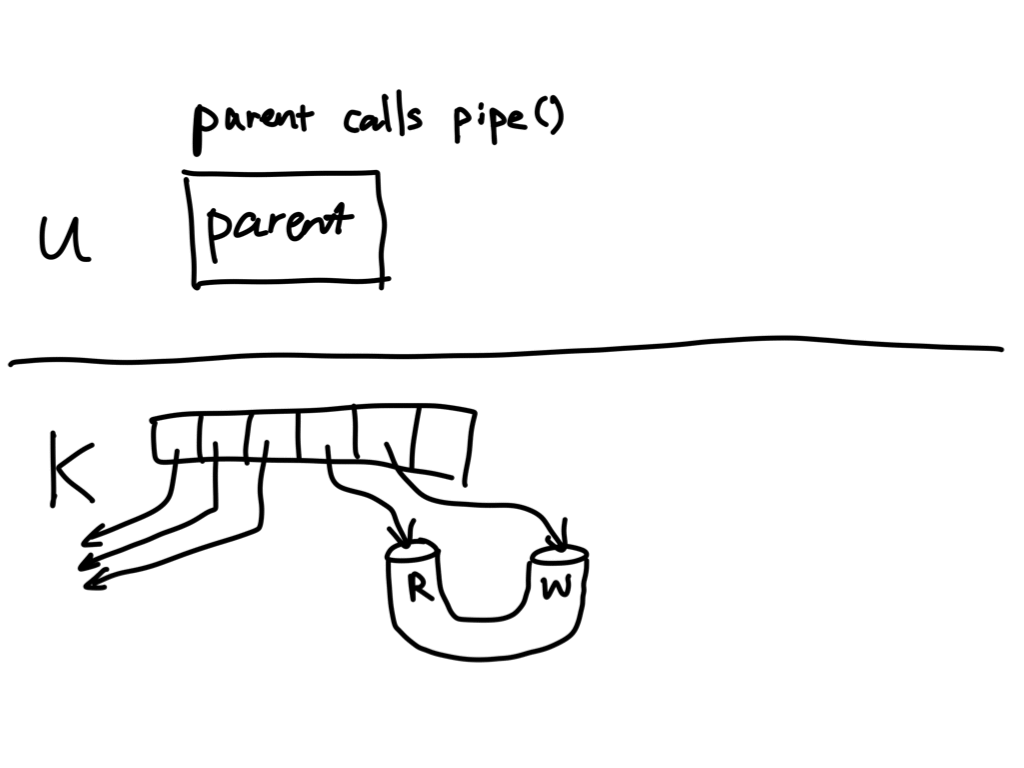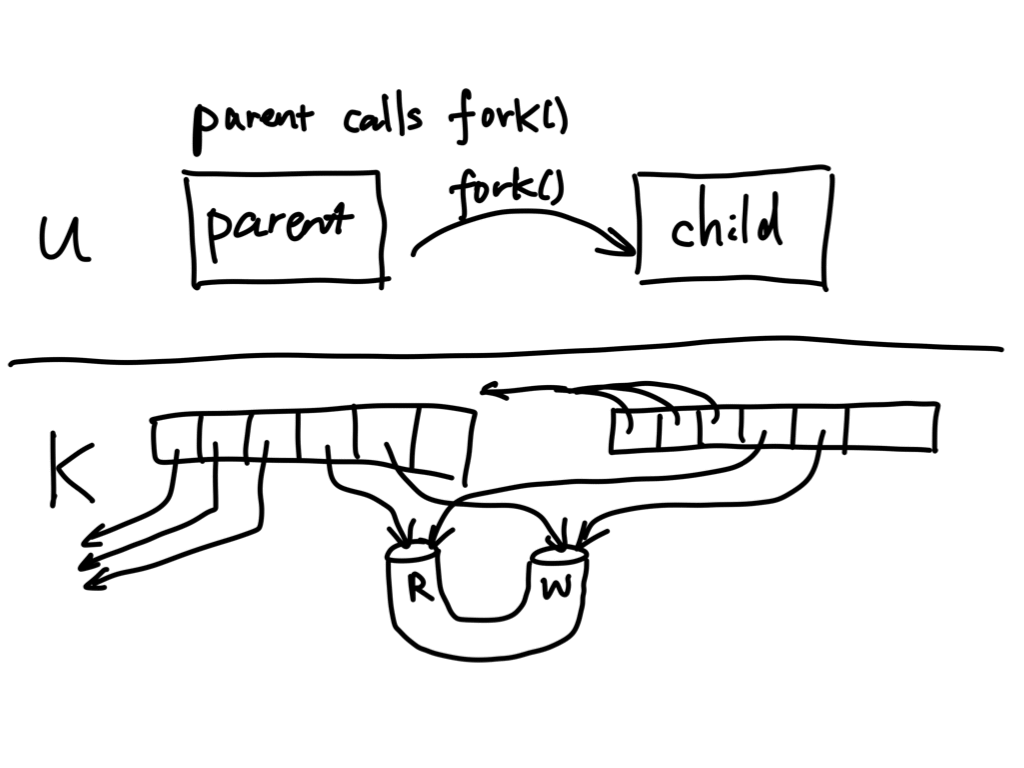
Note that there continues to exist a write end of the pipe in the parent, and a read end in the child that never get closed! This can lead to weird hangs when using pipes, so a common idiom is to close the pipe ends that a process does not need immediately after forking. In the example, we need to close the write end in the parent and the read end in the child:
...
pid_t p1 = fork();
assert(p1 >= 0);
if (p1 == 0) {
... // child code
}
close(pipefd[1]); // close the write end in the parent
char buf[BUFSIZ];
if (read(pipefd[0], buf, BUFSIZ) > 0) {
...
Are pipes always 1:1 between a parent and a child process?
Pipes are quite powerful! You can also create a pipe between two child processes (think about how you would use
fork(),pipe(), andclose()to achieve this!), and a pipe can actually have multiple active read ends and write ends. A use case for a pipe with multiple active write ends is a multiple-producer, single-consumer (MPSC) setup – this is useful, e.g., when a process listens for messages from a set of other processes. Likewise, a pipe with multiple active read ends supports a single-producer, multiple consumer (SPMC) use case, where multiple readers compete for messages (e.g., work units) sent by a writer. Multiple producer, multiple consumer (MPMC) is also possible, but rarely used in practice because it becomes difficult to coordinate the readers and writers.
S3: Concurrency vs. Parallelism
Modern day computers usually have multiple processors (CPUs) built in. This allows them to run instructions from two processes simultaneously: each processor has its own set of registers and L1 cache, and all processors can access memory (RAM).
But before ca. 2005, few computers had multiple processors. Yet, computers could still run multiple programs using the idea of "time-sharing", where the processor will switch between running processes in turn, entering the kernel in between different user-space processes.
This notion, which involves multiple processes being active on the computer at the same time is called multiprocessing, and constitutes a form of concurrency. Concurrency means that multiple processes are active concurrently. (As we will see shortly, this also generalizes to running multiple concurrent threads on the same processor.)
The notion of parallelism is subtly different from concurrency: it refers to the actual execution of instructions from multiple processes (or threads) truly at the same time on different processors. In order to achieve parallelism, you need multiple processors that are active at the same time. But a parallel execution is also concurrent, since multiple processes (or threads) are still active concurrently.
Pipes and IPC more generally allow processes in isolated address spaces to communicate in restricted and kernel-mediated ways. But sometimes you want multiple concurrent execution units to work on truly shared memory (e.g., because the data is large and forking would be expensive; or because you're implementing an application with truly shared data across parallel requests). For this purpose, operating systems provide threads, which execute concurrently like processes, but share the single virtual address space of their parent process.
Summary
Today, we dove deeper into how processes can interact via pipes, which are kernel-mediated shared-memory buffers that processes access via file descriptors. We saw that combining pipes with forking allows processes to establish communication channels with (and even between) their children. This is a very powerful abstraction that allows us to chain shell commands, and to achieve parallelism using multiple processes on multi-processor computers.
We also covered the difference in definition between the terms "concurrency" and "parallelism", which refer to the notion of multiple active processes or threads (concurrency) and truly parallel-in-time execution on different processors (parallelism).
