Some Final-Exam Practice Questions
This set of questions does not cover everything you might see on the exam. Nor are we suggesting that these are actual potential exam questions (though they touch on many of the possible question types listed in the exam prep guide). More, these questions are designed to let you practice material that we haven’t seen in a while, that could show up on the exam.
Solutions are in a separate file.
Working with Tables
You are working for a public health organization that is concerned about the spread of malaria. The organization has been working in a particular town, distributing mosquito nets to some homes.
The team is trying to create a formula (a.k.a. a model) that will predict which homes are most likely to have people infected with malaria. Currently, they believe that:
- those living within 500 feet of the lake but without mosquito nets have the highest risk,
- those living between 500 and 2000 feet from the lake without nets have medium risk, and
- those more than 2000 feet from the lake have low risk (whether or not they have nets).
This diagram shows their prediction visually.
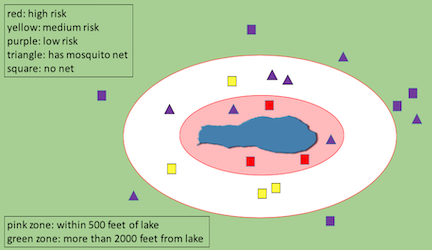
The team is storing their research data in a table. The table has one row for each home, and columns that indicate each home’s distance from the lake and whether it has mosquito nets.
Here’s the initial table that the team received from a previous organization that was working (unsuccessfully) on this problem:
HouseID dist nets?
-----------------------------------
1 250 yes
Amy's 600 false
2 1 mile no
-
What problems do you see in the initial table?
-
Which types should each column contain to best enable future computation?
-
To what extent could you clean up the table with programs, versus manual edits? You don’t need to write these programs, but describe the programs you would write if you were asked to actually clean this up.
Eventually, the table will also need to contain two more pieces of information: (1) a prediction of whether people in the house will contract malaria, and (2) data on whether people in the house did actually contract malaria. The team could then contrast these two pieces of information to see whether their formula/model is accurate (which would in turn tell them where to distribute mosquito nets).
-
How might someone obtain the additional information (prediction and real data)? Which data can be computed, which come from other tables, which must be gathered by other means?
-
Assume the initial table is stored in a variable named malaria-data. Write an expression that produces a table that also has the prediction information.
As a reminder, the tables operations are:
filter-by(table, row -> bool) -> tablesort-by(table, colname, true-if-ascending-order) -> tabletransform-column(table, colname, row -> value) -> tablebuild-column(table, colname, row -> value) -> tabletable.select-columns(list[colnames]) -> table
Also, you access a cell by writing `row[“colname”]``.
-
Assume the malaria-data table has been modified to hold the prediction and real data. What might you do with the table/data to get an initial sense (so not fully analyzed, just a first pass) of whether the formula is a good predictor?
Working with Trees
Recall the datatype for ancestor trees that we developed earlier in the semester:
data AncTree:
| person(
name :: String,
eye :: String,
mother :: AncTree,
father :: AncTree )
| unknown
end
-
Write a program that determines whether everyone in a given tree with the name “John” has a given eye color.
fun john-eyes(t :: AncTree, c :: color) -> Boolean:
...
end
-
Write a good set of tests for a program that checks whether every person shares their eye color with one of their parents. You may draw the trees as pictures (rather than write them in code). You don’t have to write the function, just the tests.
-
Consider the following AncTree:
tree1 = person("Bearna", "brown",
person("Bluno", "blue", unknown,
person("Carter", "brown", unknown, unknown)),
person("Josiah", "blue",
person("Miekie", "green", unknown, unknown),
unknown))
Assume you evaluate the expression john-eyes(tree1). At the point where the function is called on the person named Carter, what do the program dictionary and memory look like?
-
Someone is trying to write a program to return the longest name in an ancestor tree (or one of the longest in case of a tie). So far, they have the following code:
fun longest-name(t :: AncTree) -> String:
doc: "produce the longest name in the given tree"
cases (AncTree) t:
| unknown => "none"
| person(n, e, m, f) =>
if string-length(longest-name(m)) > string-length(longest-name(f)):
longest-name(m)
else:
longest-name(f)
end
end
end
-
Without running the code (either in a computer or manually), does anything look suspicious, or do you expect this to work?
-
For each thing that looks suspicious, can you draw an example tree for which the code would produce the wrong answer due to what you observed?
-
Fix the code to produce the right answer
-
Comment on the run-time performance of your code. Do you see any work/computation/expressions that could be eliminated to make the code do fewer computations? If so, how would you change the code to avoid the extra work?
Some Final-Exam Practice Questions
This set of questions does not cover everything you might see on the exam. Nor are we suggesting that these are actual potential exam questions (though they touch on many of the possible question types listed in the exam prep guide). More, these questions are designed to let you practice material that we haven’t seen in a while, that could show up on the exam.
Solutions are in a separate file.
Working with Tables
You are working for a public health organization that is concerned about the spread of malaria. The organization has been working in a particular town, distributing mosquito nets to some homes.
The team is trying to create a formula (a.k.a. a model) that will predict which homes are most likely to have people infected with malaria. Currently, they believe that:
This diagram shows their prediction visually.
The team is storing their research data in a table. The table has one row for each home, and columns that indicate each home’s distance from the lake and whether it has mosquito nets.
Here’s the initial table that the team received from a previous organization that was working (unsuccessfully) on this problem:
What problems do you see in the initial table?
Which types should each column contain to best enable future computation?
To what extent could you clean up the table with programs, versus manual edits? You don’t need to write these programs, but describe the programs you would write if you were asked to actually clean this up.
Eventually, the table will also need to contain two more pieces of information: (1) a prediction of whether people in the house will contract malaria, and (2) data on whether people in the house did actually contract malaria. The team could then contrast these two pieces of information to see whether their formula/model is accurate (which would in turn tell them where to distribute mosquito nets).
How might someone obtain the additional information (prediction and real data)? Which data can be computed, which come from other tables, which must be gathered by other means?
Assume the initial table is stored in a variable named
malaria-data. Write an expression that produces a table that also has the prediction information.As a reminder, the tables operations are:
filter-by(table, row -> bool) -> tablesort-by(table, colname, true-if-ascending-order) -> tabletransform-column(table, colname, row -> value) -> tablebuild-column(table, colname, row -> value) -> tabletable.select-columns(list[colnames]) -> tableAlso, you access a cell by writing `row[“colname”]``.
Assume the
malaria-datatable has been modified to hold the prediction and real data. What might you do with the table/data to get an initial sense (so not fully analyzed, just a first pass) of whether the formula is a good predictor?Working with Trees
Recall the datatype for ancestor trees that we developed earlier in the semester:
Write a program that determines whether everyone in a given tree with the name “John” has a given eye color.
Write a good set of tests for a program that checks whether every person shares their eye color with one of their parents. You may draw the trees as pictures (rather than write them in code). You don’t have to write the function, just the tests.
Consider the following
AncTree:Assume you evaluate the expression
john-eyes(tree1). At the point where the function is called on the person named Carter, what do the program dictionary and memory look like?Someone is trying to write a program to return the longest name in an ancestor tree (or one of the longest in case of a tie). So far, they have the following code:
Without running the code (either in a computer or manually), does anything look suspicious, or do you expect this to work?
For each thing that looks suspicious, can you draw an example tree for which the code would produce the wrong answer due to what you observed?
Fix the code to produce the right answer
Comment on the run-time performance of your code. Do you see any work/computation/expressions that could be eliminated to make the code do fewer computations? If so, how would you change the code to avoid the extra work?