Final Project: Super-Resolution From a Single Image (Writeup)
Jason Pacheco (pachecoj)
May 17, 2010

Problem Description
The goal of super resolution (SR) is to produce a high resolution image
from a low resolution input. Rather than simply interpolating the
unknown pixel values we wish to infer their true value based on the
information in the input. To do this we introduce the super
resolution equation.
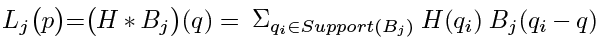 (1)
(1)Where Lj(p) denotes the value of the pixel at location p in the low resolution image. Similarly H(q) denotes the value at pixel location q in the latent high resolution image. B(.) is the blur kernel, or point spread function (PSF). The subscript j denotes a particular low-res image and blur kernel, which will be described later. Equation (1) states that the low resolution image is assumed to be the result of a convolution between the high resolution image and a PSF and then down-sampled.
Because convolution is a linear operation Equation (1) induces a set of linear constraints on the latent high resolution image H. Given only a single low resolution image, though, Equation (1) is underconstrained.
Using the concept of patch redundancy it is possible to at least approximate a solution to Equation (1) using only a single image. In D. Glasner, S. Bagon, M. Irani the authors present an algorithm for performing super resolution from a single image. This project implements the specified algorithm and presents results on a set of images.
Algorithm Description
There are two types of super-resolution commonly explored, Classical Super-Resolution and Example-Based Super-Resolution. The algorithm of D. Glasner, S. Bagon, M. Irani unifies these two methods to perform super-resolution on a single image. Before describing the unified algorithm we first introduce Classical SR and Example-Based SR.
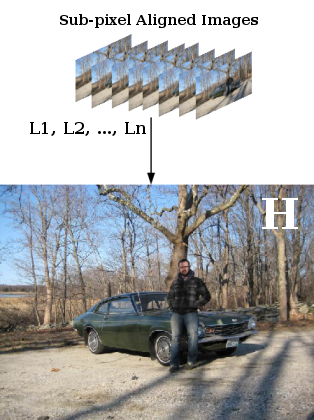
Figure 1: Classical Super-Resolution

Figure 2: Example-Based Super-Resolution training patches. Image from W. T. Freeman, T. R. Jones, and E. C. Pasztor.
Classical Super-Resolution
Because Equation (1) is underconstrained we need more than a single low-res image to solve it. If, for example, we are given multiple low-res images of the same scene denoted L1, L2, ..., Ln we can derive more constraints on the latent high-res image H. If enough low-resolution images are given the resulting system of linear equations becomes fully constrained.
Classical super-resolution assumes that we have a set of low-res images that are aligned at sub-pixel accuracy. The low-res images are denoted Lj and we assume a known blur kernel Bj for each image. The algorithm is as follows: For each pixel in L find its k nearest patch neighbors in the same image L and compute their sub-pixel alignment at 1/s pixel shifts (where s is the scale factor). Assuming sufficient neighbors are found, this process results in a determined set of linear equations of the unknown pixel values in H.
When multiple low-res images are available this method can work quite well. However it has been shown by S. Baker, T. Kanade and Z. Lin, H. Shum that this approach is practically limited to only small increases in resolution (e.g. 2x).
Example-Based Super-Resolution
In the case where we do not have multiple low-res images Lj of the same scene we cannot construct a determined set of linear equations. To solve this we turn to Machine Learning techniques to find approximate solutions to the problem. Example-based super-resolution was first introduced by W. T. Freeman, T. R. Jones, and E. C. Pasztor.
A supervised learning technique is proposed in Freeman et. al. in
which correspondences between low-resolution and high-resolution
images are learned from a set of training images. The training set
consists of high-resolution / low-resolution pairs. The images are
decomposed into patches such that we have correspondence between a
"latent" high-resolution patch denoted Xi and
their observed low-resolution counterparts denoted
Yi. Freeman et. al. construct a probabilistic
interpretation between low-res / high-res patch pairs. The
posterior probability of a high-resolution image X given the
observed low-res image
Y is,
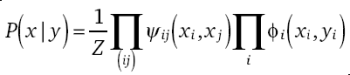 (2)
(2)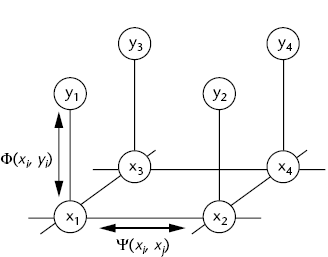
Figure 3: MRF of example-based super-resolution. Image from W. T. Freeman, T. R. Jones, and E. C. Pasztor.
where 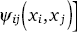 denotes the compatibility function between two neighboring latent
high-res patches
xi and xj. Similarly,
denotes the compatibility function between two neighboring latent
high-res patches
xi and xj. Similarly, 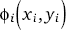 denotes the compatibility function governing the
emission likelihood of a low-res patch yi given a
latent high-res patch xi. The model is depicted
in Figure 3 as a Markov Random Field (MRF). To learn the posterior
probabilities on each latent high-res patch Freeman et. al. use
belief propagation.
denotes the compatibility function governing the
emission likelihood of a low-res patch yi given a
latent high-res patch xi. The model is depicted
in Figure 3 as a Markov Random Field (MRF). To learn the posterior
probabilities on each latent high-res patch Freeman et. al. use
belief propagation.
The main drawback of example-based SR is its tendency to amplify artifacts, particularly JPEG compression artifacts. This is noted in Freeman et. al. The unified SR approach of Glasner et. al. alleviates this since the classical SR constraints act as a prior term.
Unified Super-Resolution
Freeman et. al. provide a preliminary investigation on patch redundancy. More specifically they show that, given a training set of high-res / low-res images, there is considerable redundancy between 5x5 patches in the input image and 5x5 patches in the low-resolution training images. Furthermore they show that this redundancy holds even when the training set does not consist of the same class of images as the input image. For example, with a training set of portraits they show that the algorithm can successfully super-resolve images of flowers.

Figure 4: Patches within-scale and across scales of an image. Image from D. Glasner, S. Bagon, M. Irani.
Taking the idea of patch redundancy further Glasner et. al. show that there is significant redundancy of patches within a single image. Furthermore they show that there is redundancy of patches across scales of the same image. Figure 4 shows an example of in-scale and cross-scale patch redundancy.
Let L=I0 denote the low-resolution input image. Furthermore let I-s denote a down-sampled version of L such that I0 is an sX magnification of I-s. Finally, let Is be an sX magnification of I0. For each patch Pj the algorithm proceeds by finding the k nearest neighbors of Pj in all images I0, I-1, ..., I-n. Matches within I0 are referred to as "within-scale" and matches in I-1, ..., I-n are referred to as "across scale".
Each within-scale match to patch Pj can be treated as an observation of Pj at a sub-pixel misalignment. As such the within-scale matches induce Classical SR constraints. Similarly, across-scale matches to Pj induce example-based SR constraints. If enough patches are found Equation (1) becomes fully determined for a particular pixel. Otherwise a least-squares approach can be used. Figure 5 shows a graphical representation of how the patches are utilized.
Regarding the blur kernel Bl at level Il Glasner et. al. show that for a uniform scale factor sl we are guaranteed that if two images in the cascade are found m levels apart (e.g. Il and Il+m ) they will be related by the same blur kernel Bm regardless of l.
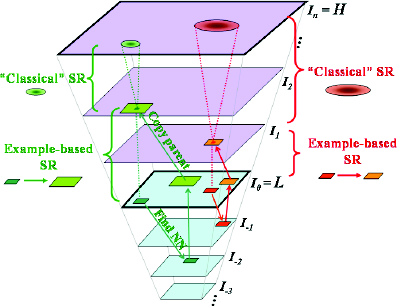
Figure 5: Graphical representation of how patches are copied between scales of the image cascade. Image from D. Glasner, S. Bagon, M. Irani.
Implementation Details
We make a number of simplifying assumptions to the algorithm in order to ease implementation and computation time. Firstly, we restrict our algorithm to grayscale images only. Secondly, we only implement 2x magnification levels. For the 4x results we simply run the algorithm once to produce a 2x magnification, then again on this result to produce the 4x magnification.
For the majority of our tests we use 5x5 patches spaced at one-pixel intervals throughout the image. Nearest neighbor patches are found brute-force using sum-of-squares distance metric. To improve this implementation we would utilize an approximate nearest-neighbor method in the future. A cross-scale match is considered if the SSD falls below some threshold, we used 100 for most of our experiments.
Rather than solving the linear equations explicitly we use a gradient-based method similar to that found in M. Ji, B. An. Although we extend their framework by utilizing more than 3 constraints. For our implementation we find the closest cross-scale nearest neighbor patch along with up to 9 in-scale nearest neighbors.
Results
We ran the above implementation on a set of grayscale images. The results are compared to nearest neighbor and bicubic interpolation. We provide results for 2x and 4x magnification levels. Overall we find that 2x magnification provides little improvement over the baseline methods. However the unified framework degrades less severely at 4x magnification.
| 4X MAGNIFICATION | |||
| Input | Single-Image SR | Nearest Neighbor | Bicubic Interpolation |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
| 2X MAGNIFICATION | ||
| Input |  |
 |
| Single-Image SR |  |
 |
| Nearest Neighbor |  |
 |
| Bicubic Interpolation |  |
 |
To demonstrate the efficacy of patch redundancy we super-resolve an image by 4x magnification using only cross-scale patches. The result is below. We see that a considerable amount of the image is super-resolved using only information derived from lower scales.

References
D. Glasner, S. Bagon, M. Irani. Super-resolution from a single image. ICCV, 2009.
W. Freeman, T. R. Jones, and E. C. Pasztor. Example-based super-resolution. Comp. Graph. Appl., (2), 2002.
M. Ji, B. An. EE264 Final Project Report: Super-resolution from a single image. 2010.