
Ahhhh! Space Invaders!
Space Invaders is an arcade video game that was popular in the late 70's and early 80's. It is one of the earliest shooting games; the goal is to mow down waves of aliens with a laser cannon, earning points in the process.
But this project isn't about Space Invaders -- it's Space Invaders-inspired. Let's suppose the year is 2014. The United Federation of Sino-Finnish Nation States has established a robot colony on the distant planet of ML141. (2013 was an eventful year.) But then some aliens show up! Some of these aliens are aggressive, while others are friendly. The robots don't know how to respond. They take a sequence of pictures of the aliens and transmit them back to Earth. They also transcribe the speech of the aliens. Your job is to train classifiers to make sense of these data, helping the robots learn how to respond to the alien threat.
Due to the great distance between ML141 and Earth (let's ignore any logical inconsistencies having to do with the speed of light, and just in general), the images you receive from the robots have become corrupted. Some of the pixels have been flipped from their original values. The first batch of images came with labels identifying the type of alien in each picture. However, since identifying the type necessitates coming into close contact with the sometimes-aggressive aliens, the robots would prefer to be able to identify the aliens from afar, with just the image data.
This is where you come in. You will implement three different machine learning classification algorithms. They are, sorted in order of simplicity, k-nearest neighbors, a decision tree, and logistic regression.
K-nearest neighbors is a simple algorithm for classifying objects based on the training examples from the feature space. In our case, the features are the pixel values, which are either 0 or 1. (Those of you with some experience in machine learning or computer vision might be able to cook up some additional features from the images; we ask that you not.) To classify a new alien image, k-NN calculates the "distance" from this image to the training images. It classifies the new image as belonging to the same class as the class most common to the k closest training images.
You are responsible for filling in the classify(x, k) method in the KNN class. (5 points)
A decision tree is a predictive model for classifying objects based on labeled training examples. We covered decision trees pretty thoroughly in class, so that's all we'll say about them here.
UPDATE: Actually, we will say more about decision trees here. The best feature is the feature that maximizes information gain, which is IG(T, a) on the wikipedia page. In that equation, H(T) is the entropy of the y-values of the data. (I.e., y is the random variable. Then use the definition of entropy.) Sorry if there was any confusion, since information gain wasn't explicitly covered in class.
You are responsible for filling in the methods split_node(feature_index, feature_vals) and best_feature() in the class TreeNode. (15 points) You should study the methods make_tree() and classify() to see how the two methods you'll implement are used.
As you learned in class, logistic regression is a probabilistic method for classifying objects as belonging to one of two classes. However, it can also be extended to more than two discrete outcomes. This is called multinomial logistic regression.
There are several equivalent ways to formulate multinomial logistic regression. One is to define a weight vector w_k for each class k. Then the probability that a vector x belongs to class k is given by:
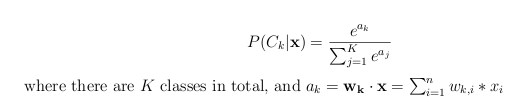
There are also several ways to train the classifier -- i.e., to compute the weight vectors given the labeled training data. In class Prof. Littman talked about minimizing a loss function. We'll use a different method, called maximum a posteriori (MAP) estimation. In this method, to avoid overfitting, we define a prior likelihood function for each of the K weight vectors. Using this prior, P(w_k), we choose the values of the weight vectors that maximizes the posterior distribution of the vectors:
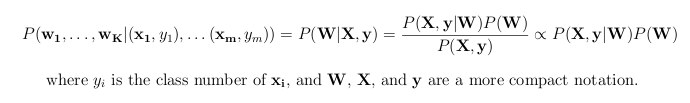
If the prior of each weight vector is Normal(0, S) (using a Normal prior is called L2-regularization), where certain assumptions are made about the covariance matrix S, and we take the log of P(W|X, y) (a common trick to avoid numerical underflow issues), we get:
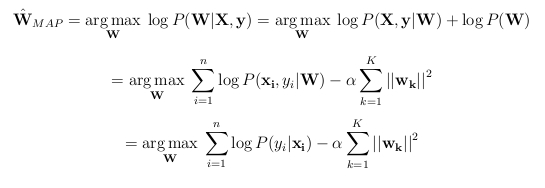
Don't worry about memorizing the steps of that derivation. Just understand that W_MAP is the MAP estimate of the weight matrix (whose rows are the weight vectors), and that W_MAP is derived from simple probability principles.
Your job is to implement logistic regression. You should compute the weights using L2-regularization. Specifically, you are responsible for filling in the methods compute_prob(x, W, classnum) and compute_weights(alpha) in the LogisticRegression class. (15 points)
Note 1: We highly recommend that you use a minimization function from scipy.optimize.
Note 2: We also recommend using numpy arrays instead of Python lists in some places. This isn't essential though.
Note 3: Depending on your computer's performance and the minimization function used, computing the weights may take a long time. It may also take only a few minutes or less. For debugging purposes, you can speed this up by decreasing num_features in the __init__ method or by sampling a subset of the training images before computing the weights. Using, say, 10 images per alien class will drastically speed up the computation.
Perhaps more important than being able to tell the different types of aliens apart is being able to tell if an alien is aggressive or not. Fortunately all aliens speak the same rudimentary language. They have a vocabulary of ten words, and there is no syntax or grammar per se. However, the order of words could have some correlation with the alien's mood. And there could be other significant characteristics too. Your task is to transform the transcribed sentences into features that are amenable to a classification algorithm. You should do some simple "data exploration," searching for features that seem to differentiate the two types of sentences. For instance, if you were trying to classify whether an image is of something hot or something cold, then you might use a binary feature capturing whether the majoriy of the pixels are "warm colors." (The features need not be binary; you could also use a count of the number of warm color pixels or the percentage of warm color pixels.) After extracting the features, using one of the algorithms from the first part, you should build a classifier that predicts whether a new sentence is uttered by an aggressive or friendly alien. Note that for extra credit (5 points) you can instead choose to implement a different type of classifier, such as naive Bayes.
More specifically, you are responsible for filling in the methods extract_features(X, y) and classify(x) from the SpeechClassifier class. (10 points)
NOTE: You should do "data exploration" on the training data outside of this method -- either on your own in the python shell or in a separate function or method -- to pick out which features to use. extract_features should just convert from the raw data to whatever features you decide on. So perhaps it should have been named "convert_to_features"...In any case, please be certain that extract_features converts the testing data from raw data to features in the same way that it converts the training data.
For instance, let's say the problem was instead to classify email as spam or not spam. Let's say the only feature you use is the presence of certain spammy words -- like "viagra," "gold," etc. extract_features should just transform the email into features using the spammy words you picked. To actually pick the words, you might write a method find_spammy_words, that examines the training data and picks out words most frequently used in spam email. Alternatively, you might examine the training data in the Python shell.
The stencil code is located in /course/cs141/pub/src/space_invaders. You should only modify classifiers.py, but you should also look in features.py. It contains two classes, ImageFeatures and SpeechFeatures. ImageFeatures has a few methods that could be useful.
Unfortunately there's no "game-play" mode to this project. You'll have to interact with the code from a Python shell. To do so, copy /space_invaders onto your own machine, cd into your_machine/space_invaders, and type python. To make a classifier object (e.g. KNN), type >>> import classifiers and >>> knn = classifiers.KNN([path_to_training_images]). From there you can access the classifier object's attributes and methods. (All of this is probably obvious, but we're just trying to cover our bases since there is currently no way to simply run the program from terminal.) You can test your classifiers' performance by running python classify.py.
Finally, note that YOU MUST INSTALL NUMPY AND SCIPY. The stencil code uses them. They can be downloaded from here: http://www.scipy.org/Download.
You will be graded according to the testing accuracy of your classifiers. We will be testing your classifiers on withheld testing data. We will provide a small number of images and sentences for you to test on in /aliens/test and /speech/test, but these are different from the data on which we'll test. We will release target numbers for testing accuracy.
UPDATE: Here are the target performances. This is how well our implementation runs on the full set of testing data. Numbers for the limited set of testing data available in /course/cs141/pub/src/space_invaders should be similar.
Note: you should be able to run the newest version of classify.py (updated April 24 at 12:30 p.m.) in under 45 minutes on a department machine. Make sure you can do this before submitting your project.
The command is cs141_handin space_invaders. You only need to turn in classifiers.py along with a readme declaring anything we should know such as requiring python2.7.