

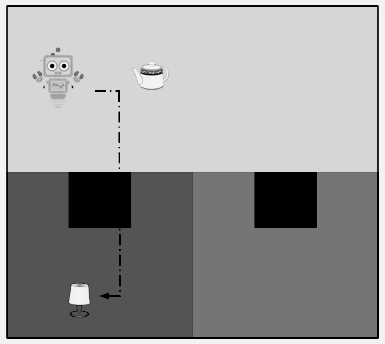
Take the lamp and put it where it belongs!"
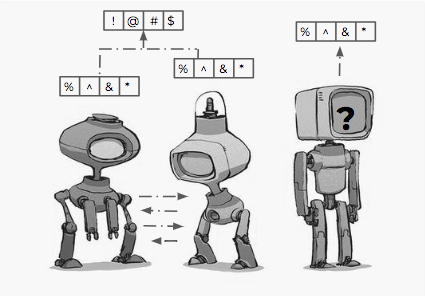
Language learning and coordination failure.
Natural language instructions drawn from different distributions are easily interpreted by natural language users i.e., humans. For our algorithmically crafted agents parameterised by task-specific deep neural networks, this is still significantly difficult. How do we map from varied natural language utterances to abstractions (that can be formalised to correct behaviours to then reach correct goal states)? Is language use a key factor to language interpretation? Do speaker-listener models trained in tandem always prove beneficial over an agent that solely tries to optimise for its task?
Any pair of speakers and listeners in actuality are likely to be influenced by distinct background knowledge. A goal-oriented communication framework assumes that they start from scratch, learn a language and reach equilibrium (i.e., manage to coordinate) by sharing beliefs and the other's knowledge of the world. This is not true of real world interactions, however. Every individual, through their own past interactions has composed their own "world" -- can speakers and listeners sampled from different worlds still coordinate to interpret the other's intent and meaning?
As humans, our reasoning and understanding capabilities are likely influenced by a number of factors; our participation in multimodal learning is very natural to us and our functioning. Is this a contributing factor to our higher reasoning abilities? More concretely, if we also engage machines in multimodal learning, does this improve their reasoning capabilities? The framework for certain understanding tasks like entailment, semantic composition, pragmatic reasoning etc., fit into this framework well, especially in the case of vision, and this is what we want to use to further natural language understanding. Can we map sequences of text to images they refer to and use this to infer knowledge about the text and further language understanding?
How do humans represent new concepts? How do they connect this with existing concepts? Extensive literature in cognitive science and psychology has both commended and criticised standard prototype and exemplar models, but is it some incorporation of both psychological theories interweaved with many layered networks that works best? How different are representations formed by humans from representations learned from the best models that attempt to perform the same task?
How do humans interpret and understand the meaning of a sentence? Are we internally decomposing it into abstractive, logical forms (lambda calculus?), relying only on what we know and have seen already (consult knowledge bases?), or is it a result of some uninterpretable mental signal process (neural nets?). More importantly, how can we get machines to efficiently represent text structures in a way that can allow such reasoning?
The Wall Street Journal, PubMed etc., are hugely important resources that have their own (very impactful) uses. But there is so much that we can learn from literary text; text that is free and unstructured in every sense and represents, in so many ways, the complexities and idealogies of different humans in different contexts, locations and lifetimes. Can language processing models and tasks extend to such larger units of text (paragraphs, chapters, entire novels) to uncover meaning, entity interactions, important plot events or summary story-lines?