Daniel Dadush
Zeke Swepson
Janete Perez
Neil Mehta
CS196-2
– Innovating Game Development –
Course
Project Proposal
Kung
Fu Tamagotchi
1
Storyboard and Conceptual Images
Title:
Kung Fu Tamagotchi
Tagline:
Mr Myagi
Evolved
Genre:
RPG & Fighter.
Mechanics:
Tamagotchi
meets Soul Calibur
Setting:
Medieval
meets Futuristic
Target Audience:
“soccer mom ”, Japanese teenager
Goal:
Create
the ultimate fighting machine.
Description:
You get to
train a young budding fighter how to fight. You get to make your own, original
PHYSICS BASED MOVES. You get to pit your Kung Fu Tamagotchi against your
friend’s to show them who the real Mr. Myagi is.
It is innovative because...
It’s a
physics based fighting simulation where your trainee learns from you and from
experience in fights. You get to make your own moves which can be modified and
perfected. There is also the possibility of having the trainee make up his/her
own moves.
2 Project Software
Engineering
2.1
Analysis Phase: Statement of Requirements
Game Breakdown
Our game can be broken into 2 modes with one engine which
will be used in both modes. Each of
these modes is necessary for achieving the goal of training a fighter which is
the ultimate goal of the game.
The Engine:
Using the Dojo library the engine renders graphics,
simulates physics and calculates the game state for the AI. Since real 3D biped physics will be difficult
to implement we will use ragdoll physics to simulate marionette style
motion. In conjunction
with the physics engine which Dojo already has, the engine simulates “strings”
which pull the character into an upright position. In order to move these ragdoll characters we
simply apply forces to pull the parts in the proper direction.
Move Builder: Provides the users the ability to create their fighter’s own moves
The goal of the interface is to be as simple as
possible. To reduce the amount of work the
user has to do to create moves we’ve simplified the interaction from that of a
traditional 3D modeling program. To
select a limb there will be a drop down menu with a list of all the parts. Once you have selected a limb there are
sliders corresponding to the X, Y, and Z location of the limb. The coordinates will be relative to the
character so that the user can rotate the camera around the character while
they are manipulating its position. This
allows for much simpler manipulation of the body, but does not sacrifice the
level of precision required for complex move creation.
After the user is finished organizing the character in their
desired configuration they can add another configuration to add to the move or
they can chose a target limb on the opponents body to attack. An attack is specified by selecting an
attacking limb, the limb the player will attack with, and the limb to be
attacked on the enemy player.
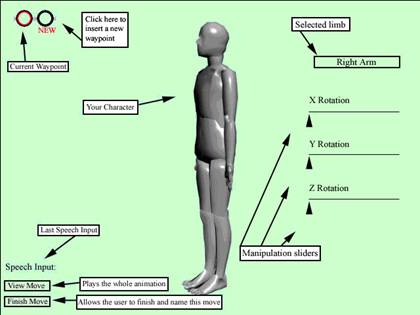
Initially the user can specify the type of move they are
creating. There are three basic types;
an attacking move, a move that will end with the player attacking his opponent;
a defensive move, a move that protects the player from an attack; and a
movement move, a move that actually changes the player’s position (i.e. step
left).
Moves can also be combined with each other to make
combination moves. The user can select
two moves and merge them either sequentially so that one happens directly after
the other or combine them as a double move (i.e. punch and kick
simultaneously).
To preview a move click the “View Move” button. This will simulate what the move will look
like during fighting mode. After the
user is satisfied with the move they have created they can click “Finish Move”
to finalize the move and add it to the list of moves the player can use when
fighting. At this point the user must
give the move a name and give it voice and key mappings for fighting mode.
Fighting Mode: User can apply moves to fight an opponent/fighter
learns how to fight
The interface for the fighting mode will be even
simpler. Since most of the fight will be
a simulation the only important information is player’s score and the time left
in the round (the two players fighting is a given). Most of the fighter’s learning will happen on
its own. The user can press keys which
are mapped to specific moves or give a vocal command to suggest move the
fighter might try, but ultimately the decision is up to the fighter
itself.
To assist with the reinforcement learning the user can also
positively or negatively reinforce what the fighter is doing either through
voice or through the keyboard.
Each fighter will have a score which will increase based on
the force and location of a successfully landed attack. The fighter with the
highest score at the end of the round wins.
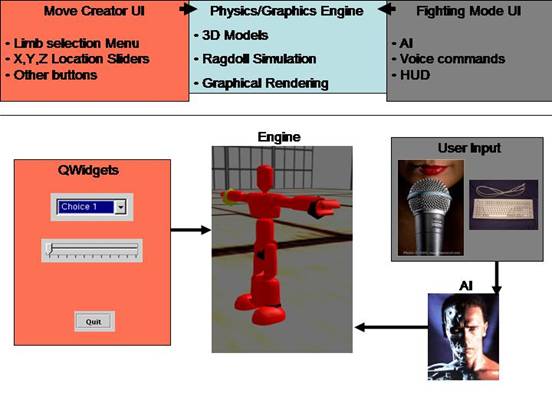
2.2 Design
Phase
Design
Overview:
For
development of our game we will be using the Dojo Game Engine. We will thus be coding in C++ using Microsoft
Visual Studio as our development IDE. As
mentioned previously the game is broken into 3 main components. The underlying physics engine, the move
creation system and the fighting simulation / learning mode.
Physics Engine:
The
engine will predominately build off of Dojo.
All the graphics and the physics simulation will be taken care of by G3D
and ODE respectively. The part we will
be responsible for is calculating the game state. Because it knows everything about the state
of the game it will have a lot of accessor functions for other classes (namely
the AI) to utilize the data.
Move Creator UI:
The move
creator UI will be using QWidgets for things like buttons and sliders. It will communicate with the engine via
surrogate classes which reference the different limbs of a fighter. Through the surrogates one can access the
coordinate data for the limbs and apply forces to move them.
Fighting Mode UI:
In
fighting mode the user interacts with the fighter either through voice command
or the keyboard. These commands are
suggested to the AI which will then choose a command to perform based on the
state of the game. As mentioned before
the state of the game is calculated by the Engine. When it has chosen a move the engine tells
the physics fighter what to do.
Depending on the success (i.e. Caused a lot of damage) or failure (i.e.
No damage or Received damage) of a move the AI will decide whether or not to do
that move again in that situation. To
achieve this we are going to attempt to implement a Q Learning algorithm.
2.3
Implementation Phase
Implementation
Engine:
In order
to simulate marionette physics there are a few key problems we need to
address. The first is the issue of
keeping the fighter upright or “standing up” (e.g. on his feet). A simple technique we have come up with is to
apply a force to the head of the fighter that is strong enough to oppose the
gravity which is pulling him down. This
worked surprisingly well as he not only remained standing but when knocked down
he could still pull himself up to a “standing” position.
The next
problem is how to move his limbs. We are
still in the process of figuring this out, but the basic idea we developed is
to create pull points or strings which are associated to each limb. The pull points apply a force to the
associated limb to pull it in the pull point’s direction. Effectively this moves the limb into a
desirable position to ready for a move.
The problem is that without much knowledge of physical motion (not to
mention there is no research that we found being done in such a specific area)
it’s still very sloppy and tends to yield awkward results. A few ideas we have had include adding
multiple pull points connected to the same limb to stabilize it and have finer
control; not activating all the pull points for each limb so some of the limbs
are “free” and others are in control of the desired motion; or giving the AI
more control over applying forces to the limbs based on the game state. As we experiment it is possible we will come
up with some sort of combination of several ideas.
AI Architecture:
The
objective of our AI is to decide the question: given the current game state
what move should I perform against my opponent? To make these decisions each
game state will have an associated set of move / reward values. The rewards on
each of the moves for the current state will inform us on how to choose the
next move. As time moves on the AI will learn the correct rewards for each move
through reinforcement learning techniques.
To incorporate
user input, we will give the user the ability to influence the reward function
and dictate the next move. Since the reward function will not depend on the
user’s input, we can see the user as a guide for the AI’s learning process.
Main Challenges:
Reward
function: Given that we want to make the AI behave in an interesting and
logical way, what reward function should we use to evaluate the benefit of a move
choice?
Updating
Rewards / Learning: Once we have observed the rewards of a particular sequence
of moves, how do we update their reward functions?
Finding
Associated Rewards: Once the relevant game state has been extrapolated, the AI
must find the associated rewards for each move at the current state. Since we
will probably not be explicitly storing all of the possible reduced game
states, we will need an efficient way to search through our stored state space
to find their associated rewards.
Choosing
the Next Move: Given a set of moves and their associated rewards, how do we
choose the next move?
Serializing
Rewards / Long Term Memory: Once a fight is over, the AI needs to remember what
it has learned to make the training process interesting and worthwhile.
Analysis / Implementation:
Game state
analysis consists of asking the question: what are the most representative and
revealing measures of the game state for AI processing? These measures will serve
as the “raw data” for the AI. Understanding what these measures are, and what
the relative importance of each measure is will be absolutely crucial to the
implementation of an effective AI.
We shall
first start by stating what the full game state can be said to consist of:
1) Positional Information: the position
of each player’s limbs with respect to their own body, the players’ relative
positions to each other, and their positions with respect to the current level.
2) Movement Information: the current
velocity and direction of each the player’s limbs and body, the different
forces being applied to each player.
3) Match Information: the time left in
the match, and the current score.
4) Decision Information: the current
move being executed by each player.
It is clear
that taking all this information into account at once would be overwhelming,
but luckily much of the information represented here is redundant and of
limited use to AI processing.
In our
current thinking, we want to devote our attention exclusively to positional and
match information. Here are our current reasons for excluding movement and
decision information from our analysis:
1) Movement information is very
uncertain within our system: the use of ragdoll physics makes the velocity and
directional information of many of the limbs inherently noisy and erratic
information.
2) The implications of movement
information depend on positional information. This is due to the fact that is
it hard to say anything about what an opponent is doing knowing his movement
information without knowing his positional information.
3) Movement information tends to add
little to what is already known from positional information. For example, by
the time the velocity and direction of a player’s fist accurately reveals the
intention to punch, the position of the fist should already reveal the same
information.
4) Knowing decision information is
“cheating”: if each player knew exactly what move the other player was
attempting we would have omniscient AI scenario, which we would like to avoid
if at all possible.
Clearly
since we want to have a finite state space, we will have to discretize all of
the measures we are using. Our basic idea is that there will be a bounding box
around both fighters that is cut into sub boxes which we will call regions. The
condensed game state will contain where each part of the fighter is within his
bounding regions. Next we will keep an appropriately discretized version of the
distance between the two players, and their relative orientations to each
other. Lastly we will keep track of each user’s score and the time left in the
round. We believe that with this information, we should have more than enough
data to create an effective AI.
Below is a
conceptual illustration of a player surrounded by his bounding box:
Reward Function:
The reward
function is what will ultimately guide the AI to improved strategies, and
therefore it must provide a very robust measure of performance. The choice of reward
function also considerably affects the complexity of the AI, so we must be very
careful in choosing it.
In our
case, we wish to use our underlying scoring mechanism directly in our objective
function. Since a match is won by the player who scores the most points, the
objective function we will use is the expected net increase in score over the
next T time units. The net increase in score denotes the increase in the
player’s score minus the increase in the opponent’s score. Our reason for using
a constant time horizon T is that we expect matches to have a rather regular
structure of the form: ready stance at medium distance, begin attack/defend
sequences, retreat to ready stance at medium distance, repeat. If we can
optimize our expected net increase in score over the period of a few such fight
sequences, we can expect to be near optimal.
The reason
we are choosing a timed round with scoring vs. standard deathmatch is because
we always want to give the AI time to learn. In a deathmatch setting, rounds
are usually short and mistakes potentially fatal so it is a very difficult
environment for trial and error reinforcement learning.
To
incorporate user input in this domain, we let the user add onto the observed
net change in objective by giving either positively or negatively reinforcing
signals. Hence if the user thinks that a particular sequence of moves the AI
performed was particularly good or bad, the user can add to or subtract from
the player’s current score directly. This change can be effectuated through the
use of the keyboard or through voice commands.
Updating Rewards / Learning:
The AI’s
ability to learn is based almost exclusively on its ability to dynamically
update the rewards for each (move / game) state pair. To implement this ability
to learn, we will use an adapted form of Q-learning.
In our
implementation, we will keep a list of the last T+1 move / game state pairs and
a list of the last T+1 changes in objective function. We shall call these lists
MGS_List and Obj_List respectively. We shall let a be our discount rate and b be our learning rate.
The
pseudo-code to update the reward function at the current AI time step is as
follows:
Objective_Delta
= 0
For i in
1..T
Objective_Delta = a^(i-1) Obj_List[i]
Reward[MGS_List[0]]
= (1-b)*Reward[MGS_List[0]] + b*Objective_Delta
Assuming
that we are at time S+T, this pseudo code properly updates the rewards for the
action executed at time S using the observed rewards over the next T time
steps. Here MGS_List[0] refers to the move / game state pair at time S, and
Reward[MGS_List[0]] is its associated reward.
Properly
tuning the discount and learning rate will clearly be very important to the
effectiveness of the AI, so we will have to heavily experiment with different
values.
The reason
we need to adapt the Q-Learning algorithm in this way is because the rewards of
our actions are not immediately visible. Given the nature of our objective
function though, we note that if we look at its change in value of a long
enough time period we should get an accurate result.
Finding Associated Rewards:
At every AI
time step, once we have extrapolated a condensed version of the game state we
need to find the associated rewards for the moves at that state. Even if we manage
to condense the state space to a size we can fully store in memory, we will
still need an efficient way to search the containing data structure.
The ways we
have thought about implementing this data structure is by either using a search
tree, a multi-dimensional array, or a hash table. Currently, we are more
inclined to use a search tree because it seems much more extensible than a
multi-dimensional array and far less “hacky” than a hash table.
To
implement the search tree, we would have the tree have a branch at each level
corresponding to the possible values of each variable in our condensed state
space. Each variable’s range would be appropriately discretized so as to be
able to group similar states together and to keep the memory requirements reasonable.
Each of the search tree leaves would correspond to a specific state and would
contain the associated rewards for each move at that state.
Here are
the reasons we have so far for choosing a search tree over the other two
options:
1) We can allocate memory as we need
it: we only store as many leaf nodes as we have seen states, also we don’t need
to store entries for potentially infeasible combinations of state variables.
2) A search tree can have variable
depth, which allows us to choose how much we think we need to specify the state
before we can make good decisions. This is extremely useful if, for example, we
put the distance between the two players as the first branch variable. In this
case, if the players are very far apart we don’t care about the rest of the
state and hence we can stop branching. This helps us from wasting a lot of
memory on essentially equivalent states.
3) Using a search tree, we are not
always forced to branch on the state variables in the same order. We can choose
to branch on the variables in a different order dependent on the values of
previous branches. This can allow us to maximize the amount of relevant
information learned at each branch.
4) Using a search tree we can
dynamically refine the discretization of a certain branch variables if we find
the previous discretization to be too coarse.
In terms of
the importance of a good condensation of the state space, I don’t think that it
can be too highly stated. As we are dealing with a finite time game where the
number of possible strategies is gigantic, it seems more reasonable to create a
system that can learn quickly than a system than can learn “optimally”. It
therefore seems wise to try and keep the state space as small and as meaningful
as possible, to allow the exploration phase of the reinforcement learning
process to proceed quickly.
Choosing the Next Move:
The crux of
the AI is its ability to learning enabled decisions. Our current idea for our
move selection algorithm is to select which move to perform next according to
probability distribution determined by the reward values.
Why do we
choose actions non-deterministically? The first reason is because we are in a
fighting scenario and therefore we cannot expect to find a deterministic
optimal solution. This becomes clear if we understand that once the opponent
learns which moves the optimal solution performs, the opponent will clearly
have enough information to beat it or make it ineffective. The second reason is
that we want to make sure explore as much of the action space as possible while
capitalizing on good moves, and the best way to do is non-deterministically.
How do we
create a probability based on the reward values? The techniques we will use
will first apply an order preserving transformation to the reward values such
that the resultant transformed reward vector is non-negative. Then we will
normalize the sum of this vector to one, and use the resultant values as the
probabilities for our distribution.
The easiest
way we know to do this is to take the initial reward vector R_i, where each i
corresponds to a different possible move, and transform it to R_i’ = exp(l*R_i), where l is any positive constant. This is
clearly an order preserving operation which turns R_i into a non-negative
vector. After we normalize R_i’ to sum to one, we will have a valid probability
distribution.
The user
can completely circumvent this move selection process though by specifying the
next move himself using either the keyboard or specific voice commands. In this
way, the user has a lot of control in guiding the AI’s learning process.
Serializing Rewards / Long Term Memory:
After a
match is over, the last task of the AI to remember what it has learned. In this
way, the user will truly be able to train the AI to become better over time.
Given that
the AI’s strategy is determined solely by the associated rewards for move /
game state pairs, if we serialize these rewards we can effectively save the
AI’s learned information. Since we will be storing these rewards in a search
tree for quick retrieval, the problem of serializing the rewards is simply one
of serializing the search tree.
We can
serialize the search tree by performing an in-order search of the tree and
printing out all the information for each node including parent information at
each step. Since the files we will be creating will not need to be human
readable, we don’t have to bind ourselves to using xml or any such technology
when saving the search tree to file. We can therefore make our serialization as
speedable as we want.
2.4 Testing Plan
Before we can begin work on the more complex portions of the
game we will need to set up a testing bed for each of the components. Most importantly we need to set up the
graphical interfaces. We will be spending
a lot of time at the beginning creating a barebones version of the 3D interface
which will be used for fight simulation and move creation. Initially what we will have will be very
limited in relation to the final desired product. The main goal is to be semi integrated from
the start. By semi integrated we mean
that the test bed implementations will remain static and should be easily
interchangeable with the actual parts.
We will be updating at an iterative rate. After the completion of an iteration we will
reintegrate the code as necessary.
Once the test bed is ready our approach will change to be
more focused around research and development.
Testing how libraries will interact with each other and our own code is
key. Since we are planning on using
several different libraries it will be important for us to understand how they
work before we can start building anything.
During this time we will also be researching techniques and
architectures which have already been implemented that are similar to what we
are trying to do. Some of this research
will be ongoing as some aspects will be more complex than others. We also anticipate there will be techniques
that will not work and we will need to research alternatives in advance.
When we are comfortable that we have a solid understanding
of the libraries we are using and what we will be coding ourselves we will
reevaluate our design and make necessary changes. At this point most of the code will have been
written. This stage will simply be
organizing and cleaning up as well as ironing out last minute bugs. At this stage we would like to have people
inside and outside the class beta test the game and give us suggestions on
improvements in interface and design.
In order to begin testing the AI we will need to set up a
significant amount of the Engine. To save time Zeke will be building a
simple test bed with two marionettes which can hit each other with different
limbs and move around. Meanwhile, Dan will be setting up the AI
framework. Once the framework is ready we will integrate it with the test
bed and he can begin testing his AI in a real environment. While Zeke and
Dan are working on those parts Neil and Janete will be focused on the User
Interfaces. Setting up the QWidgets to work with Dojo, saving and loading
moves and any other windowing issues that come up.
When the AI and Physics Engine are set up and mostly
functional we can begin integrating the two along with the UI. Because of
the time sensitivity of this project most of the testing will be done with the
real components which we will be using with the exception of the initial test
bed for the AI.
3 Project
Timeline/Milestones
Timeline
3/17 Physics/Graphics Engine: Very rough
marionette engine test bed done and ready for use.
3/24 Move
and Fighting UIs: First iteration interfaces ready for testing
Physics/Graphics
Engine: further explore marionette physics
AI:
outline basic AI architecture
3/31 Physics/Graphics
Engine: Iteration 2 marionette engine test bed
Prototype move creation system
implemented, ready for testing
Simplified
AI architecture implemented, ready for testing
4/7 Move
and Fighting UIs: Iteration 2 of 2D interfaces ready for testing
Testing
beds for UIs implemented and used
Implement
voice command system
Demo AI architecture in class, basic
learning technique modeled and executed by fighters.
4/14 Beta
marionette control ready for testing
Iteration 2 of move creation and AI
systems
Reevaluation
The Great Mergenation…
(Something like integration, but not…)
4/21 Meet
C Specs: Alpha version complete
4/28 Meet
B Specs: Beta version complete
5/5 Meet A Specs: final debugging session and testing.
5/12
4 Project
Rubric
Rubric
A specs
*Engine
The engine will properly renders
graphics, simulates physics and calculates the game state for the AI. Ragdoll physics simulate marionette style
motion accurately.
*Move Creator
All three types of moves can be created: attacking,
defensive, and position changing.
Moves can
be combined with each other and merged sequentially or in parallel.
Moves can
also be previewed and added to the list of moves already defined for a player.
The user can also provide key mappings
to be used during the fighting mode. Voice command mappings are optional.
*Fighting Mode
The user can press keys which are
mapped to specific moves or give a vocal command to suggest move the fighter
might try. Users can also provide positive or negative input to reinforce
learning. The fighter will make appropriate decisions based on user input and
learned behavior. The AI architecture for learning and decision making will
give AI fighters proper decision making ability that enables them to beat an
advanced human user.
B specs
*Engine
Same specs met as for A specs with debugging
needed: The engine will properly renders graphics, simulates physics and
calculates the game state for the AI. Minor errors may result from inaccurate
physics simulation and keeping track of the game state for the AI. Ragdoll physics simulate marionette style
motion with occasional bugs in reaction to fighter interaction.
*Move Creator
All three types of moves can be
created. Moves can only be merged sequentially, not in parallel. Moves can be
previewed for the most part with occasional rendering errors. Key mappings are
available for the user but not voice command mappings.
*Fighting Mode
User input and reinforcement isn’t always accurately
reflected in fighter’s moves.
AI architecture and learning
algorithm for the most part enable AI fighter to make proper decisions but can
only beat an average human user.
C specs
*Engine
The engine will does not properly
renders graphics(slow), simulates physics(inaccurate) or calculate the game
state for the AI. Ragdoll physics simulation of marionette style motion will be
implemented but very buggy leading to occasional crashes.
*Move Creator
At least two types of moves can be created.
Moves can only be merged sequentially. Moves can be previewed for the most
part. A limited number of key mappings are available for the user, no voice
commands. Move creation can’t handle waypoints or different stances
*Fighting Mode
B specs except: AI architecture is
simple and slow, can only beat novice human user.
4.1 Group
Workload Breakdown
This
breakdown should set individual rubrics for each person in the team and cover
all aspects of the overall project.
The workload
is broken down into teams of two. Zeke & Janete will be working on the move
creator aspect of the game and Dan & Neil will be working on the fighting
mode part. At each iteration we will reevaluate the workload and redistribute
tasks as necessary.
Move Creator: Zeke & Janete
User Interface: Janete
UI and
Graphics for the Move Creator.
A specs
- UI implemented effectively and
intuitive to use, responsive, few crashes.
- Graphics display properly
B specs
- UI is clunky and some features
aren’t implemented
- Graphics are slow and don’t work
well.
C specs
- UI not fully implemented
- Graphics are slow or don’t work
well
Marionette Simulation Engine: Zeke
A specs
- Character can do a complex move
with waypoints
B specs
- Character can only hit a specified
target
C specs
- Character moves in some way that
is close to what the user wanted
Fighting Mode: Dan & Neil
User Interface: Neil
UI and
Graphics for the Fighting Mode.
A specs
- UI implemented effectively and
intuitive to use, responsive, few crashes.
- Graphics display properly
B specs
- UI is clunky and some features
aren’t implemented.
- Graphics are slow and don’t work
well.
C specs
- UI not fully implemented
- Graphics are slow or don’t work
well
Learning AI : Dan
A specs
- AI learns quickly from mistakes
and improves its strategy to win fights.
B specs
- AI can learn slowly from mistakes.
C specs
- AI can make random decisions.
5 Selection and approval of a mentor
The proposed project must have a mentor
who is committed to provide guidance and conceptual support. The mentor can be
a member of the course staff or another individual, approved by the instructor,
with expertise in the area. The mentor must approve of the project before it
will be accepted by the course staff. The course website maintains a list of
potential projects suggested by individuals available to serve as mentors.
Alex Rice is our mentor TA for this project.
6 Related
Works
In the
most recent versions of popular fighting games like Soul Calibur, Tekken, and
Dead or Alive you can select the types of weapons a player can use, the stage,
and costumes. This type of customization and personalization provides users
with the ability to change the look and feel of players and fights but only on
a very high and imprecise level. Smackdown vs.Raw, for example, is a videogame
that has the ability to customize your player extensively. You can define the
character’s look as well as his entrance to the ring along with editing the
move set. There are moves for almost every possible situation: standing
grapples, running grapples and strikes, ground moves, rebounds, top rope moves,
etc.
While
these versions of recent fighting games give users a great deal of freedom,
users want more control of the actual game play and want to be able to
customize the moves and skills of a player instead of using the same
pre-packaged animations over and over. This has inspired the creation of
fighting games like Virtual Fighter with different modes where you can train
your own players. Virtual Fighter has an AI Mode that allows you to train a
“blank slate” fighter yourself. You can train the character in two ways: by
sparring to endow them with new moves, and by judging their abilities in
replay.
Our game
also uses ragdoll physics which is a type of procedural animation that has been
traditionally used to replace static death animations prepackaged in most video
games. Earlier computer games used these sequences of animation for characters
to take advantage of low CPU usage. Since we do not have this concern with the
increase in computer power then we can take advantage of the use of real-time
physical simulation in the creation of our game. A ragdoll is a collection of
multiple rigid bodies tied together by a system of constraints that restrict
how the bones may move relative to each other. Ragdoll Masters (link below)
uses this sort of simulation as well as Ragdoll Kungfu.
The main
algorithm we are using for our AI architecture is based on Q-learning. This is a
type of reinforcement learning technique that works by learning an action-value
function that gives the expected utility of taking a given action in a given
state and following a fixed policy thereafter. One of the strengths of this
type of reinforcement learning is that it is able to compare the expected
utility of the available actions without requiring a model of the environment.
We expect to do further research in this area of reinforcement learning to
further increase the effectiveness of our AI system.
http://www.tekken-official.jp/
http://www.virtua-fighter-4.com/
http://smackdown-vs-raw-game.com/
http://ragdollsoft.com/ragdollmasters/
http://en.wikipedia.org/wiki/Q-Learning
http://www.doc.ic.ac.uk/~nd/surprise_96/journal/vol2/zah/article2.html#Q
http://people.revoledu.com/kardi/tutorial/ReinforcementLearning/index.html