Designing with datatypes, tree intro
Enumerating possibilities
Datatypes with multiple constructors are useful when a type has multiple variants. One way to use them is to enumerate a small set of possible values. For instance, we’ve been using strings to indicate TODO urgency, but we could instead define a datatype:
data Urgency: | high | medium | low end
We can then convert these to strings:
fun urgency-to-string(urg :: Urgency) -> String: cases (Urgency) urg: | high => "high" | medium => "medium" | low => "low" end end
What advantages does this approach have? What about disadvantages?
Exercise: data design for a game
Let’s say we are developing a game using Pyret’s reactors (which is exactly what you’ll be doing for project 2!). In the game, a human controlled by the player is trying to avoid an alien. Here are two possible representations of the state of the game:
data Posn: | posn(x :: Number, y :: Number) end # Option 1 data GameState: | state(human-posn :: Posn, alien-posn :: Posn) end # Option 2 data GameState: | human(p :: Posn) | alien(p :: Posn) end
Which one should we use?
For this game, we need to use the first representation: we always have both an alien and a human, each of which has a position. If we had either an alien or a human, we’d use the second representation.
Lists are datatypes
As it turns out, lists are defined in Pyret as datatypes! Can we figure out what the constructors look like? Here’s one of the list functions we developed earlier in the semester:
fun my-sum(l :: List<Number>) -> Number: cases (List) l: | empty => 0 | link(fst, rst) => fst + my-sum(rst) end end
Can we figure out what the datatype definition looks like by looking at this function?
We know it will have two cases, empty and link:
data List: | empty | link(...) end
What are the components of a link?
data List: | empty | link(fst, rst :: List) end
Ancestry data
Imagine we’re trying to do a genealogy project–we’re looking at eye color heritability. Our data are from the 18th-century House of Hanover; specifically, the family tree of King George III of the United Kingdom. Here’s a chunk of the tree:
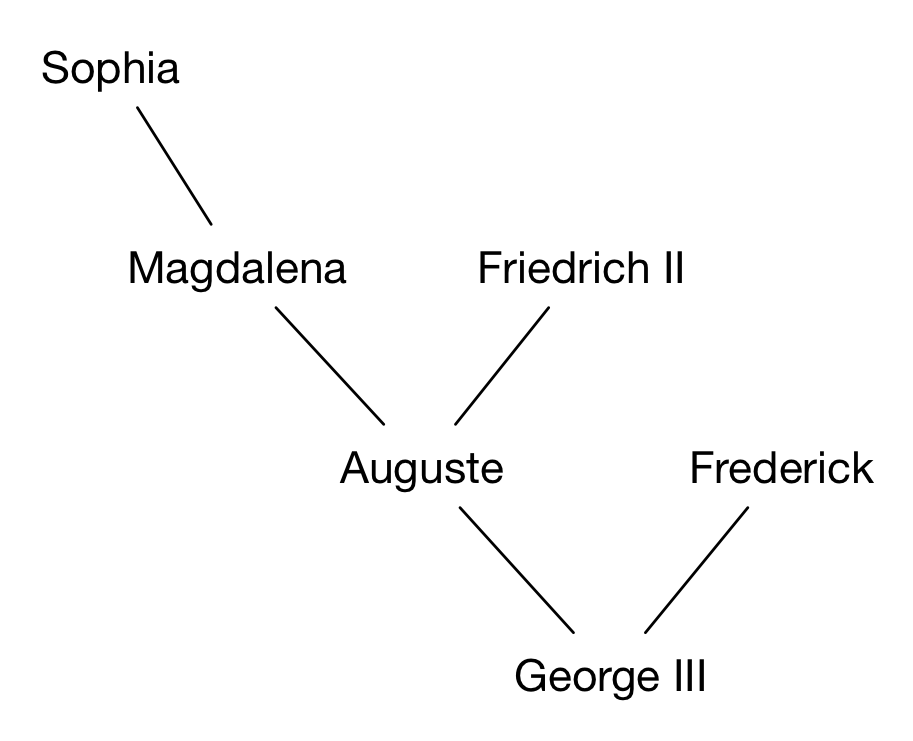
How would we represent these data? We could use a table:
| name | eye-color | mother | father |
|---|---|---|---|
| “George” | “green” | “Auguste” | “Frederick” |
| “Auguste” | “green” | “Magdalena” | “Friedrich II” |
| “Frederick” | “brown” | “” | “” |
Let’s say we want to write a function to get someone’s grandparents. How would we do it?
We’d have to first get parents, then get grandparents. Each would involve filtering the table based on name, and dealing with empty data (e.g., if a parent field is empty then we can’t get the grandparent). We could do it, but it would be unpleasant.
Next time, we’ll see how to use datatypes to solve this problem in a cleaner way.