Lecture 24: Networking, RPC, and Sharding
» Lecture video (Brown ID required)
» Lecture code
» Post-Lecture Quiz (due 11:59pm Tuesday, May 3)
Networking system calls
A networking program uses a set of system calls to send and receive
information over the network. The first and foremost system call is called
socket(). It creates a "network socket", which is the key
endpoint abstraction for network connections in today's operating systems.
socket(): Analogous topipe(), it creates a networking socket and returns a file descriptor to the socket.
The returned file descriptor is non-connected -- it has just been initialized
but it is neither connected to the network nor backed up by any files or
pipes. You can think of socket() as merely reserving kernel state for a
future network connection.
Recall how we connect two processes using pipes. There is a parent process
which is responsible for setting everything up (calling pipe(), fork(),
dup2(), close(), etc.) before the child process gets to run a new program
by calling execvp(). This approach clearly doesn't work here, because there
is no equivalent of such "parent process" when it comes to completely
different computers trying to communicate with one another. Therefore a
connection must be set up using a different process with different
abstractions.
In network connections, we introduce another pair of abstractions: a client and a server.
The client is the active endpoint of a connection: It actively creates a connection to a specified server. Example: When you visit
google.com, your browser functions as a client. It knows which server to connect to!The server is the passive endpoint of a connection: It waits to accept connections from what are usually unspecified clients. Example:
google.comservers serve all clients visiting Google.
Client- and server-sides use different networking system calls.
Client-side system call -- connect
connect(fd, addr, len) -> int: Establish a connection.fd: socket file descriptor returned bysocket()addrandlen: C struct containing server address information (including port) and length of the struct- Returns 0 on success and a negative value on failure.
Server-side system calls
On the server side things get a bit more complicated. There are 3 system calls:
bind(fd, ...) -> int: Picks a port and associate it with the socketfd.listen(fd) -> int: Set the state of socketfdto indicate that it can accept incoming connections.accept(fd) -> cfd: Wait for a client connection, and returns a new socket file descriptorcfdafter establishing a new incoming connection from the client.cfdcorrespond to the active connection with the client.
The server is not ready to accept incoming connections until after calling
listen(). It means that before the server calls listen() all incoming
connection requests from the clients will fail.
Among all these system calls mentioned above, only connect() and accept()
involves actual communication over the network, all other calls simply
manipulate local state. So only connect() and accept() system calls
can block.
Differences between sockets and pipes
One interesting distinction between pipes are sockets is that pipes are one way, but sockets are two-way: one can only read from the read end of the pipe and write to the write end of the pipe, but one are free to both read and write from a socket. Unlike regular file descriptors for files opened in Read/Write mode, writing to a socket sends data to the network, and reading from the same socket will receive data from the network. Sockets hence represents a two-way connection between the client and the server, they only need to establish one connect to communicate back and forth.
Connections
A connection is an abstraction built on top of raw network packets. It presents an illusion of a reliable data stream between two endpoints of the connection. Connections are set up in phases, again by sending packets.
Does all networking use a connection abstraction?
No, it does not. Here we are describing the Transmission Control Protocol (TCP), which is the most widely used network protocol on the internet. TCP is connection-based. There are other networking protocols that do not use the notion of a connection and deal with packets directly. Google "User Datagram Protocol" or simply "UDP" for more information.
A connection is established by what is known as a three-way handshake process. The client initiates the connection request using a network packet, and then the server and the client exchange one round of acknowledgment packets to establish the connection. This process is illustrated below.
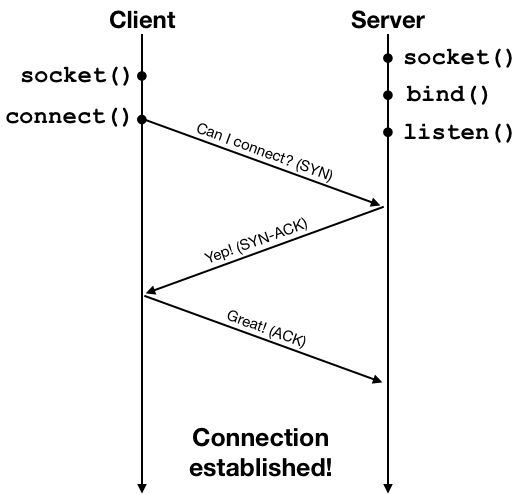
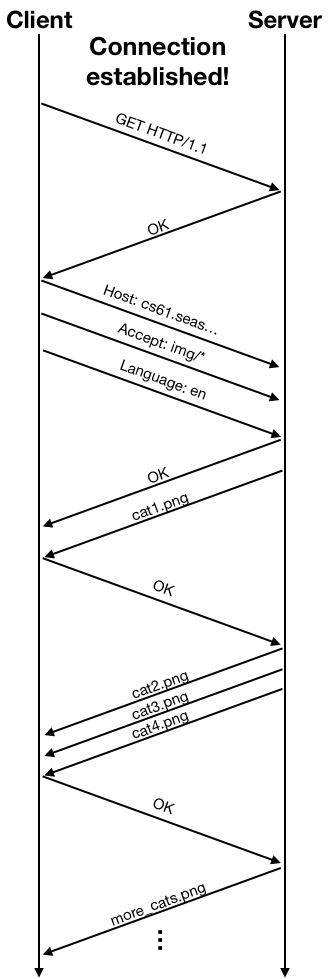
Once the connection is established, the client and the server can exchange data using the connection. The connection provides an abstraction of a reliable data stream, but at a lower level data are still sent in packets. The networking protocol also performs congestion control: the client would send some data, wait for an acknowledgment from the server, and then send more data, and wait for another acknowledgment. The acknowledgment packets are used by the protocol as indicators of the condition of the network. The the network suffers from high packet loss rate or high delay due to heavy traffic, the protocol will lower the rate at which data are sent to alleviate congestion. The following diagram shows an example of the packet exchange between the client and the server using HTTP over an established connection.
Remote Procedure Call (RPC)
Using network connections and sockets directly involves programming against a byte stream abstraction. Both the server and the client code must encode application messages into bytes and manage delimiting messages (e.g., by prepending them with a length, or by using terminator characters). This requires a lot of "boilerplate" code – for example, about 80% of the lines in WeensyDB relate to request parsing and encoding.
Remote Procedure Call (RPC) is a more convenient abstraction for programmers. An RPC is like an ordinary function call in the client, and like a callback on the server. In particular, RPCs hide the details of the encoding into bytes sent across the network (this is called the "wire format") from the application programmer, allowing application code to be separated from protocol details, and affording the flexibility to change the underlying protocol without having to change the application.
RPCs are often implemented via infrastructure that includes automatically-generated stubs, which take care of encoding operations into the wire format, managing network connections, and handling (some) errors. An example of a widely-used RPC stub compiler is gRPC, an RPC library from Google (others, such as Apache Thrift also exist), which works with the Protocol Buffers library (a library that provides APIs for encoding into different wire formats, such as efficient binary representations and JSON) to generate efficient and easy-to-use RPC stubs. You will use both gRPC and Protobufs in Lab 8 and the Distributed Store project.
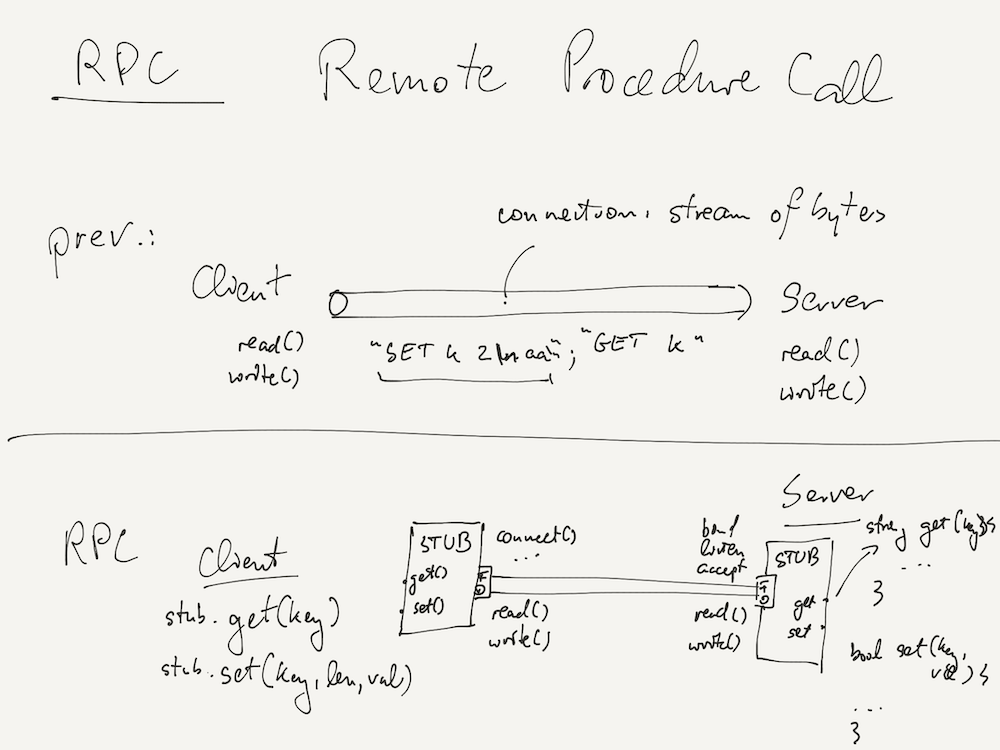
As an example, consider how WeensyDB with RPCs works (see the picture above): rather than encoding
GET and SET requests as strings with newlines and spaces as delimiters, an
RPC-based WeensyDB would use generated stubs to expose a get(key)/set(key,
value) API on the client. When the client application calls these functions, it calls into
generated stub code, which encodes the request in whichever wire format makes sense, and sends the data
to the server via a network connection (which the generated stub also initiates via the socket syscalls
and whose file descriptors (FDs) it manages). On the server side, the receiving stub code calls
developer-provided implementations of the get() and set() functions, and takes
care to send any return values back to the client via the network connection.
Sharding
WeensyDB is a distributed system with many clients and a single server. But in some settings, a single server is not sufficient to handle all the requests that users generate. Such settings include popular web services like Google, Facebook, Twitter, or Airbnb, which all receive millions of user requests per second &nash; clearly more than a single server can handle. This requires scaling the service.
Vertical vs. Horizontal Scalability
When we talk about scalability, we differentiate between two different ways of scaling a system.
Vertical scalability involves adding more resources to scale the system on a single computer. This might, for example, be achieved by buying a computer with more processors or RAM (something that is pretty easy – if expensive " on cloud infrastructure like AWS or Google Cloud). Vertical scalability is nice because it does not require us to change our application implementation too much: simply adding more threads to a program is sufficient to handle more requests (assuming the computation was parallelizable to begin with).
But the downside of vertical scalability is that it faces fundamental limits: due to the physics of energy conservation, heat dissipation, and the speed of light, a computer cannot have more than a certain number of processors (in the hundreds with current technology) before it runs too hot or would have to slow down processor speed significantly. This puts a practical limit to how far we can scale a system vertically. Another limit (but sometimes also a benefit) is that a vertically-scaled system is a single fault domain: if it loses power, the entire system turns off. This can be a problem (a website run from this computer no longer works), but – as we will see when we discuss the alternatives – also avoids a lot of complexity associated with more resilient distributed systems.
The alternative is horizontal scaling, which works by adding more computers to the system (i.e., making the server itself a distributed system). This is easy to do in principle: public cloud platforms allow anyone with a credit card to rent hundreds of virtual machines (or more) with a few clicks. This provides practically unlimited scalability, as long as we can figure out a way to split our application in such a way that it can harness many computers. (It turns out that this split, and issues related to fault tolerance, really add a lot of complexity to the system, however.)
Sharding: splitting a service for scalability
To use multiple computers to scale a service, we need a way to split the service's work between many computers. Sharding is the term for such a split: think about throwing our system on the floor and seeing it break into many shards, which are independent but together make up the whole of the system.
To shard a system, we split its workload along some dimension. Possible dimensions include splitting by
client, or splitting by the resource that a client seeks to access (e.g., in an RPC). When you talk to a
website like google.com, you and other users access the same domain name, but actually talk to
different computers, both depending on your geographic location and based on a random selection implemented
by the Domain Name System (DNS) server for google.com. This "load balancing" is a
form of sharding by client: different front-end servers in Google's data centers receive network connection
requests from different clients, based on the IP address that google.com resolved into for each
specific client.
But sharding by client requires that every server that a client might talk to be equally able to handle its requests. This is pretty difficult to ensure in a practical distributed system. Consider WeensyDB: if we were to shard it by client, every server would need to be able to serve requests for every single key stored in the WeensyDB. A better alternative for this kind of stateful service is to shard by resource (i.e., by key in the case of WeensyDB).
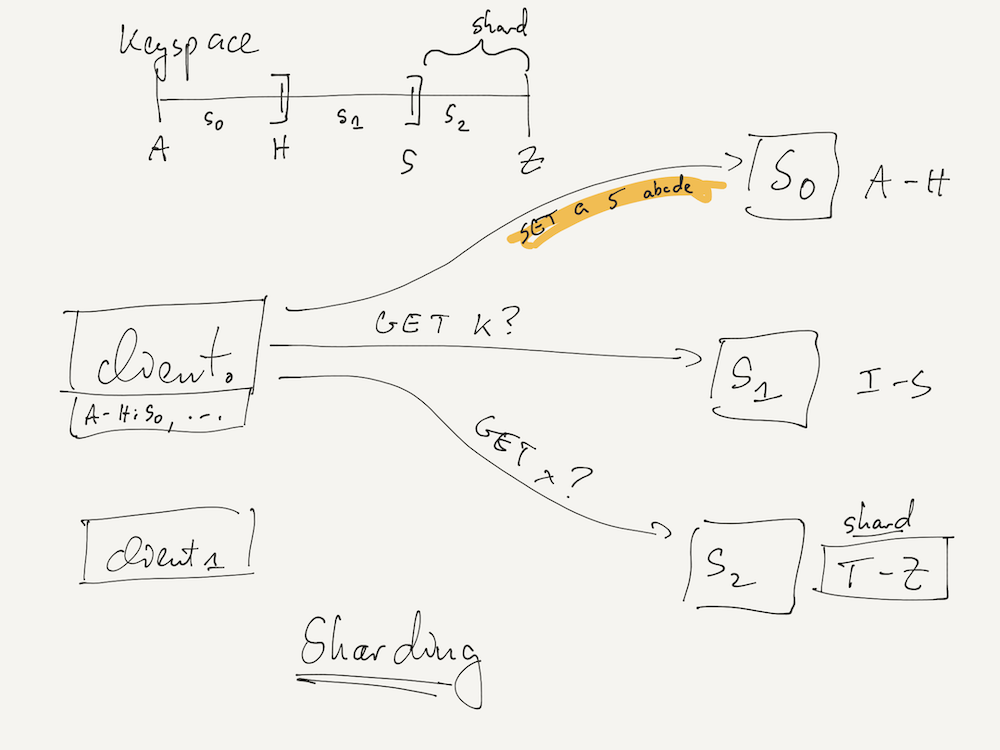
In practice, this sharding might be realized by splitting the key space of WeensyDB's keys (which are strings) into different regions ("shards") assigned to different servers. In the picture above, server S0 handle keys starting with letters A-H, while S1 handles those starting with I-S, and S2 handles T-Z.
To make this sharding work, the client must know which server is responsible for which range of keys. This assignment (the "sharding function") is either hard-coded into the client, or part of a configuration it dynamically obtains from a coordinator system (in the Distributed Store project, this coordinator is called "shardmaster").
A properly sharded service scales very well, since we can simply add more servers and split the key ranges assigned to a shard in order to add more capacity to the system. But there are some edge cases: for example, many social media services have highly skewed key popularities, leading to a few popular keys (e.g., the timeline for a celebrity user) to receive a disproportionaly larger number of requests than others. This means that keys and the load they induce are no longer equal, and the sharding must take this into account.
Summary
Today, we learned the sequence of system calls that computers acting in the client and server roles use to establish network connections. We also covered two key ideas in distributed systems: RPCs and sharding.
RPCs help making it easier for programmers to write distributed systems code, since auto-generated RPC stubs prevent the application programmer from having to implement byte stream-level protocol code by hand. Instead, an operation on a remote server feels just like a function call from the application perspective.
We looked at WeensyDB, a simple networked key-value store. WeensyDB is similar to real-world key-value stores such as memcached, Redis, or RocksDB.
We then talked about how to scale a system using using a key technique, sharding. A sharded system partiions its state along some dimension, allowing different servers to maintain independent slices ("shards") of state.
