This tutorial is a modification of the first few sections of a popular Haskell tutorial, Learn You a Haskell for Great Good, found here. We (the CS195Y TAs) have tailored this version to the content and tone most appropriate for our course.
This tutorial is aimed at people who have experience in imperative programming languages (C, C++, Java, Python …) but haven't programmed extensively in a functional language before (Haskell, ML, OCaml, …).
Haskell is a purely functional programming language. In imperative languages you get things done by giving the computer a sequence of tasks and then it executes them. While executing them, the program can change state. For instance, you can set a variable a to 5 and then do some stuff and then set it to something else. You have control flow structures for doing some action several times. In purely functional programming you don't tell the computer what to do as such, rather, you tell it what stuff is. The factorial of a number is the product of all the numbers from 1 to that number, the sum of a list of numbers is the first number plus the sum of all the other numbers, and so on. You express that in the form of functions. You also can't set a variable to something and then set it to something else later. If you say that a is 5, you can't say it's something else later because you just said it was 5. So in purely functional languages, a function has no side-effects. The only thing a function can do is calculate something and return it as a result. At first, this may seem limiting, but it actually has some very nice consequences: if a function is called twice with the same parameters, it's guaranteed to return the same result. That's called referential transparency. Not only does it allow the compiler to reason about the program's behavior, but it also allows you to easily deduce (and even prove) that a function is correct and then build more complex functions by gluing simple functions together.
Haskell is lazy. That means that unless specifically told otherwise, Haskell won't execute functions and calculate things until it's really forced to show you a result. That goes well with referential transparency and it allows you to think of programs as a series of transformations on data. It also allows things such as infinite data structures.
Haskell is statically typed. When you compile your program, the compiler knows which piece of code is a number, which is a string, and so on. That means that a lot of possible errors are caught at compile time. If you try to add together a number and a string, the compiler will tell you. Haskell uses a very good type system that has type inference. That means that you don't have to explicitly label every piece of code with a type because the type system can intelligently figure out a lot about it. If you say a = 5 + 4, you don't have to tell Haskell that a is a number, since it can figure that out by itself. Type inference also allows your code to be more general. If a function you make takes two parameters and adds them together and you don't explicitly state their type, the function will work on any two parameters that act like numbers.
Haskell is concise. Because it uses a lot of high level concepts, Haskell programs are usually shorter than their imperative equivalents.
A text editor and a Haskell compiler. For the purposes of this tutorial we'll be using GHC, the most widely used Haskell compiler. It is already installed on the department machines, but if you want it for your own computer, the best way to get started is to download the Haskell Platform.
GHC can take a Haskell script (they usually have a .hs extension) and compile it, but it also has an interactive mode which allows you to interactively interact with scripts. You can call functions from scripts that you load and the results are displayed immediately. For learning, it's a lot easier and faster than compiling every time you make a change and then running the program from the prompt. The interactive mode is invoked by typing in ghci at your prompt. If you have defined some functions in a file called, say, myfunctions.hs, you load up those functions by typing in :l myfunctions and then you can play with them, provided myfunctions.hs is in the same folder from which ghci was invoked. If you change the .hs script, just run :l myfunctions again or do :r, which is equivalent because it reloads the current script. A common workflow when playing around in stuff is defining some functions in a .hs file, loading it up and messing around with them and then changing the .hs file, loading it up again and so on. This is what we'll be doing here.
Alright, let's get started! The first thing we're going to do is run ghc's interactive mode and call some function to get a very basic feel for Haskell. Open your terminal and type in ghci. You will be greeted with something like this.
Congratulations, you're in GHCI! The prompt here is Prelude> but because it can get longer when you load stuff into the session, we're going to use ghci>. If you want to have the same prompt, just type in :set prompt "ghci> ".
Here's some simple arithmetic.
This is pretty self-explanatory. We can also use several operators on one line and all the usual precedence rules are obeyed. We can use parentheses to make the precedence explicit or to change it.
A little pitfall to watch out for here is negating numbers. If we want to have a negative number, it's always best to surround it with parentheses. Doing 5 * -3 will make GHCI yell at you but doing 5 * (-3) will work just fine.
Boolean algebra is also pretty straightforward. && means a boolean and, || means a boolean or, not negates a True or a False.
Testing for equality is done like so:
What about doing 5 + "llama" or 5 == True? Well, if we try the first snippet, we get a big scary error message!
Yikes! What GHCI is telling us here is that "llama" is not a number and so it doesn't know how to add it to 5. + expects its left and right side to be numbers. If we tried to do True == 5, GHCI would tell us that the types don't match. Whereas + works only on things that are considered numbers, == works on any two things that can be compared. But the catch is that they both have to be the same type of thing. We'll take a closer look at types a bit later. Note: you can do 5 + 4.0 because 5 is sneaky and can act like an integer or a floating-point number. 4.0 can't act like an integer, so 5 is the one that has to adapt.
You may not have known it but we've been using functions now all along. For instance, * is a function that takes two numbers and multiplies them. As you've seen, we call it by sandwiching it between them. This is what we call an infix function. Most functions that aren't used with numbers are prefix functions. Let's take a look at them.
Functions are usually prefix so from now on we won't explicitly state that a function is of the prefix form, we'll just assume it. In most imperative languages functions are called by writing the function name and then writing its parameters in parentheses, usually separated by commas. In Haskell, functions are called by writing the function name, a space and then the parameters, separated by spaces. For a start, we'll try calling one of the most boring functions in Haskell.
The succ function takes anything that has a defined successor and returns that successor. As you can see, we just separate the function name from the parameter with a space. Calling a function with several parameters is also simple. The functions min and max take two things that can be put in an order (like numbers!). See for yourself:
Function application (calling a function by putting a space after it and then typing out the parameters) has the highest precedence of them all. What that means for us is that these two statements are equivalent.
However, if we wanted to get the successor of the product of numbers 9 and 10, we couldn't write succ 9 * 10 because that would get the successor of 9, which would then be multiplied by 10 (100). We'd have to write succ (9 * 10) to get 91.
If a function takes two parameters, we can also call it as an infix function by surrounding it with backticks. For instance, the div function takes two integers and does integral division between them. Doing div 92 10 results in a 9. But when we call it like that, there may be some confusion as to which number is doing the division and which one is being divided. So we can call it as an infix function by doing 92 `div` 10.
In imperative languages, that parentheses denote function application. For example, in C, you use parentheses to call functions like foo(), bar(1) or baz(3, "haha"). Like we said, spaces are used for function application in Haskell. So those functions in Haskell would be foo, bar 1 and baz 3 "haha". So if you see something like bar (bar 3), it doesn't mean that bar is called with bar and 3 as parameters. It means that we first call the function bar with 3 as the parameter to get some number and then we call bar again with that number. In C, that would be something like bar(bar(3)).
In the previous section we got a basic feel for calling functions. Now let's try making our own! In you favorite text editor, punch in this function that takes a number and multiplies it by two.
Functions are defined in a similar way that they are called. The function name is followed by parameters separated by spaces. But when defining functions, there's a = and after that we define what the function does. Save this as lab.hs. Now navigate to where it's saved and run ghci from there. Once inside GHCI, do :l lab. Now that our script is loaded, we can play with the function that we defined.
Because + works on integers as well as on floating-point numbers (anything that can be considered a number, really), our function also works on any number. Let's make a function that takes two numbers and multiplies each by two and then adds them together.
Simple. Testing it out produces pretty predictable results (remember to append this function to the lab.hs file, save it and then do :l lab inside GHCI).
As expected, you can call your own functions from other functions that you made. With that in mind, we could redefine doubleUs like this:
This is a very simple example of a common pattern you will see throughout Haskell: making basic functions that are more clearly correct and then combining them into more complex functions. This also helps avoid repetition.
Functions in Haskell don't have to be in any particular order, so it doesn't matter if you define doubleMe first and then doubleUs or if you do it the other way around.
Now we're going to make a function that multiplies a number by 2, but only if that number is smaller than or equal to 100 (because numbers bigger than 100 are big enough as it is!)
Right here we introduced Haskell's if statement. You're probably familiar with if statements from other languages. The difference between Haskell's if statement and if statements in imperative languages is that the else part is mandatory in Haskell. In imperative languages you can just skip a couple of steps if the condition isn't satisfied - but in Haskell, every expression and function must return something. Another thing about the if statement in Haskell is that it is an expression. An expression is basically a piece of code that returns a value. 5 is an expression because it returns 5, 4 + 8 is an expression, x + y is an expression because it returns the sum of x and y. Because the else is mandatory, an if statement will always return something and that's why it's an expression. If we wanted to add one to every number that's produced in our previous function, we could have written its body like this.
Had we omitted the parentheses, it would have added one only if x wasn't greater than 100. Note the ' at the end of the function name. That apostrophe doesn't have any special meaning in Haskell's syntax. It's a valid character to use in a function name. We usually use ' to either denote a strict version of a function (one that isn't lazy) or a slightly modified version of a function or a variable. Because ' is a valid character in functions, we can make a function like this.
There are two noteworthy things here. The first is that in the function name we didn't capitalize Conan's name. That's because functions can't begin with uppercase letters. We'll see why a bit later. The second thing is that this function doesn't take any parameters. When a function doesn't take any parameters, we usually say it's a definition (or a name). Because we can't change what names (and functions) mean once we've defined them, conanO'Brien and the string "It's a-me, Conan O'Brien!" can be used interchangeably.
Much like shopping lists in the real world, lists in Haskell are very useful. They can be used in a multitude of different ways to model and solve a whole bunch of problems. In this section we'll look at the basics of lists, strings (which are lists) and list comprehensions.
In Haskell, lists are a homogenous data structure. They store several elements of the same type. That means that we can have a list of integers or a list of characters but we can't have a list that has a few integers and then a few characters. And now, a list!
Note: We can use the let keyword to define a name right in GHCI. Doing let a = 1 inside GHCI is the equivalent of writing a = 1 in a script and then loading it.
As you can see, lists are denoted by square brackets and the values in the lists are separated by commas. If we tried a list like [1,2,'a',3,'b','c',4], Haskell would complain that characters (which are, by the way, denoted as a character between single quotes) are not numbers. Speaking of characters, strings are just lists of characters. "hello" is just syntactic sugar for ['h','e','l','l','o']. Because strings are lists, we can use list functions on them, which is really handy.
A common task is putting two lists together. This is done using the ++ operator.
Watch out when repeatedly using the ++ operator on long strings. When you put together two lists (even if you append a singleton list to a list, for instance: [1,2,3] ++ [4]), internally, Haskell has to walk through the whole list on the left side of ++. That's not a problem when dealing with lists that aren't too big. But putting something at the end of a list that's fifty million entries long is going to take a while. However, putting something at the beginning of a list using the : operator (also called the cons operator) is instantaneous.
Notice how : takes a number and a list of numbers or a character and a list of characters, whereas ++ takes two lists. Even if you're adding an element to the end of a list with ++, you have to surround it with square brackets so it becomes a list.
[1,2,3] is actually just syntactic sugar for 1:2:3:[]. [] is an empty list. If we prepend 3 to it, it becomes [3]. If we prepend 2 to that, it becomes [2,3], and so on.
Note: [], [[]] and[[],[],[]] are all different things. The first one is an empty list, the seconds one is a list that contains one empty list, the third one is a list that contains three empty lists.
If you want to get an element out of a list by index, use !!. The indices start at 0.
But if you try to get the sixth element from a list that only has four elements, you'll get an error, so be careful!
Lists can also contain lists. They can also contain lists that contain lists that contain lists …
The lists within a list can be of different lengths but they can't be of different types. Just like you can't have a list that has some characters and some numbers, you can't have a list that has some lists of characters and some lists of numbers.
Lists can be compared if the stuff they contain can be compared. When using <, <=, > and >= to compare lists, they are compared in lexicographical order. First the heads are compared. If they are equal then the second elements are compared, etc.
What else can you do with lists? Here are some basic functions that operate on lists.
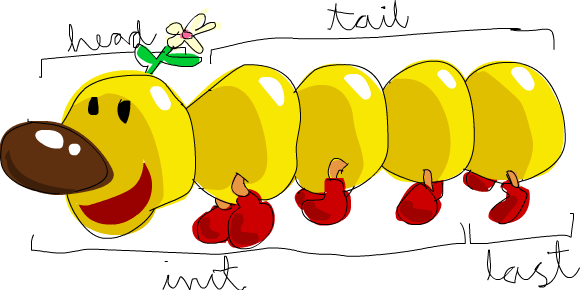
head takes a list and returns its head. The head of a list is basically its first element.
tail takes a list and returns its tail. In other words, it chops off a list's head.
last takes a list and returns its last element.
init takes a list and returns everything except its last element.
If we think of a list as a monster, here's what's what.
But what happens if we try to get the head of an empty list?
Oh my! It all blows up in our face! When using head, tail, last and init, be careful not to use them on empty lists.
length takes a list and returns its length
null checks if a list is empty. If it is, it returns True, otherwise it returns False. Use this function instead of xs == [] (if you have a list called xs)
reverse reverses a list.
take takes number and a list. It extracts that many elements from the beginning of the list.
See how if we try to take more elements than there are in the list, it just returns the list. If we try to take 0 elements, we get an empty list.
drop works in a similar way, only it drops the number of elements from the beginning of a list.
maximum takes a list of stuff that can be put in some kind of order and returns the biggest element.
minimum returns the smallest.
sum takes a list of numbers and returns their sum.
product takes a list of numbers and returns their product.
elem takes a thing and a list of things and tells us if that thing is an element of the list. It's usually called as an infix function because it's easier to read that way.
Those were a few basic functions that operate on lists.