Generating Descriptive Keywords from Images
CSCI-1290 Final Project by Rebecca Mason

The goal of this final project is to generate text keywords for images using local features and topic modeling.
Automatic image annotation is a popular area of study in computational vision and photography. There are many reasons why work like this is useful. For example, keyword-based indexing is an effective technique for image retrieval, and automatically generated image captions could help make web content more accessable to blind persons.
This final project is particularly inspired by two recent papers. The first, "Automatic Attribute Discovery and Characterization from Noisy Web Data" (Berg et al. 2010), learns attribute vocabularies without hand-labeled training data by studying many pairs of images and descriptions mined from online shopping websites. The second, "How Many Words is a Picture Worth? Automatic Caption Generation for News Images" (Feng & Lapata, 2010), uses local image features to infer likely keywords given an unseen image and related news article.
The Attribute Discovery Dataset from Berg, Berg, and Shih (2010) is used for experiments. This dataset consists of image and description pairs for 4 broad categories of shopping data (womens' shoes, bags, and earrings, and mens' ties). We develop our model using the womens' shoes category, and use 9991 image and text pairs for training.

For example, the above image of a boot has this description: "Keep it simple with these classic short leather boots. Full interior side zip closure. Pointy toe and 3" stacked heel. Leather lining and leather sole."
The generative model for images and descriptions is the same as the model used in Feng & Lapata (2010). Latent Dirichlet allocation (Blei et al. 2003) is used to model the generation of image and text features. We assume a fixed vocabulary of text words and image features, and define a set of distributions ("topics") over that vocabulary. For example, a topic that gives higher probability to image features of treaded soles might also give higher probabilty to text words like "athletic" and "outdoors", but less probability to "wedding".
Each image and text description pair in the training data is modeled as a single document. The documents each have their own distribution of vocabulary topics. Image and text features of the document are generated by first randomly selecting a topic to generate from, and then randomly selecting a feature from the vocabulary distribution of that topic. The image below shoes this generative process as a graphical model:
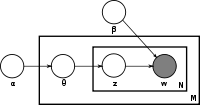
Gibbs sampling is used to learn the topics and their specific vocabulary distributions from the training data. Then, for a new image, we can infer the topics that it was generated from from its distribution of image features. Once we find those topics, we guess the text for the image by generating likely words that were generated from those topics. This is slightly different from the Feng & Lapata, because we only have information from the image to infer topic proportions, while they utilize both the news image's features and the full text of the accompanying news article.
The model trains on specific parts of the images rather than the entire image. This way, we can represent an image as a bag of local features, similar to how the text descriptions are represented as a bag of words.
SIFT descriptors are used to find local image features. SIFT descriptors are reasonably tolerant to changes in illumination, scale, rotation, translation, and small changes in viewpoint, which is helpful when working with somewhat noisy web data. The images are converted to black and white before finding the SIFT descriptors.

In order to get a discrete set of image features, we cluster all of the SIFT descriptors from the training set using k-means (K = 75). For testing images, we find the SIFT descriptors and assign them to the cluster that they are closest to. In the example shown above, the different colors represent different clusters that the descriptors are from.
Although the images in this dataset seem reletively not noisy (close up images of shoes, against white background), there is still a lot of variation that can make matching features difficult. Some of the images show both shoes instead of just one, the shoes are shown from a variety of angles, and it can be harder to match some features on different colors of shoes.
The words that are included in the topic model are adjectives (JJ, JJR, JJS), improper nouns (NN, NNS), and gerunds (VBG). Words that do not appear at least 10 times in the training data are not considered. Word order is also not considered; only the histogram of word counts is needed.
Here are some test images and the keywords generated for the baseline model:
|
evening, clogs, pump, inch, bow, modern, design, high, style, stylish |
 |
clogs, genuine, boot, waterproof, dry, fashion, rain, boots, shaft, collar |
 |
durability, sneaker, stitching, flat, accents, tongue, traction, sporty, casual, collar |
These examples are typical of the strengths and weaknesses that we tend to see. The first two examples have mostly accurate description words, such as "evening" and "pump" for the first image, and "boot" and "waterproof" for the second. The bow on the first shoe is accurately described, even though it is on an angle and kind of hard to see. However, some of the words are not very good. Neither of the shoes are "clogs" and words like "fashion" and "style" are not very descriptive.
The third image is an example of how using local image features can sometimes be completely wrong. The third shoe is a high heel with some sporty features, like the laces and the stripes across the front. Using these local image descriptors, the system generates words that are "sneaker"-like, even though globally this shoe is not a sneaker.
After seeing these results we go back and make some changes to the model. Increasing the number of latent topics, from 100 to 200, helps separate features like "laces" and "sneakers" that might otherwise be in the same topic. It also helps pick up a few more details.
|
dyeable, white, straps, satin, dress, smooth, black, open, buckle, slingback |
 |
grain, full, details, construction, stylish, slip-on, shoes, clogs, durability, lining |
The words that are generated are also more descriptive this time, because we use a sentiment analysis wordlist to remove words that are opinions rather than objective observations. However, the list still does not get rid of all opinion words (such as "stylish" above), and there are also other types of noisy text that can mess up the keywords.
 |
google_extractor, sh, like_extractor, readme, txt, data, shaft, boots, true, boot |
 |
ankle, strap, stitching, touch, accents, adjustable, polyurethane, features, feminine, natural |
Part-of-Speech Tagging: Stanford Log-linear Part-of-Speech Tagger
SIFT descriptors and K-means clustering: VLFeat
Latent Dirichlet Allocation: Topic Modeling Toolbox