Can software offer better data privacy by construction?
Web services that store and process sensitive personal data are critical to the digital economy today, but are often built without sufficient attention to users' rights over their data and its privacy. But doing a good job at data privacy is difficult, and requires substantial manual effort that costs billions of dollars every year.
The goal of this research project is to develop new software systems that fundamentally "democratize" good privacy practices, make it easy for users and web service operators to handle data in compliance with privacy laws, and retain or improve the performance of today's software.
Privacy-Compliant Storage Systems.
Easier compliance with privacy laws (GDPR, CCPA) using off-the-shelf software.
Privacy laws like the European Union's General Data Protection Regulation (GDPR) and the California Consumer Privacy Act (CCPA) give users new rights to control their data, with non-compliance carrying the risk of steep fines. But with today's systems, compliance with these rights requires onerous manual labor, particularly from small and medium-sized organizations.
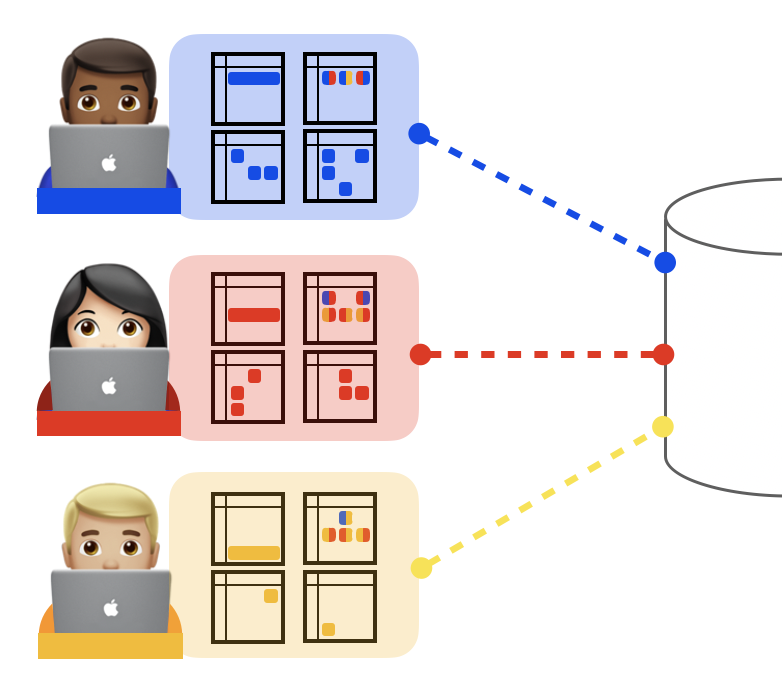
We designed K9db, a new relational storage system that automates compliance with privacy legislation. Realizing this "compliance by construction" requires innovation in system design: for example, K9db's architecture replaces relational tables (which mix different users' data) with per-user micro-databases (µDBs) as a primary abstraction. Making such a federation of µDBs efficient requires new techniques to track the impact of changes to users' µDBs on derived data, and our system relies on dataflow computing, a well-understood technique from scalable big data processing, to make compliant-by-construction databases efficient.









Flexible User Data Control with Edna.
New user data control choices via systematic data sealing in web services.
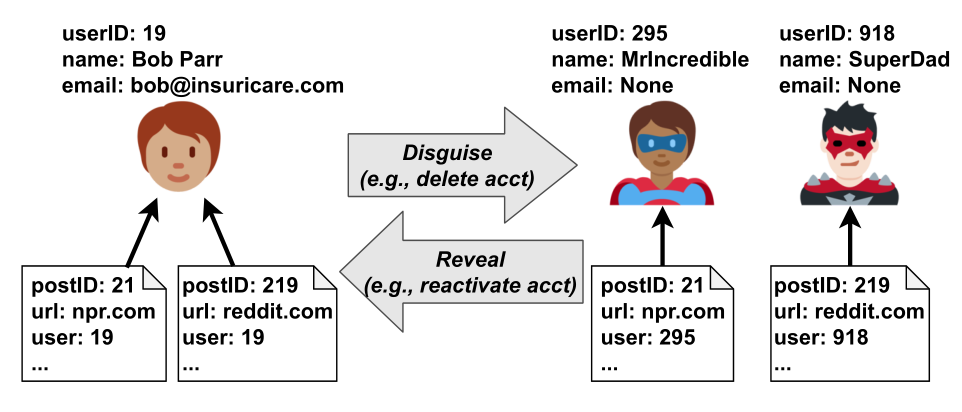
Privacy in complex, data-rich applications is hard. Consider a user who wants to remove their account from a service: even once all their data is found, only some of it should be removed; other data should be anonymized or decorrelated (for legal reasons, or to maintain application utility for other users). Or, a user might wish to disavow and anonymize some of their contributions, but retain others. Some of these transformations should also be reversible in case the user wants to return or reassociate with their data.
Edna is a library that lets web services offer a third state, where data is neither available, nor completely gone: disguised data that its owner can choose to reveal again. Importantly, Edna integrates disguising and revealing into existing web servcies without breaking application functionality for other users. To do so, developers provide a high-level specification and preexisting data relationships, while Edna handles the rest. Edna helps simplify privacy transformations that applications use today (such as account deletion), but also makes it easier to support fine-grained and nuanced policies that would be cumbersome to implement manually today, such as throwaway accounts, structural decorrelation of data, or "decay" of identifying information over time.




End-to-End Compliance with Sesame.
Practical tooling to help developers respect policies attached to data.
Web service developers face the daunting task of correctly applying legal and regulatory requirements (e.g., GDPR or HIPAA) and organizational policies (e.g., the company's privacy policy) to the code they write. Even with well-intentioned developers, bugs are common and lead to embarrassing data leaks and expensive fines.
Sesame is a framework for web service development that ensures, by construction, that developers respect policies attached to data. When developers implement an application using Sesame, sensitive data carries a policy object alongside the actual data. Policies are developer-specified, and remain attached to the data (and any derived data), and Sesame checks them whenever the data is about the leave the program (e.g., by sending an email, returning data to a web user, or writing to a database).
Sesame contributes a low-friction design for end-to-end policy enforcement: it achieves automatic guarantees for most of the application code by leveraging the Rust programming language, and focuses the developer's attention on the remaining code regions, called privacy regions. Sesame uses a combination of static analysis, dynamic enforcement using sandboxes, and human code review to guarantee that privacy regions respect the policies attached to data.





Finding Privacy Bugs with Paralegal.
Compile-time detection of privacy bugs in real code bases.
Privacy bugs are important, but finding them in today's software is hard. Applications that handle sensitive user data must comply with privacy policies and legal frameworks (e.g., GDPR), access control, and data retention limitations. Even within a single organization, the number of developers modifying a shared codebase on a daily basis makes it difficult to correctly implement and adhere to these requirements, so organizations today rely on manual audits that are laborious, error-prone, and unlikely to happen frequently.
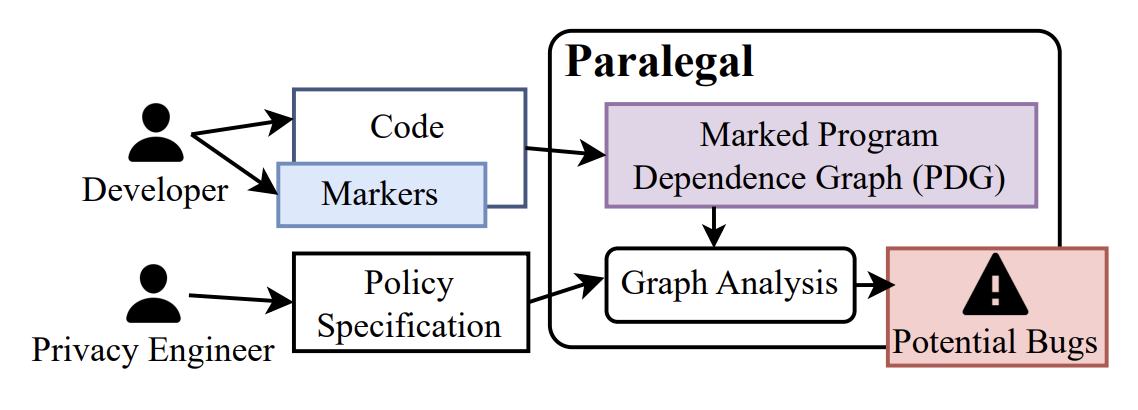
Automated code analysis tools could help address this problem, but must be practical and ergonomic to succeed. Paralegal is a new static analysis tool that checks privacy properties in Rust programs. Key to Paralegal’s practicality is its distribution of work between the program analyzer, privacy engineers, and application developers. Privacy engineers express a privacy policy using a vocabulary of markers that developers then apply to source code entities. Paralegal extracts a Program Dependence Graph (PDG) from Rust code, which it augments with the developers’ markers, and then checks the policy against.







Publications
-
Sesame: Practical End-to-End Privacy Compliance with Policy Containers and Privacy Regions
Kinan Dak Albab, Artem Agvanian, Allen Aby, Corinn Tiffany, Alexander Portland, Sarah Ridley, Malte Schwarzkopf
SOSP 2024
-
Edna: Disguising and Revealing User Data in Web Applications
Lillian Tsai, Hannah Gross, Eddie Kohler, Frans Kaashoek, Malte Schwarzkopf
SOSP 2023
-
K9db: Privacy-Compliant Storage For Web Applications By Construction
Kinan Dak Albab, Ishan Sharma, Justus Adam, Benjamin Kilimnik, Aaron Jeyaraj, Raj Paul, Artem Agvanian, Leonhard Spiegelberg, Malte Schwarzkopf
OSDI 2023
-
Retrofitting GDPR Compliance onto Legacy Databases
Archita Agarwal, Marilyn George, Aaron Jeyaraj, Malte Schwarzkopf
VLDB 2022
-
Privacy Heroes Need Data Disguises
Lilian Tsai, Malte Schwarzkopf, Eddie Kohler
HotOS 2021
-
GDPR Compliance by Construction
Malte Schwarzkopf, Eddie Kohler, M. Frans Kaashoek, Robert Morris
Poly 2019 workshop at VLDB 2019
Getting involved
If you're a Brown CS student and excited about this research, consider taking CSCI 2390: Privacy-Conscious Computer Systems.
If you're curious about our work, reach out to Malte Schwarzkopf.
Support





This work is supported by a National Science Foundation (NSF) CAREER award, a Google Research Scholar Award, a Microsoft Grant for Customer Experience Innovation, an Amazon Research Award, and a gift from VMware.