Next I decided to try an experimental technique wherein an ensemble of SVMs would be
queried, and the max of their responses would be kept.
I trained a separate SVM on each image and saved the SVM each time it exceeded 5000 correct classifications, not
saving an additional SVM until a saved one incorrectly classified a pixel, re-converged, and attained 5000 correct
classifications again. In other words, only 'good' classifiers were saved and they were saved in a fashion that
should have kept redundancy to a minimum.
I then scatter-plotted the SVMs by normalizing the model vector and multiplying it by the bias. This plot sometimes
gave reasonable intuition as to which SVMs were redundant and which ones were good values.
I selected a subset of between 1 and 7 of the saved SVMs and took the max of their responses. It probably would have been
better to threshold and normalize this response to get a better reflection of true probability, as this is not really a
valid way to estimate probability. In general, it is difficult to successfully combine the output of multiple SVMs.
Note that this is not necessarily a good idea from a machine learning perspective. In fact,
it might be flat out bad, but it's worth a shot.
Performance:
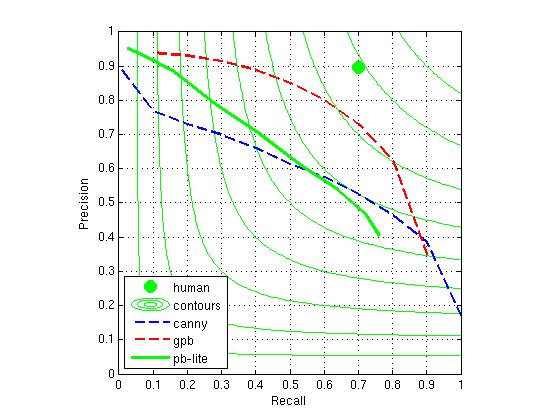
Note that this beats the Canny-baseline (unpictured) until around the point where it crosses the Canny curve,
at which point it also begins losing to the canny-baseline.