
Image segmentation deals with the problem of splitting images into ``homogeneous'' chunks. Homogeneity is usually determined on the basis of appearance, location and possibly even semantic content. It has been a hot bed of research in the computer vision community over the past several decades. Some of the more popular techniques are clustering based algorithms, which cluster pixels on the basis of their spatial and appearance proximity (Mean Shift, Felzenszwalb and Huttenlocher, Normalized Cuts). However, in spite of the intense amount of work, the problem remains largely unsolved. Disappointing segmentation results can primarily be attributed to:
|
|
| Normalized Cuts | Human Segmentation |
Recently, based on these observations, Sudderth and Jordan'08 have proposed nonparametric models which are able to automatically infer the number of clusters in a given image. This alleviates the problem of having per-image tunable parameters. Furthermore by placing a particular nonparametric prior the Pitman-Yor process prior, they are able to model widely varying segment sizes. In this project, we extend their work by additionally learning the appropriate segmentation resolution.
A popular approach to modeling images, has been to fit a finite mixture model to the image data, such that each component of the mixture explains some aspect of the mixture. However, such an approach requires pre-specification of the number of components resulting in a semi-automatic algorithm. By placing a nonparametric prior over the number of components we automatically infer the number of components required to explain a given image. Additionally, we observe that segment sizes in human segmentations follow a power law distribution, motivating the use of the Pitman Yor process prior. This gives rise to a infinite mixture model shown in the left half of the following figure. However, this simple model ignores spatial dependencies between the image pixels (super-pixels). The model on the right fixes this problem by incorporating a additional Gaussian process(GP) prior over the latent variables. GP is parameterized by a covariance kernel(K) which determines how correlated two pixels (super-pixels) are. Highly correlated super-pixels are encouraged to belong in the same segment in this model.
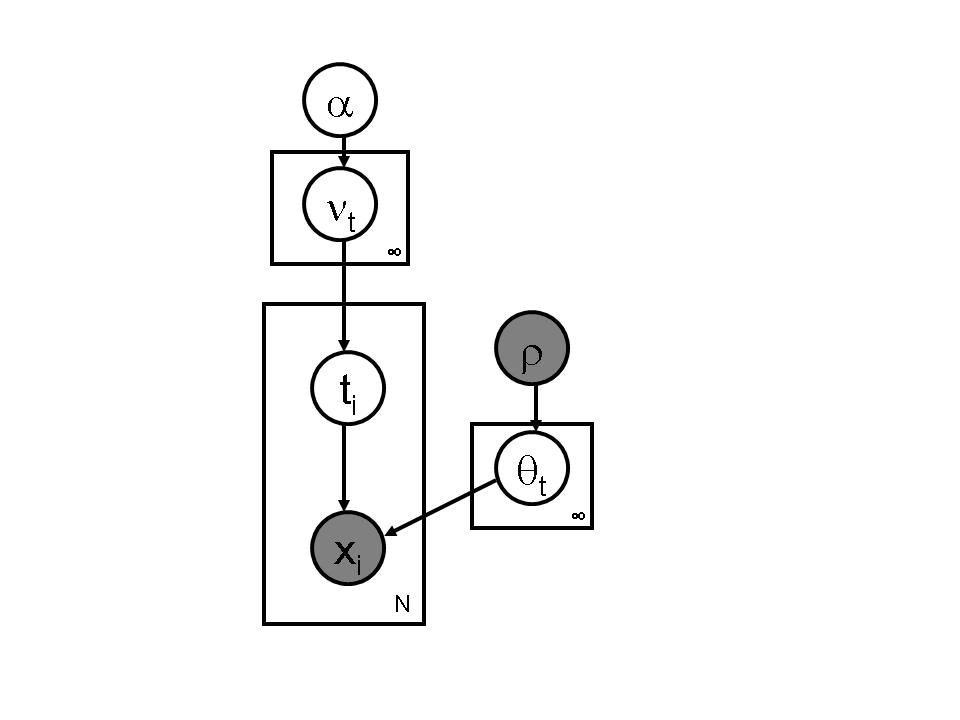
|
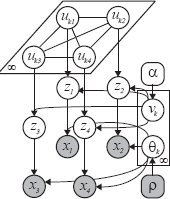
|
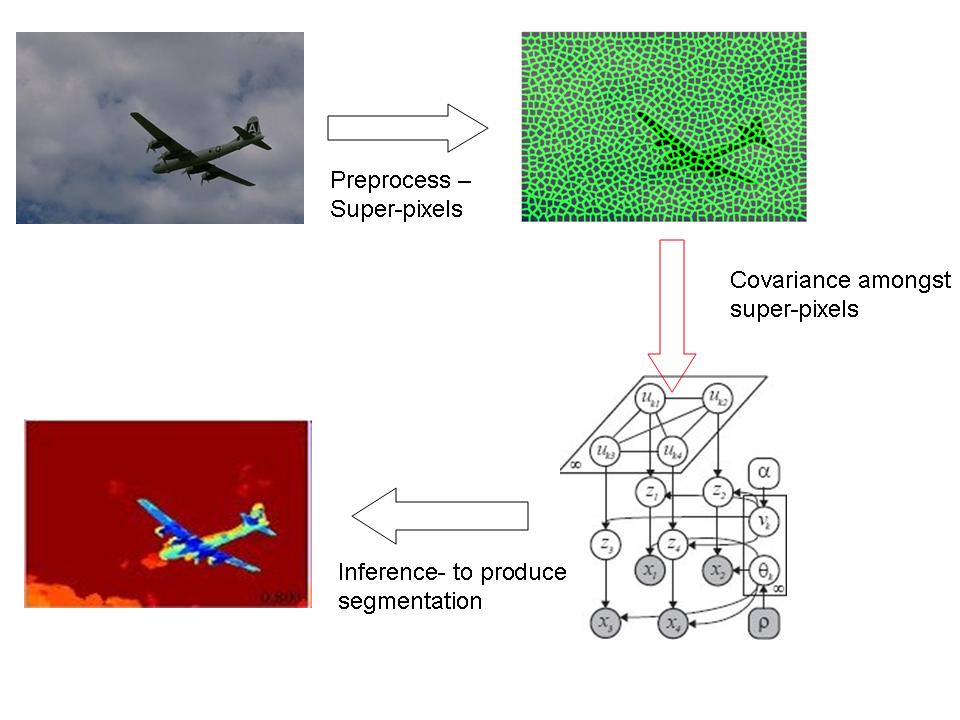
|
| Pitman-Yor Mixture Model | Spatial Pitman-Yor Mixture Model | Segmentation Pipeline |
Observe the three different segmentations shown below. The one on the left, segments the windows out from the face of the building, the one in the center fuses the head and torso of the man in one segment, while the one in the right allocates a different segment to the head.

|

|

|

|
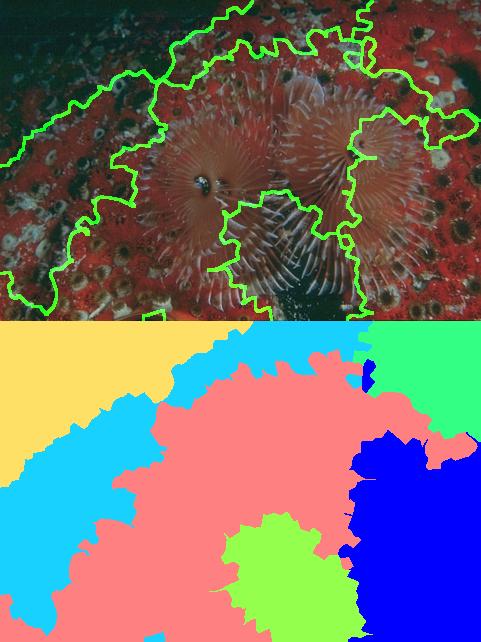
|

|
The goal of this project was to learn the appropriate segmentation resolution from data.In the spatially dependent model, the segmentation resolution is governed by two factors, the number of clusters assigned to the image by the PY prior and the covariance kernel(K) of the Gaussian process prior, which controls the mapping from clusters to segments. By learning the PY hyper-peramters and the GP covariance kernel we can learn the desired segmentation resolution. The primary focus of this project was to learn the GP covariance kernel. The PY hyper-parameters can be tuned in a variety of ways ranging from cross-validation to maximum likelihood estimation. For the purpose of this project the hyper-parameters were fixed using ML estimation. We pursued two approaches, one was a supervised model based approach wherein a logistic regression model was learnt from training data of human segmentations, while the other was a nearest neighbor based unsupervised approach inspired by the work of Rusell et al.
The BerkeleyImage Segmentation Dataset contains human ground truth segmentations for the images in the dataset. We used the 200 training images to train the logistic regression classifier. Super-pixels belonging to the same human segment were given a positive class label , while those belonging to different human segments were given a negative label. The trained classifier was then used to predict the probability that two super-pixels in the test set (comprising of 100 images) belong to the same segment. These probabilities were then mapped to valid correlation values between -1 and 1.
A variety of features were experimented with, and we found a combination of distance and maximum edge response (computed using the Pb detector) between two super-pixels to work the best. These features could not be used in the nearest neighbor case. Thus all reported comparisons are using color-histogram features, which could be used both for the supervised and the nearest neighbor cases.
The underlying assumption here is that images are made up of objects, and although the relative location of objects in various scenes can change vastly, the internal structure of the objects will remain more or less unchanged. Given a set of nearest neighbors for an image, we can compute the correlation between local patches of the image by querying the nearest neighbor set and computing the correlation between the ranked list of images retrieved for each patch. Intuitively, patches in the interior of a region will tend to retrieve similar images, thus exhibiting high correlations.
Given a image to segment we first find its nearest neighbors by querying a large image database. Next the query image is over-segmented using Normalized cuts to give a set of super-pixels (each image is split into roughly 1000 super-pixels). Now for each super-pixel we extract it's color-histogram, along with the color-histograms of all regions in the nearest neighbor set at the super-pixel location. Following Rusell et al. we assume that the nearest neighbors are all coarsely aligned and only consider matches at the current location of the super-pixel.
Finally for the retrieved list of images we compute the spearman's correlation coefficient given by:
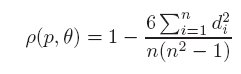 , where n is the number of NN images and d_i is the difference between ranks of the image i in the two ranked lists corresponding to two different super-pixels.
, where n is the number of NN images and d_i is the difference between ranks of the image i in the two ranked lists corresponding to two different super-pixels.
The following table shows the resulting segmentations produced by the two competing methods. The images on the left are the nearest neighbor results while the ones on the right were produced by the supervised method.
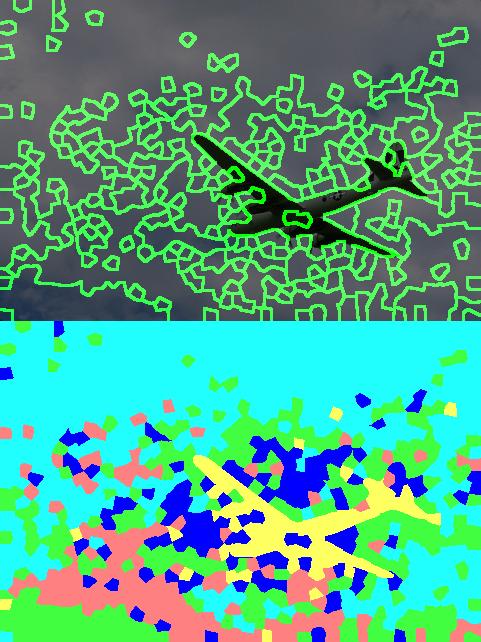
|

|

|

|

|

|

|
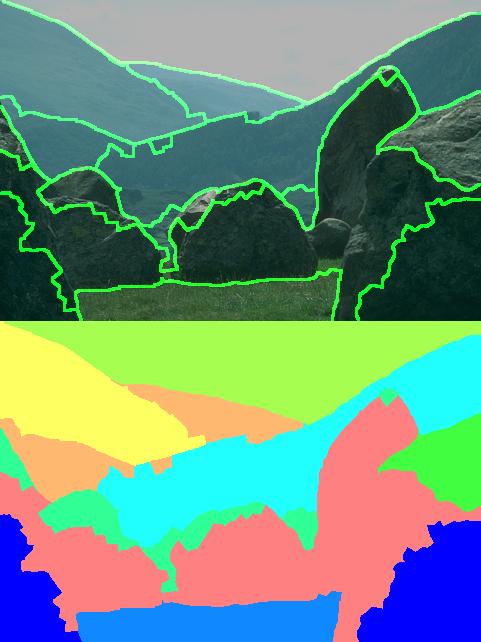
|

|
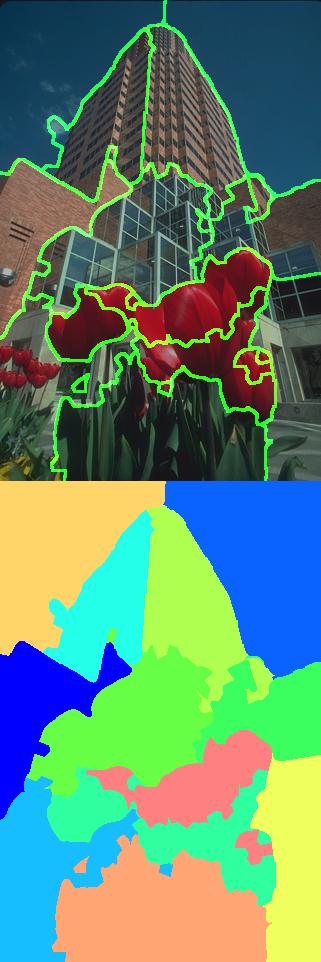
|
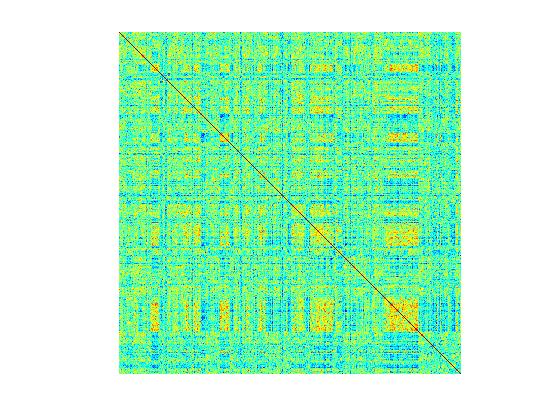
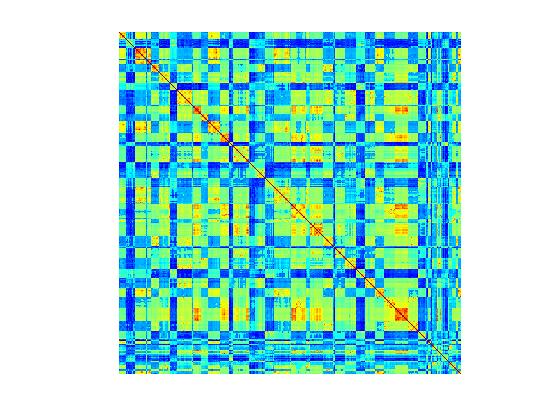
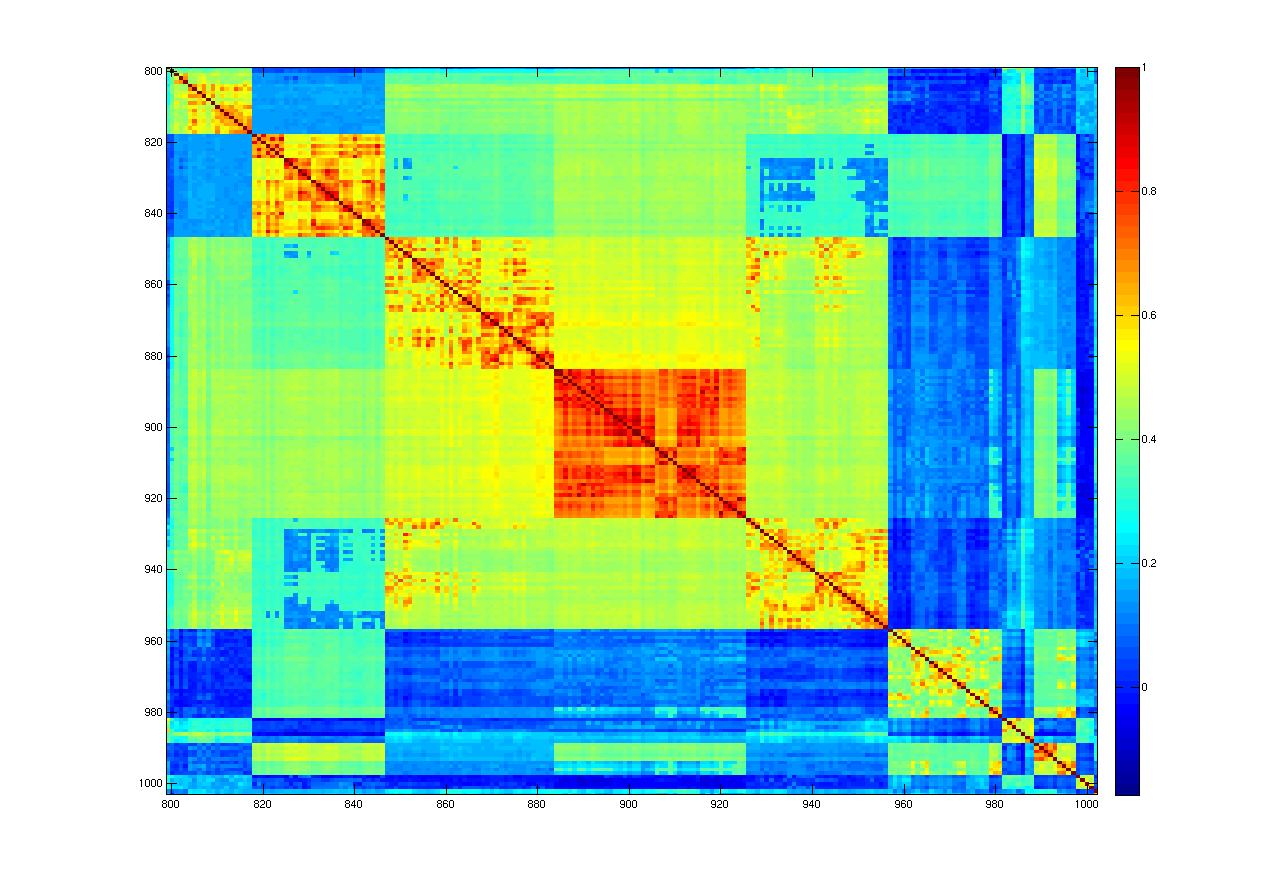
As can be seen the results are somewhat disappointing for the nearest neighbor method. The segmentations produced are far too noisy, which implies that the covariance matrix learnt may not be smooth. The figure below corroborates the above hypothesis. It visualizes the learnt covariance matrices for the first image. This image had 1093 super-pixels and hence the dimensions of the matrices are 1093*1093 . The image on the left is the covariance matrix learnt by the nearest neighbor method, while the on the right is learnt using logistic regression. While both matrices seem to capture similar structures, the NN covariance matrix is more noisy. The second row, shows zoomed in sections of the matrices.
|
|

|
|
In particular, this suggests querying the nearest neighbor set independently for each super-pixel is not robust. This could be for a variety of reasons
The top three matches for our query image were:

|

|

|
Next, we investigate the super-pixel appearance variance. Consider super-pixels 1011 and 1012 shown in the figure below
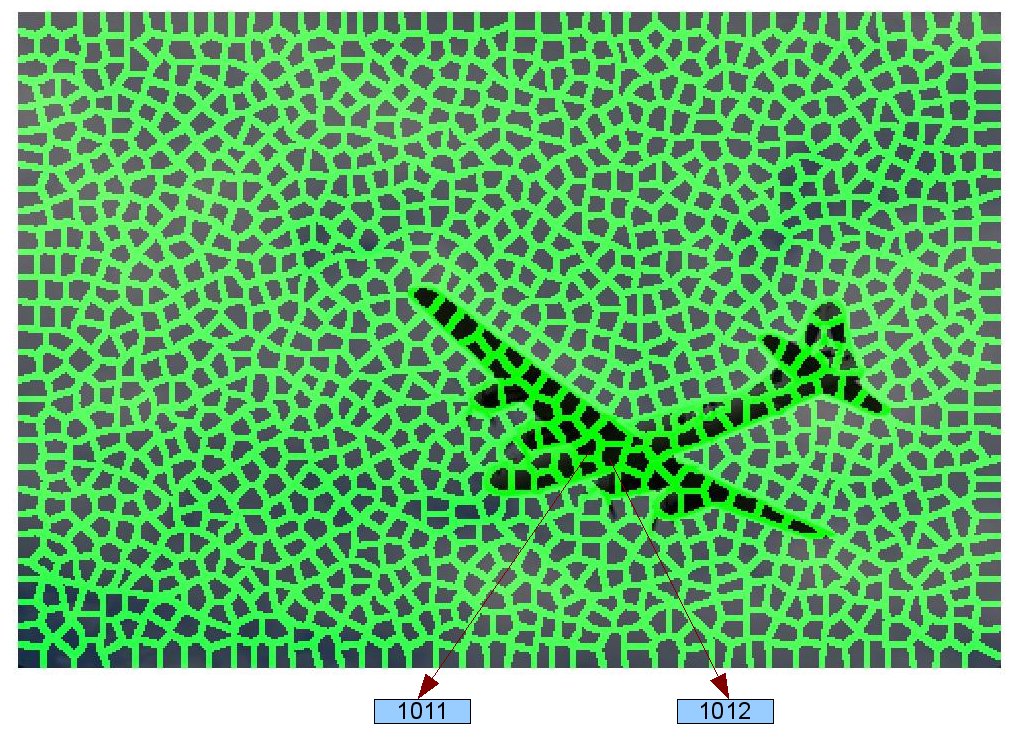
Matches returned for these super-pixels in ranked order are shown below (Each row corresponds to one super-pixel):

|

|

|

|

|

|
This seems to suggest that even for neighboring super-pixels with fairly similar appearance features, the image lists can be significantly different. The resulting correlation coefficient between the two super-pixels is 0.0043.
Given the observations in the previous section, it does appear that rather than the poor performance of the nearest neighbor method, at least to some degree, can be attributed to computational limitations. Firstly, for this project only a subset of the 16 million image strong dataset could be queried. Searching over the whole dataset should significantly improve nearest neighbor matches. Secondly, it does appear that querying the retrieved nearest neighbors independently for each super-pixel might not be the best idea. Doing so firstly, places significant computational burden (each image has roughly a 1000 super-pixels). Next, super-pixels contain a order of magnitude fewer pixels than the 32*32 patches used by Russell et al. This causes the matches to be less robust, since the color histograms can vary widely with "outlier" pixels in the super-pixel. Finally, this project only considered color histograms for representing the appearance of a super-pixel. Additional features (textons) would also help alleviate robustness issues.