Steven P. Reiss
RESEARCH
Code Search
Overview
Today's code repositories are huge and growing. We estimate that GitHub contains over 500 billion lines of code. Its been shown that for any instance of 2-3 lines of code, there is probably similar code in the repository. It is reasonable to believe that for many common chunks of code and simple functions and applications, these repositories probably contain the code of interest either directly or in a state the developer could easily transform to meet their needs. Our efforts are based on locating such code and then doing the necessary transformations automatically.
1. TAIGA
TAIGA addresses the logical confluence of web services, peer-to-peer computing, grid computing, open source, autonomic computing, and software components. When all of these take off together, all programs share data, computation, and code, and one is left with a world where there is effectively only one program and it is running everywhere and all the time. TAIGA focused on the many issues that can arise as we move to such a world: how to define components, how to integrate privacy and security, dealing with failure as an integral part of all programs, economic and social issues, and frameworks for programming at the appropriate scale and level. As a demonstration program here, we have implemented a suite of tools that provide visualization of what is currently being viewed on the web by category and view of where news is currently occurring.
TAIGA was overly complex, including features such as a peer-to-peer network that worked across firewalls. Its main facility was the ability to define a component by its interface a set of test cases. Interfaces could be registered. The system would search for an validate implmentations of the interfaces using the test cases. Evolution was handled by periodicaly checking implementations against test cases and dynamic rebinding.
Resources
- Paper: A Component Model for Internet-Scale Applications
- Software: taiga.tar.gz
2. S6

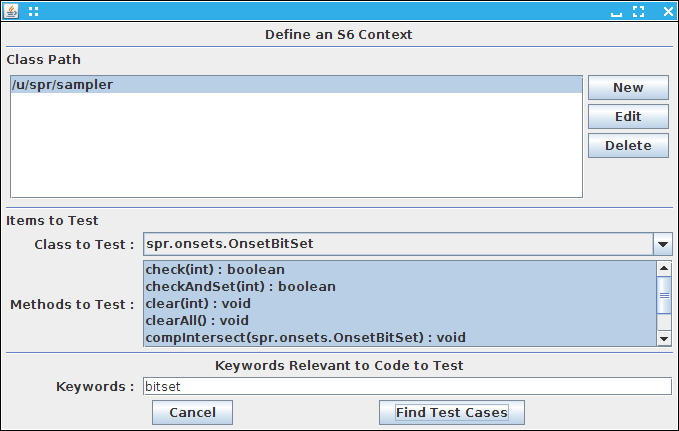
We realized the capability to define a component in terms of its signature and test cases (and possibly other semantic attributes) could be useful as a front end for searching the growing set of code repositories. The result was the S6 system for code search (named after L6). S6 is currently available as a web-based front end.
S6 takes a set of keywords, a method signature, and set of test cases (which can be entered as I/O pairs or as code), and searches repositories (currently GitHub or SearchCode) based on the keywords. It takes the results that are returned, applies various transforms to make them compile, more likely to be correct, match the signature, etc., and then tests the results against the test cases. Results that pass are then returned to the user.
S6 includes a number of extensions. It can search for classes as well as methods. It can attempt to find code that will fit into a user's program given the context (and doing transformations to use that context). It can check the security and performance of the returned results. It can reformat the results in various styles.
S6 is still maintained and working (for the most part). The web page is still active. It has served as the basis for much of the subsequent work.
Resources
- Paper: Semantics-Based Code Search.
- Software: S6 GitHub Repository
- Run it: S6 front end
3. SUISE


One of our frustrations with S6 was the need to have test cases. This was especialy true when trying to find user interface code where test cases are difficult to create. We realized that S6 didn't actually need test cases, just a means for checking if a returned result was valid or not.
To handle user interfaces we decided to match the interface the retrieved code returned versus a sketch the user drew. To make this practical we started with a structured sketch drawn using SVG. We then modified S6 to handle methods that created or drew Java Swing windows in various ways. We then added code that compared the resultant widget hierarchy with the user's sketch.
The result is a search tool that can find implementations of user interfaces in GitHub or other repositories that look similar to the user's original sketch.
Resources
- Paper: Seeking the User Interface
- Software: S6 GitHub Repository
4. TGEN

One of the difficulties in using code repositories is that many of the results that are returned are test cases rather than the code one might be interested in using. Our next effort tried to take this difficulty and make it an advantage. We created a tool on top of S6 that takes code a user wants to test and then searches the code respositories for JUnit tests that might correctly test that code.
This was done by finding all the test cases returned by some keywords, mapping those to call the method(s) to be tested, and then checking whether the method passed some or all of the tests. If a method pass enough of the tests, the test case "passed" and was reported to the user.
This project worked, but it had limited utility and would need considerable work to be actually practical.
Resources
- Paper: Creating Test Cases Using Code Search.
- Software: S6 GitHub Repository
5. GUIFETCH

Farnaz Behrang and her advisor at Georgia Tech, Alessandro Orso, spearheaded the next search-based project which looked for Android user interfaces based on sketches. In addition to handing Android and single screen matching, this tool handled the transitions between screens.
Resources
6. ssFIX, sharpFIX, and DiffTGen
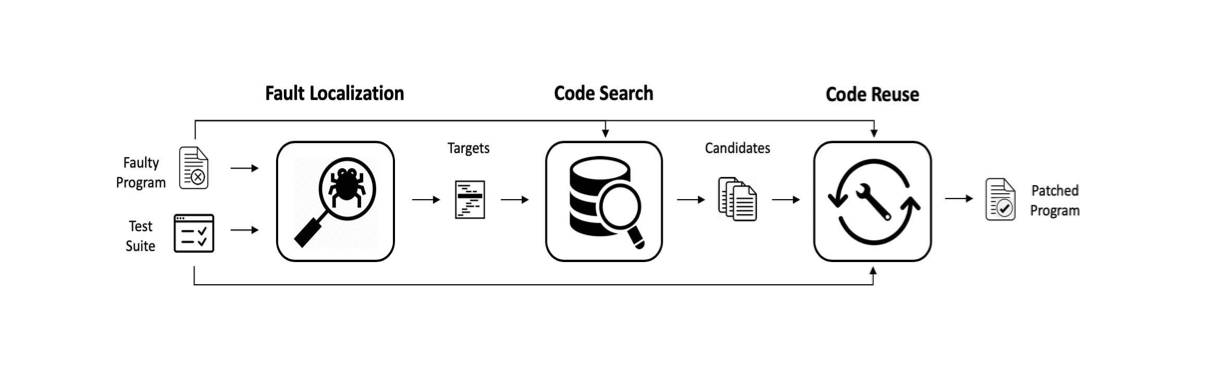
Qi Xin took the notion of code search several steps further. He attacked the problem of automatic bug repair using code search techniques. Automatic bug repair works by first doing fault localization, then finding potential patches at the given locations, and then validating those patches using a test suite. The problem with most methods is that they find overfitted patches, patches that pass the test cases but that are wrong. Qi figured that using patches based on existing code (in repositories) would be less likely to be overfitted. Thus these systems use code search to find code similar to the bad lines and use the differences to find patches.
ssFix and sharpFix work in similar ways but use different approaches to code search and matching retrieived code to the buggy code. They were both reasonably performant, achieving state-of-the-art results in a reasonable time.
We also introduced the notion of generating additional test cases as a means for eliminating overfitting. This was demonstrated in the DiffTGen system.
Resources
7. ASCUS
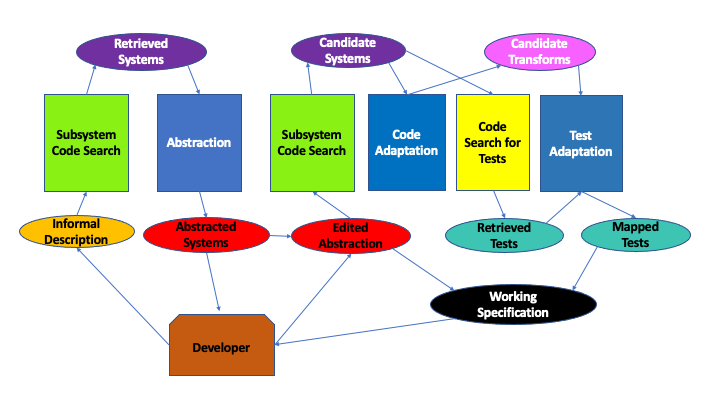
We continue to attempt to use code search for additional purposes. Our current efforts are aimed at searching for and adapting larger chunks of code, subsystems, from code repositories so that they can be inserted into user applications. A good proportion of an application (10-30% we estimate) is pro-forma code that probably exists in GitHub or another repository in a form that could be adapted to meet the requirements for a particular application. As an example, consider adding an embedded web server to an existing application. GitHub contains a variety of embedded web servers. These could be adapted to meed the particular requirements of the user.
However, determine what those requirements are and what woud meet the need are difficult. ASCUS uses code search to find different instances of web servers (as an example), abstracts these, and then presents them to the developer. The developer can choose the abstraction closest to their needs, and edit it as needed (adding methods, removing methods, changing names, referring to types in their application, etc.). ASCUS then uses code search to find instances close to the edited abstraction and transform the code retrieved to match the specification.
To be effective, these specifications need to include semantic information. We are currently working on this, starting with letting the developer specify test cases and using the search results to create potential test cases. Additional semantics and specification techniques will be needed. Moreover, the retrieved and transformed results are not going to be complete or correct. Automated bug repair techniques (possibly based on code search again) could be used as part of the transformations to handle this.
Our hope to eventually have a system that would do 75-90% of the work of adapting a subsystem automatically.