At a high level our system can be characterized by the combination of
1) Strong low-level features based on histograms of oriented gradients (HOG).
2) Efficient matching algorithms for deformable part-based models (pictorial structures).
3) Discriminative learning with latent variables (latent SVM).
PASCAL VOC "Lifetime Achievement" Prize
The system is implemented in Matlab, with a few helper functions written
in C/C++ for efficiency reasons. The software was tested on several
versions of Linux and Mac OS X using Matlab versions R2009b and R2010a.
There may be compatibility issues with other versions of Matlab.
For questions regarding the source code please contact Ross Girshick at
r...@cs.uchicago.edu
(click the "..." to reveal the email address).
Source code and model download:
voc-release4.01.tgz (updated 11/23/11).
Cascade detection code: here
This project has been supported by the National Science Foundation under Grant No. 0534820, 0746569 and 0811340.
Slides from a presentation given at the 2009 Chicago Machine Learning Summer School and Workshop pdf.
[1] P. Felzenszwalb, D. McAllester, D. Ramaman.
A Discriminatively Trained, Multiscale, Deformable Part Model.
Proceedings of the IEEE CVPR 2008.
[2] P. Felzenszwalb, R. Girshick, D. McAllester, D. Ramanan.
Object Detection with Discriminatively Trained Part Based Models.
IEEE Transactions on Pattern Analysis and Machine Intelligence, Vol. 32,
No. 9, September 2010
pdf
[3] R. Girshick, P. Felzenszwalb, D. McAllester.
release4-notes.pdf -- also included in the download.
[4] P. Felzenszwalb, D. McAllester.
Object Detection Grammars.
University of Chicago, Computer Science TR-2010-02, February 2010.
pdf
[5] P. Felzenszwalb, R. Girshick, D. McAllester.
Cascade Object Detection with Deformable Part Models.
Proceedings of the IEEE CVPR 2010.
pdf
How to cite
When citing our system, please cite reference [2] and the website for the specific release.
The website bibtex reference is below.
@misc{voc-release4,
author = "Felzenszwalb, P. F. and Girshick, R. B. and McAllester, D.",
title = "Discriminatively Trained Deformable Part Models, Release 4",
howpublished = "http://people.cs.uchicago.edu/~pff/latent-release4/"}



The models included with the source code were trained on the train+val
dataset from each year and evaluated on the corresponding test
dataset.
This is exactly the protocol of the "comp3" competition.
Below are the average precision scores we obtain in each category.
| aero | bicycle | bird | boat | bottle | bus | car | cat | chair | cow | table | dog | horse | mbike | person | plant | sheep | sofa | train | tv | mean | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| without context | 39.5 | 48.2 | 11.4 | 12.3 | 28.6 | 42.3 | 40.4 | 25.0 | 17.4 | 20.5 | 15.3 | 14.5 | 42.1 | 44.4 | 41.9 | 12.7 | 24.3 | 16.5 | 43.3 | 32.2 | 28.6 |
| with context | 43.6 | 50.8 | 15.1 | 14.1 | 30.2 | 45.6 | 41.8 | 27.3 | 18.9 | 22.1 | 15.8 | 18.2 | 45.7 | 47.3 | 43.8 | 14.3 | 26.4 | 18.2 | 46.8 | 33.7 | 31.0 |
| aero | bicycle | bird | boat | bottle | bus | car | cat | chair | cow | table | dog | horse | mbike | person | plant | sheep | sofa | train | tv | mean | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| without context | 28.9 | 59.5 | 10.0 | 15.2 | 25.5 | 49.6 | 57.9 | 19.3 | 22.4 | 25.2 | 23.3 | 11.1 | 56.8 | 48.7 | 41.9 | 12.2 | 17.8 | 33.6 | 45.1 | 41.6 | 32.3 |
| with context | 31.2 | 61.5 | 11.9 | 17.4 | 27.0 | 49.1 | 59.6 | 23.1 | 23.0 | 26.3 | 24.9 | 12.9 | 60.1 | 51.0 | 43.2 | 13.4 | 18.8 | 36.2 | 49.1 | 43.0 | 34.1 |
| bicycle | bus | car | cat | cow | dog | horse | mbike | person | sheep | mean | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| without context | 67.1 | 65.8 | 70.7 | 26.8 | 47.7 | 15.8 | 48.3 | 66.0 | 41.0 | 45.6 | 49.5 |
| with context | 69.2 | 67.6 | 71.5 | 29.0 | 51.4 | 19.4 | 54.0 | 70.0 | 44.3 | 47.4 | 52.4 |
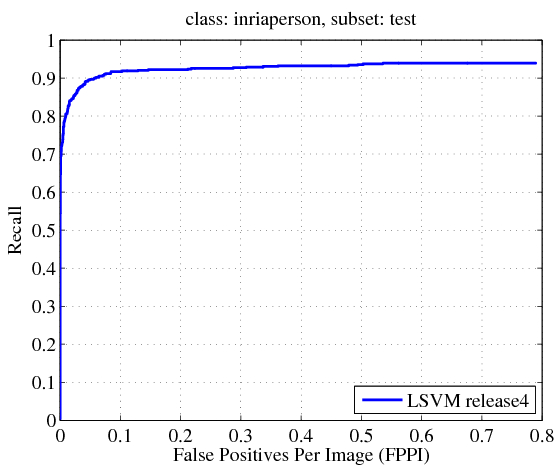
We also trained and tested a model on the INRIA Person dataset.
We
scored the model using the PASCAL evaluation methodology in the
complete test dataset, including images without people.
INRIA Person average precision: 88.2
Plot of Recall / False positives per image (FPPI):