|
When calculators were first introduced into grade schools, some educators believed that the next generation would never learn to add, multiply or divide numbers without the aid of a calculator; it may be necessary to point out that they thought this was a bad thing. Today, when applications like Microsoft Word perform automatic spell (and grammar) checking and students carry out research for assignments using Google, educators are worried that many of you will never learn to spell or use a library. In light of such concerns, it's interesting to go back in history to learn what the early computer pioneers had in mind when they were developing the first digital computers.
John von Neumann was a mathematician who worked on the Manhattan Project and is credited with developing the organization or architecture of the modern computer. He was a child prodigy able divide eight-digit numbers in his head and recall whole pages of text after only a single reading. The Manhattan Project employed scores of human "computers" who performed calculations on paper. Von Neumann was interested in using electronic computers to speed these calculations; he viewed computers as intelligence amplifiers. Curiously, he was not interested in using computers to make it easier for humans to write computer programs; von Neumann was content to write programs in "machine language".
Alan Turing a British mathematician and computer pioneer imagined computers that would assist not only with numerical calculations but all sorts of inference from proving theorems to playing chess. During World War II, Turing worked for the British intelligence agency cracking the codes used by the Germans and Japanese to send encrypted messages.
In the aftermath of World War II, Vannevar Bush who was then the Director of the US Office of Scientific Research and Development laid out an ambitious plan to turn scientists from the development of weapons to building tools that would allow us to easily access and make use of the rapidly growing accumulation of human knowledge (see his article As We May Think in the July 1945 issue of Atlantic Monthly). Bush noted that while in the past humans built tools to extend and amplify their muscles, e.g., the steam engine, and their senses, e.g., the microscope, he wanted us to work on amplifying and extending our minds1.
More than a decade would pass before computer technology became powerful enough that there was much chance of realizing Vannevar Bush's dream. In the the 1960s, J.C. Licklider wrote several influential papers about how networked computers with displays capable of rendering images as well as text would transform business, education and even entertainment. Licklider was head of a major research program at ARPA (Advanced Research Projects Agency) that helped make possible the Internet and the personal computer. The ARPANET which Licklider funded would grow from a single, sparse network linking a few academic and industrial research labs to a vast web of interconnected networks. As computers rapidly dropped in price and the Internet expanded, all the major technology pieces were coming together to enable the development of the ideas of Bush, Licklider and other like-minded engineers and technology evangelists.
In the 1980s, Tim Berners-Lee put the pieces together to create the basis for what we now refer to as the World Wide Web. His original program was developed as a "memory substitute" to help him keep track of people and the projects they were working on. The Web is now a collective enterprise involving millions of users who use it not only to communicate and access information but also to provide content (by publishing Web pages) and develop new technologies (see World Wide Web Consortium and Open Source Initiative for examples of organization that promote the use of the Web and the development of related technologies).
This semester we're going to ground our discussions by thinking about what sort of intelligence amplifiers might be worth building and how current technologies could support their development. To be concrete, we're going to consider a particular application inspired by Vannevar Bush: hosting memories. Some of you may be aware that Yahoo! hosts small businesses by enabling them to run their online businesses on Yahoo! servers (see Paul Graham's article Beating the Averages to learn more about the origins of this service). We're going to develop a company that hosts people's memories.
We're going to create a company called Memories Incorporated that will keep track of all your digital stuff, organizing and indexing it so that you can easily retrieve what you need when you need it. This company is going to be based around an online service similar in some respects to the Yahoo! service for small businesses. We'll start with a simple (beta) version of the underlying software system - basically a specialized document management system - and then think about how to enhance it using more advanced technologies. In this course, you'll learn about all the basic software components needed to build such a system; you might even want to consider developing and marketing such a service.
In preparing for this semester, I developed a no-frills prototype using a bunch of open-source software components. In fact, I implemented the prototype twice in order to experiment with different tools. Both implementations rely on an industrial-strength database system called PostgreSQL to store all the documents and index them to support searches. The first time I implemented the prototype, I used PLT Scheme for most of the programming. The distribution of PLT Scheme includes a Web server which is written in Scheme. I often use Scheme for rapid prototyping and I was able to get my first implementation up and running in about a week of programming for only a couple of hours a day. The second implementation was a little easier since I'd already thought through most of the design issues in working on the first implementation. For the second implementation, I used a language called PHP which was designed for generating dynamic Web content of the sort required for electronic commerce Web sites. In this case, I used the Apache Web Server which is probably the most widely in use Web server today and works nicely with PHP. (Later in this document I provide some additional implementation details for anyone who's interested.) In addition to Scheme and PHP, I also used some other tools that we'll look at during the course: shell scripts - Chapter 1 ("Talking With Computers") and Chapter 2 ("The Shell Game"), C and Perl - Chapter 4 ("Don't Sweat the Syntax") and Chapter 5 ("Computational Muddles"), and Java and object-oriented programming - Chapter 6 ("Getting Oriented") and Chapter 7 ("Thanks for Sharing").
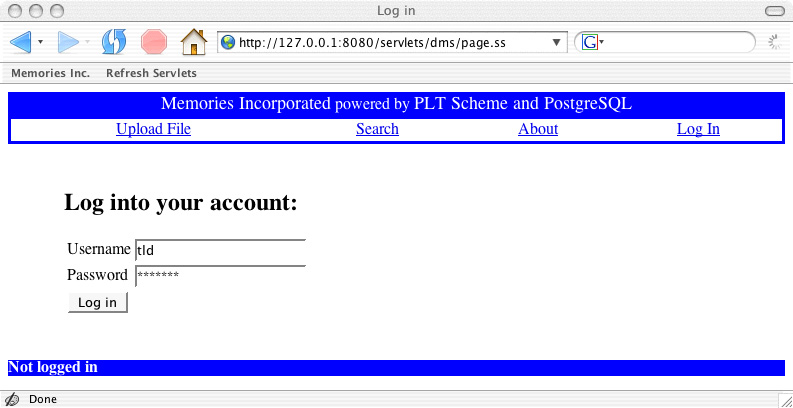
To start things off, we'll look at some screen shots of the beta version of the Memories Incorporated Web site to explore some of the design considerations. Memories Incorporated "hosts" memories for its customers; it stores memories and provides tools for clients to recall their memories. Users aren't likely to want to share their memories with just anyone and so one of the first considerations involves security. The following screen shot shows how a client will gain access to his or her memories.
|
|
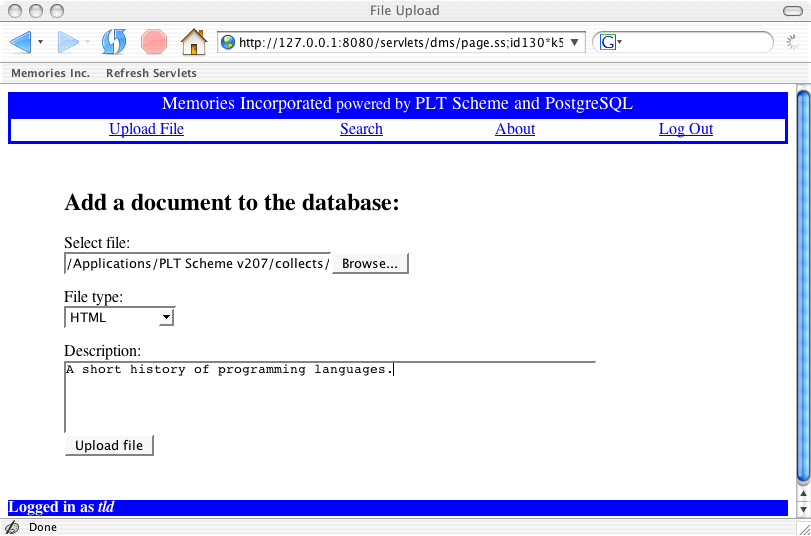
Here I'm using Mozilla's Firefox browser, but almost any browser, e.g., Microsoft Internet Explorer, will work just fine. Once the user has logged in, a number of options are available; here we see the screen for uploading documents (sending files from the user's machine to a Web server). Perhaps calling our company "Memories Incorporated" is a bit misleading; we can handle a variety of standard file formats but that's about it when it comes to storing memories. Once a file is uploaded, it's stored in a database on the Memories Incorporated computers. We'll discuss the advantages of using databases for storing large amounts of information in Chapter 3 ("Keeping Track of Your Stuff").
|
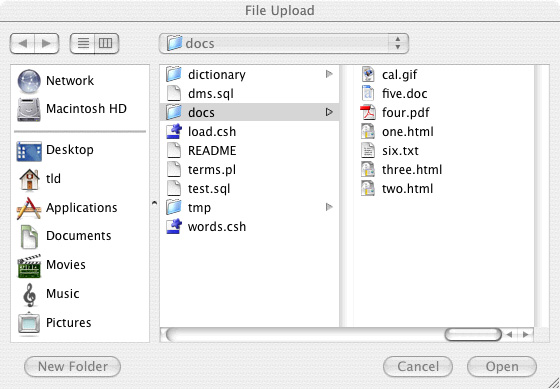
There are a couple of features of this page that you're probably familiar with from using Web browsers. When you click on the "browse" button, you get a window that allows you to select a file; the particular layout of the window displayed depends on the browser (Firefox) and your operating system (Mac OS X in this case). While there are standards that determine some aspects of how browsers interact with Web servers, other aspects of the interaction depend on various software components running on your local computer and the remote computer running the Web server.
|
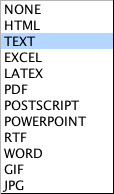
Most browsers handle variants of HTML (Hypertext Mark-up Language) but they implement the features of HTML differently. We'll learn more about HTML and HTTP (the protocol used to send information between browsers implementing HTTP clients and Web sites implementing HTTP servers) in Chapter 11 ("Under the Hood"). In particular, you'll learn about how (and where) different computations are carried out in the process of using a browser. When you click on the little caret next to the text box displaying the file type, you get a little pull-down menu showing a set of options. In this case, the computation required to implement the pull-down menu is carried out by your browser.
|
Each of these options corresponds to a particular standard for encoding information; having the user specify the MIME (Multipurpose Internet Mail Extensions) type for a given document, simplifies the job of the Web server in figuring out how to process the document. The World Wide Web wouldn't have been possible without the wide-spread adoption of standards like HTML, HTTP, JPEG, etc. In Chapter 11, we'll look at these standards and how they're used. Let's assume that we've used the file upload page multiple times to store a bunch of documents/memories on the Memories Incorporated Web server. Here's a window showing how we might issue a query to recall some of those documents.
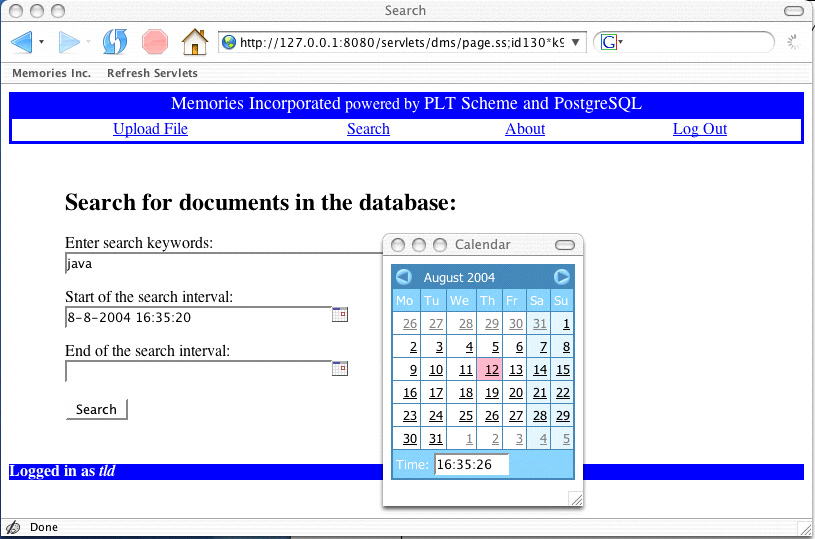
|
Note that in addition to key words of the sort that you might provide in a query to Google, you're also allowed to specify an interval of time that you'd like to search. We'll assume that stored memories are indexed by a variety of means, but certainly time is a particularly useful index. The above screen shot also shows a calendar menu that pops up when you click on the little calendar icon next to the start and end text boxes. The calendar menu makes it easy to pick times and ensures that the entered times adhere to the relevant standards. The calendar menu is implemented as a Java program that is executed by a program called the Java Virtual Machine that runs as part of your browser. Time on the Web is complicated by the fact that it depends on the locations of the various machine and the people using them. The next screen shot shows the result of submitting the above query.
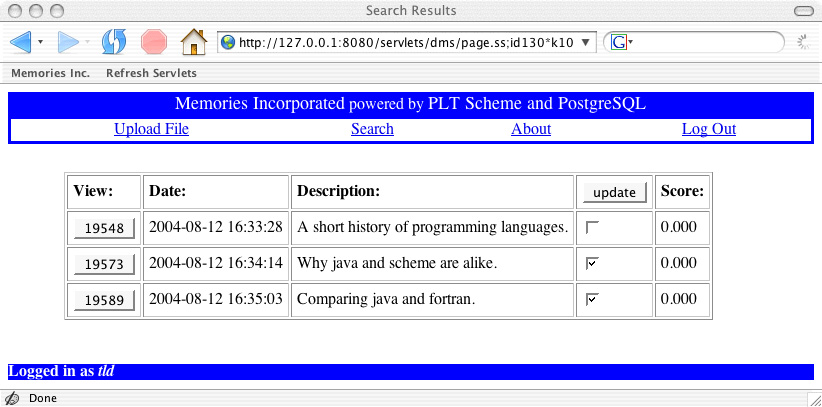
|
If you click on one of buttons under the View: heading, you'll get the corresponding stored document; Web pages (HTML documents) and images (JPEG and GIF documents) are displayed in the browser while other documents are downloaded to your machine and opened with the appropriate application, e.g., Adobe Reader or Microsoft Word). The results page also displays the date that the document was entered into the database and the description that was supplied. Web pages are also ranked using a measure of document similarity that we'll discuss in Chapter 14 ("Searching the Wild Web"). The column with the "update" button allows the user to select one or more documents to use in ranking the results of searches as shown in the next screen shot.
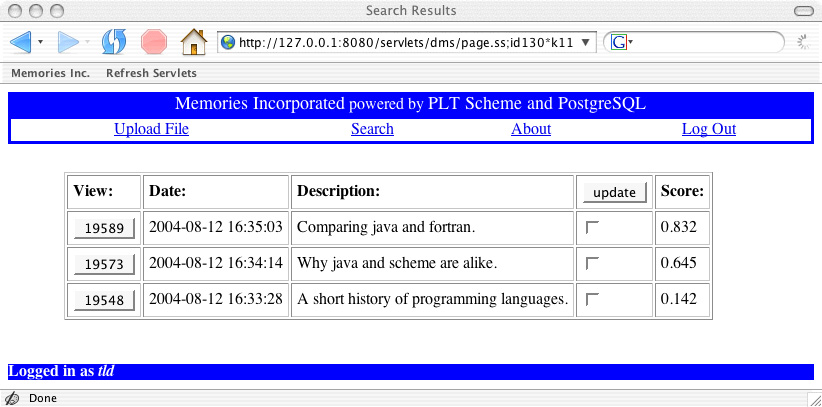
|
Notice that now there is a score associated with each document and the documents are listed in order of highest to lowest score. The basic machinery that we discuss in Chapter 14 allows us to compare two documents by looking at the words contained in each document. Here we let the user create an artificial composite document that combines the words from several documents; documents are then ranked according to how similar they are to this composite document. All of these calculations take place on the machine running Memories Incorporated's Web server. You might imagine more sophisticated methods for ranking search results; we'll look at some relevant machine-learning techniques from artificial intelligence in Chapter 8 ("You've Got (Junk) Mail").
Think about ways you might enhance the services offered by Memories Incorporated. Queries always happen in a context: what time it is, where you're located, what you're doing and what you've been doing recently. Some of the documents we might want to store have their own internal structure. Email messages have To:, From:, Cc:, and Subject: headers in addition to others that most people never know about, e.g., Internet addresses, routing information, references to earlier (replied-to) messages. The contents of messages can include attachments such as documents which have their own potentially complicated internal structure. In searching for information, you might want to search backwards in time from replies to the messages that spawned them, as is done in email programs that support "threading". The sequence of revisions of a document also has an interesting structure exploited in what are called version control systems.
Calendar entries and flight itineraries contain useful contextual information that could be incorporated to enrich memories. Nowadays some people carry cell phones that use GPS (Global Positioning Satellites) to identify their location to within a few meters, digital cameras to record what they see, and Internet access to determine the exact time by consulting online time services. You could augment your memories by linking them to weather and news available on line; indeed you might think of your memories as just another part of the World Wide Web, albeit a part of the Web that only you can see (unless you want to reveal your experiences as many people are wont to do in Weblogs and Wikis).
You might also imagine various ways of displaying memories. How would you visualize portions of the World Wide Web on a flat screen? Imagine a depiction of the external (public) Web overlaid with your internal (private) Web. Icons representing documents relevant to your present context could be highlighted. You might use the technique of sfumato2 to obtain depth by shading icons "deeper" in the screen to make them appear further away. The metaphor could be extended allowing you to "push" documents deeper into the screen or to the periphery to fine tune your context. You might also imagine an interface that continually updates your context and shifts as you read messages, browse the Web or look at your calendar. For a glimpse of what the future of computer visualization may look like check out the Cave Writing Project here at Brown.
I mentioned that I implemented the prototype described above twice; once using Scheme and a second time using PHP and Apache. Scheme and PHP are both general-purpose programming languages meaning that, at least mathematically speaking, either language can be used to write any program that it is possible to write. Scheme is a dialect of Lisp, one of the earliest computer programming languages. PHP derives from languages like C and Perl and was developed specifically to produce dynamic content in Web pages. Given its intended purpose, PHP has language constructs that make it particularly easy to generate HTML for Web pages. Scheme wasn't designed to produce Web pages but programmers have developed programs (commonly called libraries) that extend Scheme to support functionality similar to that available in PHP. Both PHP and Scheme have libraries for working with databases and PostgreSQL in particular.
I started by writing the code for the interface since this helped me think about how a user might interact with the system. The interface is implemented as a set of Web pages that present various options to the user, accept input and display results as depicted in the screen shots shown above. As is typical, I borrowed ideas and code from several other programmers3. After I had the interface more or less complete, I started writing the code to upload and download documents, process queries and rank search results. This involved writing SQL code (the lingua franca of the database world) to interact with the database and miscellaneous small programs (called scripts) to process documents. This was mostly stuff I'd done before but I did have to wrestle quite a bit with different document formats - here again I was able to borrow code from several open-source projects I found on the Web.
Sometimes I wrote code directly in HTML or SQL and sometimes I wrote using abstractions supported in PHP or Scheme. For example, the HTML code for a simple Web page might look like <html><body>some text<\body><\html> whereas in Scheme you would write (html (body "some text")). It may not seem like a big deal but the Scheme abstraction makes it easier to keep track of the begin and end of HTML tags, e.g., the tag <html> must be closed with a corresponding <\html> tag. Other abstractions make it easier to interact with databases and work with dates and times. Table 1 provides the PHP and Scheme code for the two implementations in case you'd like to compare them4. Even without knowing either language, you can get some idea of what's going on by comparing the two implementations and matching the pieces against the screen shots shown above.
| Programming Language | ||
|---|---|---|
| PHP | Scheme | |
| FILE STRUCTURE | README | README |
| WEB INTERFACE | page.php | page.ss |
| DATABASE CODE | database.php | database.ss |
| CONFIGURATION | configure.php | configure.scm |
While I could have written all the code in either PHP or Scheme, in some cases I used other programming languages to implement parts of the system. I did this either because I felt more comfortable writing code in a particular language to solve a particular problem or because the language made it easier to use certain libraries. Table 2 lists the additional support code for the PHP implementation; the support code for the Scheme implementation is very similar. In various places, I used Java, Perl and Unix shell scripts to get the job done; the shell scripts in particular make the code somewhat less portable (meaning that it would be a little more trouble to take my code developed under OS X and get it to run on Linux) but I was willing to sacrifice portability for ease of getting the prototype up and running. Also it's worth noting that in order to provide the services offered by Memories Incorporated I don't actually have to port any code to other operating systems; users can access Memories Incorporated services using any browser and all the code will run on the company's servers.
| A shell script that initializes the database and necessary working files. | load.csh |
| SQL commands that define functions and create database tables and indices. | dms.sql |
| A shell script that creates the records required for indexing documents. | words.csh |
| A Perl script that counts the frequency of occurrence of terms in a document. | terms.pl |
Looking at programs written in languages that you don't understand is a little like trying to understand a complex machine by playing with it. We'll set up the PHP implementation on an internal Web server so you can experiment with it. And as the semester progresses you'll get so you can understand much more of what's going on in the code. In the mean time, think about what would make a service like that offered by Memories Incorporated more useful.
1. It's certainly not the case that all tools built prior to the 20th century were meant only to extend our physical abilities; you can think of such innovations as cave writing, cuneiform, papyrus and the printing press as mental prosthetics in that they enable us to extend our memories and communicate more effectively.
2. Sfumato is a painting technique attributed to Leonardo da Vinci (1452-1519). Sfumato uses layers of translucent color to create the illusion of depth. It simulates the effects of atmosphere on our perception of distant objects. A related technique called chiaroscuro refers to the modeling of form (the creation of a sense of three-dimensionality in objects) through the use of light and shade. The term chiaroscuro is used in particular for the dramatic contrasts of light and dark introduced by Caravaggio (1573-1610).
3. The scheme code implementing the page layouts was adapted from Ryan Culpepper's SPGSQL demo and various servlet examples provided in the PLT Scheme distribution. The database module makes use of Culpepper's SPGSQL code for interacting with PostgreSQL from Scheme.
4. Detailed comparisons aren't worth the effort given that the design changed somewhat in writing the second implementation. In particular, the Scheme implementation doesn't separate the data from different users; all the documents are entered into the same database. The PHP implementation does separate data from multiple users. In the PHP implementation, there is a single template database containing all the tables and functions and then every user gets his or her own database which inherits all the tables and functions from the template. It would be fairly easy to modify the Scheme code to separate user data.