DIY 3D Scanner
- Emanuel Zgraggen (ez), May 18th, 2011

Introduction
The
Microsoft Kinect
features a RGB camera and a depth sensor. Both sensor have a resolution
of 640 x 480 pixels and run at 30 frames per second. The depth sensor provides 11-bit depth
values and has a practical ranging limit of 1.2 - 3.5 meters.
This project explores ways of using a Kinect to build a 3D scanner.
The Kinect is used to take snapshots (RGB and depth) of an object from
different angles. The resulting colored point clouds are stitched together to obtain
a full 360 degree point cloud of the scanned object.
The implemented software uses
Qt,
OpenNI and
OpenCV.
Approach
The basic setup of the 3D scanner requires to mount the Kinect at a fixed position. The object that needs to be scanned is put on a turntable. This setup makes all the transformations fairly simple, since all the distances and angles are known or can easily be calculated.



The whole scanning pipeline was split up into 3 basic steps, which are explained in detail in the following sections.
Noise reduction
One problem of the depth values provided by the Kinect is that they tend to be pretty noisy, specially at object boundaries. The following animation shows a sequence of depth frames over a period of a 2 - 3 seconds.

For our scanned point cloud we only want to take points that have "good" depth values, meaning that they should have small variance over time. The algorithm captures 30 frames (RGB and depth) for each snapshot angle. To obtain somewhat smoothed depth estimates, we average the depth values over those 30 frames. Points that have a high standard deviation are not considered for the final point cloud.






Background subtraction
Our 3D scanner should only take points into account that actually correspond to the object we want to scan. Points that are part of the background should not be considered. Before each scanning process a snapshot of the setup without the object is taken. The snapshot is again an average over 30 frames and is later used to separate the foreground object.

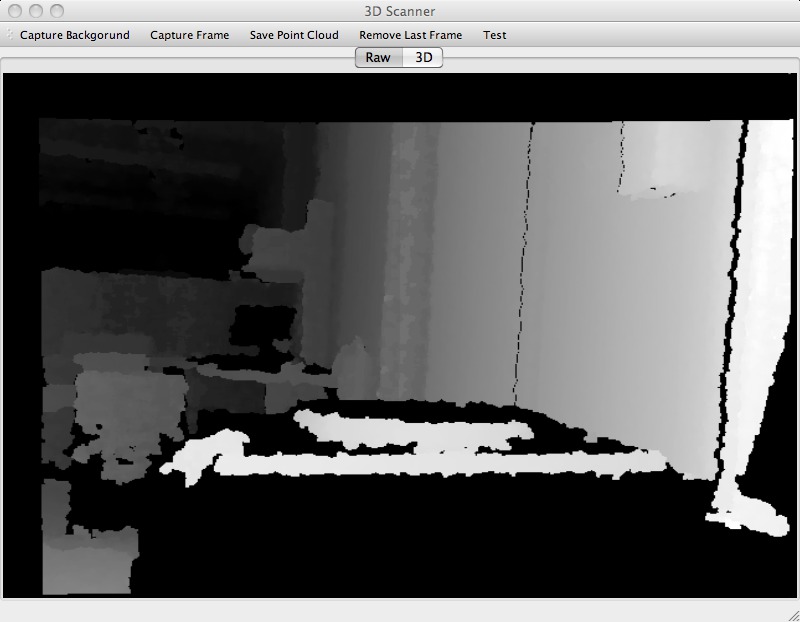
The software uses the captured background depth image and subtracts it from the depth image of an object snapshot. This produces an image where points in the foreground are highlighted (plus remaining noise in the background). The algorithm then combines the information from the standard deviation image with that foreground depth map to produce a mask of all the pixels that should be taken into account for the point cloud of the current snapshot. A pixel in the mask is set to white if it has a low standard deviation and has a value greater than zero in the foreground depth image. To get rid of any remaining noise, the mask gets eroded. That last step also helps to remove pixels that have no accurate color information. This is true for pixels at the object's boundary, since the tend to get blended with the background. To obtain a point cloud, each pixel that lies under the mask is used with its corresponding depth value, as well as its color information from the RGB image.



Alignment
One problem with the Kinect is that the two sensors (RGB and depth) are mounted with a small displacement. They don't "see" exactly the same things. In order to get a depth value for an RGB x and y pixel location and vice versa, the two sensors need to be calibrated and one of the sensor's images needs to be transformed into the other's viewpoint. OpenNI provides functions to do exactly that: transform the depth image to the RGB sensor's viewpoint. OpenNI also has methods to convert x and y pixel coordinates to real world millimeter values.
The implemented software needs the user to enter the angle of each snapshot that is taken. The user starts the scanning process with a snapshot of the object without rotation. He then turns the object some angle using the turntable, feeds the angle into the software and takes another snapshot. The algorithm then rotates the point cloud of the new snapshot according to that angle and adds it to the combined point cloud. In order to know around which axis to rotate, the algorithm needs a reference point, which in our case should be at the center of the turntable. The software has a calibration mode where this reference point can be specified.

Results
The algorithm has been tested by scanning multiple objects. Here are some images of the resulting point clouds (rendered in MeshLab).
















The 3D scanner software is able to export point clouds in ASCII ply format. The point clouds shown in the results section can be downloaded here (vase.ply, statue.ply, airmax.ply, cartman.ply). For viewing purposes I recommend MeshLab.
Discussion
The biggest drawback of the current approach is that there is no real stitching between the point clouds of two frames. The algorithm basically just overlays them. As a result there are a lot of points that represent the same spot on the object but have slightly different coordinates and color values due to noise or calibration errors. This makes the resulting point clouds not usable for standard mesh reconstruction algorithms. To improve that, some sort of registration between two point clouds is needed. One idea would be to use the Iterative Closest Point algorithm.

I tried to implement an algorithm to estimate the rotation angle between two frames. My approach, which is based on this paper, was to find correspondences between two RGB frames (only the foreground object) using SURF features and then use RANSAC to find the rotation matrix between the two frames. Each feature has not only a x and y position, but also the corresponding depth / z value from the depth map. I have not been able to get accurate and reliable rotation estimates in time. But I think it would be worth investigating that idea a bit further, since it could be extended to solve for general 3D transformations (not only rotation) and then a fixed Kinect position and a turntable would not be needed anymore.
