|
I put off writing the lecture notes for the first day of class thinking that I'd have an epiphany and suddenly it would be clear how to explain what this course is all about. Alas, it's the last day of the Labor Day weekend, classes start tomorrow and I've yet to experience any blinding flashes of insight. So instead of a concise and revealing description of Talking With Computers, I thought I'd tell you what I did on my summer vacation.
I'm a computer scientist so it probably isn't surprising that I write computer programs (though not all computer scientists write programs of a sort you'd readily recognize as such). I always bring a laptop when I go on vacation and it's not unusual for me to write code while traveling in cars, planes and even boats and staying at inns and hotels. Some of the code is work related though I like to keep the work to a minimum on vacation, some of it concerns research ideas and some of it is purely recreational. I'm going to tell you about some of the code I wrote past summer.
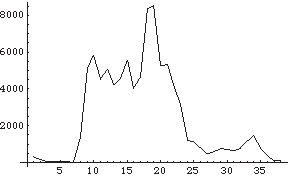
Early in the summer, my wife and I flew out to Seattle, rented a car and then drove back across the country to Providence. We visited friends and colleagues in Washington, Oregon, California, Utah, Denver, Illinois, Iowa, Pennsylvania, and Connecticut. Nearing the end of the trip, I was curious about the elevations of the locations we'd visited and I wanted to visualize the ups and downs of our trip. I used the atlas in the car to get a rough estimate of the altitude of each city we'd driven through and wrote a simple little program to display the data as a graph. Here's the result:
|
|
The horizontal axis corresponds to the cities in the order we visited them from left to right and the vertical axis to the elevation. You can see how we started in Seattle, drove south along the coast to San Francisco before heading east, climbed the Sierras and headed across the high plains of Nevada into Utah, over the Rockies into Denver, then across Kansas, Missouri and Illinois before getting into the eastern Piedmont and Appalachian mountains for one last jump in elevation before ending up near sea level in Connecticut and Rhode Island. When I got back from our trip, I asked a couple of my students to write a little program that would take a list of cities, find their elevations using a service offered by the U.S. Geological Survey that provides data on almost 2 million geographic features in the United States and its territories, and then display the results using standard graphing utilities. It's a good exercise that combines data collection and visualization. Engineers and scientists in both the physical and social sciences are often faced with collecting, sifting through and making sense out of terabytes of data (a terabyte is a thousand gigabytes or a million megabytes).
Scientific data includes images from satellites, demographic information, weather related data from automated sensors and human observers, health related data from hospitals and government disease tracking centers, traffic information, environmental data, just to name a few possible sources. Governments and biomedical companies are mapping out the genetic codes for dozens of organisms generating huge amounts of data in the process. All of this data is too much for humans to cope with and so we're automating the collection of data. (Biomonitors worn on your wrist or embedded under your skin may soon collect all your personal health information; imagine the amounts of data generated when everyone is wearing such devices.)
Of course, sifting through such masses of data is also overwhelming and so we're automating the analysis and categorization (or indexing) of such data. (Suppose I wanted to see if there was a connection between altitude and the occurrence of headaches I experienced during the trip.) But even once analyzed and indexed the resulting mass of information is pretty daunting and so, increasingly, we're automating the decision making based on such analyses. (Imagine a little program that relies on GPS (Global Positioning Satellite) data to determine my location, uses the web to look up the elevation of my current location and then, when called for, prompts me to take an aspirin to avoid a headache.)
Some people read about this sort of automation and think ``That's really cool!'' and others worry about technology intruding into our lives, threatening our privacy and eroding our freedoms. Talking With Computers is aimed at getting you to understand what computing and computing technologies are capable of. We'll talk about the ethical, political and philosophical consequences of technology, but we'll focus on the scientific and technological issues so you'll be better prepared to speak knowledgeably about technology and perhaps one day influence its course.
Here's another vacation hacking story. We were traveling in Maine and the Canadian maritime provinces of New Brunswick and Prince Edward Island when there was a big computer virus outbreak. A lot of my friends were using machines that were hit by the virus and as a result I received tons of email from infected machines, hundreds of messages every day. I wasn't worried about my laptop or my machine at Brown being infected, but it took forever to download all the bogus messages (just to delete them) using my laptop modem and a hotel phone. I could have hacked my spam filter (we'll talk about spam filters in Chapter 8) but instead I wrote a short program to log onto my machine at Brown and filter out the infected messages in my INBOX file (the place where mail queues up waiting for me to read it). Here's what my INBOX looks like prior to my looking at my messages:
BABYL OPTIONS:
Version: 5
^_^L
0, unseen,,
Return-Path: <long@hello.com>
Delivered-To: tld@cs.brown.edu
Subject: Top quality digital MP3 players
...
^_^L
0, unseen,,
Return-Path: <avery@fisher.com>
Delivered-To: tld@cs.brown.edu
Subject: Re: That movie
...
Please see the attached file for details.
Content-Type: application/octet-stream;
name="wicked.scr"
Content-Transfer-Encoding: base64
Content-Disposition: attachment;
filename="wicked.scr"
...
The first two lines specify the format in which the messages are stored. The character sequence ^_^L indicates the beginning of a message and the string 0, unseen,, provides information about the status of the message: whether I've read it, replied to it, forwarded it, deleted it (but not expunged it), etc. The ... just show where I've elided text to make the example shorter. Here's how my program works:
The program reads through all the messages in my INBOX twice. The first time it assigns a number to each message and then checks the contents of each message looking for suspicious content. The virus was a variant of the Sobig virus (actually it was classified as a worm). I learned from the web site of a company specializing in Internet security that messages generated by the Sobig worm have distinctive subject headers and attachments. I was in a hurry so I classified as being infected any message with an attachment containing a Program Information File (PIF), a screensaver file (SCR) or an executable file (EXE). In the second pass, I modified the INBOX so as to mark as deleted any message I'd classified as infected. This probably deleted some legitimate email, but I figured anyone who really wanted to get in touch with me would figure out some other way.
I wrote this program as a Perl script and then embedded it in a larger program called a shell script (you'll learn about scripts as programs in the first couple of lectures) that managed the remote calls to my computer at Brown. This is what's typically called a quick hack; it's not particularly elegant, but it gets the job done. Here's what the code looks like (I added the comments, lines starting with a # mark, just now so that there would be some chance of your understanding it -- I often have trouble understanding my own code without comments -- but I'll have more to say about the details in class):
#!/usr/bin/perl
# this program marks as deleted any message in an
# INBOX containing a Program Information File (PIF)
# screensaver file (SCR) or executable file (EXE).
# make a first pass to identify infected messages
open(INBOX, "INBOX" ) ;
# use a counter to number the messages
$counter = 0 ;
while ($_ = <INBOX>) {
# if you find the beginning of a message
if ( /\c_\cL/ ) {
# then increment the message counter
$counter++ ;
}
# if the message contains a suspect attachment
if ( /\.pif/i || /\.scr/i || /\.exe/i ) {
# then identify the message as infected
$infected{$counter} = 1 ;
}
}
close(INBOX) ;
# now make a second pass to mark the infected messages
open(INBOX, "INBOX" ) ;
# create a temporary file for the modified INBOX
open(TMP, "> INBOX.tmp" ) ;
# reset the counter used for numbering messages
$counter = 0 ;
while ($_ = <INBOX>) {
# if you find the beginning of a message
if ( /\c_\cL/ ) {
# then increment the counter exactly as before
$counter++ ;
# if the message is infected
if ( $infected{$counter} == 1 ) {
# then print the current line,
print TMP $_ ;
# skip to the next line in the file
$_ = <INBOX> ;
# and mark the message as deleted
s/(.*),,(.*)/$1, deleted,,$2/ ;
}
}
# print the current line to the temporary INBOX
print TMP $_ ;
}
close(INBOX) ;
close(TMP) ;
And here's what INBOX.tmp looks like after running the program on the example file listed above; note that the only difference is the change to the status line for the second message, the one containing the suspicious screensaver file:
BABYL OPTIONS:
Version: 5
^_^L
0, unseen,,
Return-Path: <long@hello.com>
Delivered-To: tld@cs.brown.edu
Subject: Top quality digital MP3 players
...
^_^L
0, unseen, deleted,,
Return-Path: <avery@fisher.com>
Delivered-To: tld@cs.brown.edu
Subject: Re: That movie
...
Please see the attached file for details.
Content-Type: application/octet-stream;
name="wicked.scr"
Content-Transfer-Encoding: base64
Content-Disposition: attachment;
filename="wicked.scr"
...
This isn't a fancy program, but it's a typical program for filtering data. It's probably more interesting thinking about the circumstances that prompted me to write it in the first place. This virus caused millions of dollars in damages. Essential services were shut down -- one airline was virtually grounded -- and lots of people were inconvenienced. What are the laws concerning who can send email (or invoke a program to cause email to be sent) to whom and what it can contain? Should companies, universities and Internet service providers filter incoming and outgoing email looking for viruses? Should employers and governments filter (snoop) our email messages? How can we legislate against spammers and malicious hackers and what should be the penalty for inflicting such damage?
It's important to keep in mind that technology didn't create this problem; people have subverted every communication technology that has ever been developed. Perhaps technology can be used to ``fix'' this problem, but I expect there is no perfect solution; advanced technologies exacerbate existing problems as well as create new opportunities for doing mischief. It's hard to put the genie back in the lamp after you've summoned him.
When I got back to Brown in late August, I found myself in the midst of a scheduling nightmare. I'd been relatively unfettered for the past year due to my being on a sabbatical leave, but now I was returning to Brown to take on new responsibilities that required my coordinating my appointments with all sorts of people. I've got two laptops, a machine at home and one in my office; I share calendar information with family, friends and colleagues with whom I work at Brown. I wanted to be able access the latest version of my calendar no matter where I was and ditto for my family, friends, colleagues and assistants. Now there are plenty of programs and personal organizers (sometimes called PDAs for ``personal digital assistants'') that handle this sort of thing and web services that provide so-called ``publish and subscribe'' services that simplify sharing calendar information, but I was in a hurry and didn't have time to fuss with finding and installing a new program or learning to use a new gadget. So I wrote two little programs and installed them on all of my machines.
The first program is invoked each time I start up my calendar program; it logs onto to a machine at Brown, grabs a file that contains the latest version of my calendar, and installs it on the machine I'm running the calendar program. When I exit the calendar program, it collects all of the calendar data into a single file, logs onto the same machine at Brown and updates the file containing the latest version of my calendar. These two little programs are very simple but they kept me from getting confused during that first week back at Brown. Here's the code (a script written in the C-shell scripting language) for the first of the two programs:
#!/bin/csh
# Upload most up-to-date calendar files from Brown
# Specify directories for local and remote files
set lcaldir=/Users/tld/Library/Calendars
set rcaldir=/u/tld/personal/calendar
# Specify binary directories for commands
set bin=/bin
set ubin=/usr/bin
# Connect to the local calendar directory
cd $lcaldir
# Delete any local calendar archive
if ( -r cal.tar ) $bin/mv cal.tar cal.old
# Use ssh/scp to copy the archive from the remote machine
$ubin/scp tld@klee.cs.brown.edu:$rcaldir/cal.tar cal.tar
# Make sure that the transfer completed successfully
if ( ! -r cal.tar ) then
echo "Remote transfer failed!"
if ( -r cal.old ) $bin/mv cal.old cal.tar
exit
endif
# List the new and old files and prompt for authorization
echo "Here are the last modification dates for the uploaded archive .."
tar -tvf cal.tar *.ics
echo "and here are the dates for the existing local calendar files:"
ls -lt *.ics
echo -n "Do you wish to continue with the update (yes or no): "
set input=$<
if ( $input == "no" || $input == "n" ) then
echo "No changes!"
$bin/rm cal.tar
if ( -r cal.old ) $bin/mv cal.old cal.tar
exit
endif
echo "Updating!"
# Extract the file in the calendar archive
tar -xf cal.tar
# Get rid of the old calendar archive on the local machine
if ( -r cal.old ) $bin/rm cal.old
Writing this little program and thinking about the difficulties in managing calendar files made me appreciate the advantages of hand-held calendar and contact devices. If you're always carrying your personal data in your PDA, you can view your calendar and contact info without being connected to a computer (aside from the PDA which contains a small computer). You can also ``synchronize'' the PDA with another PDA or a desktop computer if you want to share your calendar information or view it on a larger screen. The only downside is that you could lose the PDA and thus lose your data.
Here again it's interesting thinking about what these sort of programs and devices imply for how we lead our lives. Do you want people looking at your calendar? Some of the software now available actually allows other people with whom you share calendar information to insert appointments into your calendar! Do you want other people scheduling your time? Finding a time for a meeting that satisfies the constraints of all the participants is generally very difficult; it would be nice to have the computer do it automatically for you, but that requires that we sacrifice some of our autonomy. Again, technology can make some things simpler while complicating other things concerning freedom of choice, privacy, security and lifestyle.
Speaking of privacy, sharing and freedom of choice, have you ever taken advantage of the collaborative filtering services available on electronic commerce sites like amazon.com. These services suggest products, e.g., books, CDs and DVDs, that you might want to purchase based on how your browsing and prior purchasing compare with that of other customers. The companies providing such services may keep track of your purchases, record information about how you browse their web site (so called ``click data'') or ask you specifically about your preferences (e.g., rank order the following movies or tell us how much you like the following movies on a scale of 1-10). I'm interested in the research issues concerned with combining preferences, since they crop up whenever you think about how people working together might coordinate their activities or combine information from multiple sources.
When we left for Maine and Canada in August, I downloaded a paper to my laptop entitled ``Learning to Order Things'' by Cohen, Schapire and Singer [Cohen, Schapire, and Singer1999]. This paper describes an algorithm (the basic recipe for performing a computation) for ranking things based on the preferences of several experts. The authors motivate the algorithm by considering a strategy for searching the World Wide Web. Search engines respond to a query by displaying a set of web pages ranked by their (supposed) order of relevance to your query. Rather than relying on a single search engine such as Google, AltaVista or Yahoo! to find what you're looking for, why not try all of them and combine their respective rankings into a single ranking that's (hopefully) better than any one of them in isolation. Think of each search engine as an expert. The algorithm in the Cohen et al. paper makes it possible to ``tune'' the preferences of these experts to suit the needs of a particular user. Each time the user is presented with a ranking of search results, she's given an opportunity to provide feedback in the form of pairs of items that are ranked incorrectly.
I'd read the paper before I went on vacation, but I wanted to understand it better and so I decided to implement and play with the algorithm. My implementation is pretty bare bones and doesn't involve web searches, but it was enough to give me a much better understanding of how the algorithm works. Here's an example of my experimenting with the algorithm:
> (load "ranking.scm") > (alt-test) Ranking: (2 3 4 1 5 6) Feedback: ((1 4)) Ranking: (2 3 4 1 5 6) Feedback: ((1 3)) Ranking: (1 2 3 4 5 6)
Here I load the code which was written in a language called Scheme and then I execute a test program called alt-test. The test program prints the current ranking which combines the rankings of several experts and to which I respond by indicating that 1 and 4 are in the wrong order (the ``correct'' ranking is (1 2 3 4 5 6)). The program adjusts its ``confidence'' in the experts, but the adjustment doesn't make any difference in the ranking and the program displays the same ranking as before. This time I indicate that 1 should appear before 3 and this time when it adjusts its confidence in the experts (increasing confidence in those experts that rank 1 above 3 and decreasing its confidence in those that rank 3 above 1) it gets it right. The idea is that after a couple of rounds of feedback, the algorithm calibrates the experts, thereby creating a combined ranking that accurately reflects the user's preferences. In case you're curious, here's the code that I wrote while sitting on the front porch of a beautiful historic lodge overlooking the Atlantic Ocean on Prince Edward Island.
;; An implementation of the algorithms described in Cohen, Schapire ;; and Singer's (1999) "Learning to Order Things" in the Journal of ;; Artificial Intelligence Research, Volume 10, pp. 243-270, written ;; at Dalvay-by-the-Sea, Prince Edward Island, August 18, 2003. (require (lib "list.ss")) ;; An algorithm for learning a weighted preference function from a set ;; of ranking experts (Cohen, Schapire and Singer, 1999). Here we fix ;; the set of elements and the set of primitive ordering functions ;; that are used to infer the preferences of the ranking experts. (define (adjust-weights items beta weights ordering-functions rounds) (let ((pref (preference-function weights ordering-functions)) (feedback null) (unnormalized-adjusted-weights null)) (printf "Ranking: ~A~%Feedback: " (greedy-order items pref)) (set! feedback (read)) (set! unnormalized-adjusted-weights (map (lambda (ordering-function weight) (* weight (expt beta (loss ordering-function feedback)))) ordering-functions weights)) (if (= 0 rounds) weights (adjust-weights items beta (normalize unnormalized-adjusted-weights) ordering-functions (- rounds 1))))) (define (loss ordering-function feedback) (if (null? feedback) 1 (+ 1 (* -1 (/ 1 (length feedback)) (apply + (map (lambda (pair) (preference ordering-function (car pair) (cadr pair))) feedback)))))) (define (preference ordering-function u v) (cond ((> (ordering-function u) (ordering-function v)) 1) ((< (ordering-function u) (ordering-function v)) 0) (else 1/2))) (define (preference-function weights ordering-functions) (lambda (u v) (apply + (map (lambda (weight ordering-function) (* weight (preference ordering-function u v))) weights ordering-functions)))) ;; A greedy ordering algorithm (Cohen, Schapire and Singer, 1999): (define (greedy-order items pref) (let ((pi-values (map (lambda (v) (list v (apply + (map (lambda (u) (- (pref v u) (pref u v))) items)))) items))) (aux-greedy-order items pref (lambda (v) (cadr (assoc v pi-values))) (list)))) (define (aux-greedy-order items pref pi rho) (if (null? items) (reverse rho) (let* ((t (arg-max items pi)) (remaining-items (remove t items)) (pi-values (map (lambda (v) (list v (+ (pi v) (- (pref t v) (pref v t))))) remaining-items))) (aux-greedy-order remaining-items pref (lambda (v) (cadr (assoc v pi-values))) (cons t rho))))) ;; Utilities: (define (arg-max args f) (let ((arg-max-so-far (car args))) (for-each (lambda (arg) (if (> (f arg) (f arg-max-so-far)) (set! arg-max-so-far arg))) (cdr args)) arg-max-so-far)) (define (normalize weights) (let ((normalization-constant (apply + weights))) (map (lambda (weight) (/ weight normalization-constant)) weights))) ;; Testing: ;; Ordering functions for debugging: ;; 1 2 3 4 ;; {0 1} {2 3 4 5} {6 7 8 9 10 11} {12 13 14 15} ;; .100 .201 .202 .203 .204 .205 .306 .370 .308 .309 .310 .311 .412 .413 .414 .415 ;; .100 .401 .302 .303 .304 .305 .406 .470 .408 .409 .410 .411 .512 .513 .514 .515 ;; .100 .101 .402 .403 .404 .405 .706 .770 .708 .709 .710 .711 .912 .913 .914 .915 (define (f_1 i) (list-ref (preprocess '(.100 .101 .202 .203 .204 .205 .306 .307 .308 .309 .310 .311 .412 .413 .414 .415)) i)) (define (f_2 i) (list-ref (preprocess '(.100 .401 .302 .303 .304 .305 .406 .470 .408 .409 .410 .411 .512 .513 .514 .515)) i)) (define (f_3 i) (list-ref (preprocess '(.100 .101 .402 .403 .404 .405 .706 .770 .708 .709 .710 .711 .912 .913 .914 .915)) i)) (define (preprocess alist) (map - (map sub1 alist))) ;; Test functions: ;; In response to the prompt, type a list of pairs of instances. For ;; example, in response to "Feedback: " type "((1 2))" without quotes. (define (test) (adjust-weights '(2 1 3 4 5 6) 0.5 '(1/3 1/3 1/3) (list f_1 f_2 f_3) 7)) (define (alt-test) (adjust-weights '(2 1 3 4 5 6) 0.5 '(1/2 1/2) (list f_2 f_3) 7))
Now this is a more interesting piece of code involving a relatively sophisticated algorithm. Without reading the original paper and knowing how to program in Scheme, it would be difficult even for someone skilled in another programming language to really understand what's going on in this code. It's often said that it's easier to write a program from scratch than it is to understand someone else's program and adapt it to your own purposes. Why do you think this is the case?
The ideas and issues surrounding collaborative filtering and combining expert preferences are fascinating and provide interesting insights into individual and collective decision making. We're always sharing information about our preferences but, as is often the case when it comes to issues concerning information and communication, computing technology makes it easier and offers more sophisticated alternatives. Think about how such technologies might influence popular culture? Do you think technology will limit or expand diversity? Why won't there just be more of everything? Are you concerned about companies recording click data when you're on their web sites and then using it to influence others and sell products? What if we used this technology to vote for our representatives or to bypass the need for representation altogether by allowing us to vote directly for legislation?
Do you think you have free access to information on the web? What if the search engine that you use is biased so that it directs you to some web pages and steers you away from others? In Chapter 14 we'll look at algorithms for searching the web. I thought I'd mention one more ``algorithmically'' related subject that occupied me and two undergraduates, Damien and Katrina, for much of the summer. We were interested in a particular conjecture about the web which if true might make it possible to build personalized search engines that could be tuned to an individual's preferences.
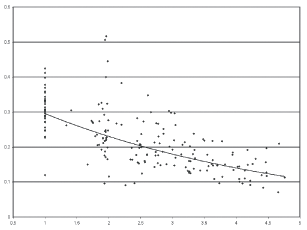
One would think that the web, created as it is by human beings, might be organized so that web pages that are more closely related to one another in terms of content would be more closely connected in terms of the number of links that you'd have to traverse in a browser to get from one to the other. We wanted to test this hypothesis and so we set out to analyze a hundred thousand web pages or so. Technically speaking, we wanted to know if the distance between pairs of web pages in terms of the number of links connecting them was correlated with the distance between the pages in terms of their relatedness from an information theoretic perspective. Damien and Katrina used programs written by one of my graduate students to mine the web for data and then wrote programs of their own to analyze the data. Here's a scatter plot that they produced and that supports the conjecture that link-related distance is correlated with content-related distance:
|
In this case the horizontal axis corresponds to the distance in links between pairs of pages and the vertical axis corresponds to the distance in terms of relatedness. There's obviously variation, some sets of pages are not that strongly correlated, but the trend seems pretty clear just looking at the graph and their statistical analysis confirms this observation.
Think of the web as a reflection of humans communicating with one another and sharing information. Technologists analyze the web to build better technologies; sociologists mine the web for insights into how societies function. Some scientists liken the web to a social network linking people in a web of personal and professional relationships. (Perhaps you've played a game called Six Degrees of Kevin Bacon which was inspired by the idea of social networks.) Thinking computationally is increasingly important in the physical as well as the social sciences. The data collection and analysis programs that Damien and Katrina wrote during the summer are similar to those written by biologists working in genetics and genomics, physicists analyzing astronomical data and political scientists looking for trends in census data. In this class, you'll learn how simple computational ideas can be applied to all sorts of problems from data analysis to robotics.