Hypertext Link Integrity
Department of Electronics and Computer Science Web: http://www.ecs.soton.ac.uk/
Southampton, SO17 1BJ, UK
Email: hcd@ecs.soton.ac.uk
Web: http://www.ecs.soton.ac.uk/~hcd
Abstract: Hypertext links are connections between documents or parts of documents. Generally the ends of links are represented by some kind of a reference to a document or part of a document. When documents are moved or changed these references may cease to resolve to the correct places. This paper reflects on the causes of this problem and reviews techniques that may be used to maintain link integrity.Categories and Subject Descriptors: H.5.4 [Information Interfaces and Presentation]: Hypertext/Hypermedia - Architectures
Additional Key Words and Phrases: broken links, dangling links, content reference problem, link integrity.
1 Introduction
When the object at one end of a link is not present, or is not the object that was intended by the link author, then the link is said to be broken. This paper surveys the field of link integrity and the methods by which we can ensure that links are not broken.Link integrity is an important topic. Most of the earlier hypertext system developers assumed that it was part of the task of the hypertext system to ensure that link integrity was maintained, and this assumption was embodied in the Dexter Model [Halasz 1994] However, with the advent of distributed hypertexts it became difficult for the system to maintain this integrity. Little effort has so far been made to ensure link integrity on the World Wide Web with the result that, as sites are reorganized, many links terminate in the infamous 404 error.
2 Terminology
Not all systems consist of the unidirectional embedded links as realized by HREF's in HTML. It is more useful to consider a link as the connection between two (or more) anchors. A link might be bi-directional (followed in either direction). An anchor consists of the document identifier (in the simple case this will be a filename or URL) and the content reference which is some kind of a pointer to the "hotspot" or "button" or destination of the link. Sometimes anchors are held in separate link services or hyperbases as shown in figure 1b, and sometimes they are embedded within document content, as shown in figure1a
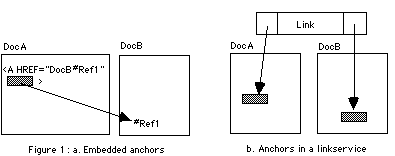
There are pro's and con's to be considered for different methods of link representation [Davis 1995] and different representations may require different approaches to link integrity. When a link points into a document which cannot be found then the link is said to dangle. This problem will occur whenever a document is deleted or moved without updating connected links. When an link refers to the wrong place within the document then we have a content reference problem [Davis 1998]. This problem may occur if a document is changed without updating connected links.
One can detect and correct broken links; one can prevent links from becoming broken in the first place; or one can ignore them. Ignoring them may seem a bad idea, but it is the approach that is generally taken by the World Wide Web.
The remainder of this paper considers existing approaches to maintaining link integrity.
3 Dangling Links
3.1 Detection and Correction
There are a number of ways that we can detect broken links. In a linkservice the links are all held in a database, so it is a simple matter to iterate through all the links checking for references to documents which no longer exist. It is rather more difficult if links are embedded in the content, and in this case a some kind of a "spider" [Fielding 1994] or "robot" must be used, which traverses the hypertext structure by retrieving a document, and recursively retrieving all documents that are referenced. Once a broken link is detected usually there is little that can be done other than to remove the link from the system, but in the case of a re-organized intranet it is sometimes possible to locate the new position of this document and repair the link.
Of course, if users did not move or delete documents without updating the system, links would not dangle in the first place. If a user is reorganizing a filestore, at this time they could update all links with anchors pointing into a document that is being moved. Or at least they could update the links, if they had write access to the links in order to update them.
The problem on the World Wide Web is that we do not know what links point to a document, and even if we did, we probably could not change them. In a linkservice tools will be provided for updating the database when a document is moved.
If they cannot update links, the only alternative that responsible users have, when reorganizing a site, is to leave some pointer to the new position of the document [Ingham 1996]. This redirect system is regularly used on the Web but has limitations in that legacy infrastructure may need to be maintained in order to do the redirections.
3.2 Prevention
If every document in the system is known by a globally persistent and unique name, as might be allocated by a document management system or a URN server [W3C 1998a] such as OCLC's PURL server on the Web, then links may be made to refer to this unique name, rather than to some absolute document. The URN server is then responsible for resolving this name to an absolute address. Now when users move files, they can inform the name server of this change. So long as this is done, the change in real position will not affect the links. This approach is also taken by many linkservices and hyperbases.
Another approach sometimes taken on commercial sites is to use web servers which prevent the user from bookmarking or linking to any document other than the home page. This ensures that as the site is reorganized users' links will not dangle, by the irritating practice of preventing links in the first place.
4 Content Reference Problems
The content reference problem occurs when a document is edited, but the references into the document are not updated. This problem does not happen in WWW html links, as the anchors are embedded in the text and are therefore moved as the text is edited. However, most modern hypertext systems do use some sort of pointer to reference link anchor positions in documents and as the Web community starts to adopt the new XPointer standard [W3C 1998b] the same problem will emerge there.
4.1 Detection and Correction
It is always possible for the linkservice to detect when such a problem may have occurred. This is achieved by storing the datestamp of the files inside the link. We would need to be suspicious of pointers into any file that had been updated since the link was made.
We can further improve detection if we also store some of the content at (and possibly around) the anchor, at the time that the anchor is created. Now, when a document is opened the viewer application may examine the data pointed to by each anchor, and determine whether this data is what was expected. Furthermore, we can use this content data to apply just-in-time link repairs. If the data referenced by a link was incorrect one could apply some search algorithm which would attempt to locate the data that was expected and to re-write the correct reference back to the link service. The amount of searching can be reduced if, at the time that the anchor is stored, we not only store the count from the front of the file, but also the count from the end of the file. Small file edits may only change one of these references, so the other will still work. This approach is suggested by HyTime [DeRose 1994].
Just-in-time link repair has the advantage that it will work even after some application that is not link-service aware has edited the document. However it requires the hypertext viewer application to perform a big task, which requires significant coding effort.
Link repair may be much simpler if versions of documents are stored. If this is the case it will be possible to use an algorithm such as diffb to identify where any string of bytes in an old version have been located in a new version. Another method of using versions was suggested by Xanadu [Nelson 1981] which created documents by streaming together versions of component parts.
4.2 Prevention
The simplest solution to preventing the content reference problem is to prohibit users from updating documents once they have pointers into them; the publishing solution.
Of course we will also prevent this problem if we embed link anchors, provided that the user does not mindlessly edit and corrupt the actual link anchor. One of the major disadvantages of this solution is that it will not then be possible to link to read-only documents.
A better solution might be to produce link-service aware editors, which may collect the anchors from the linkservice, and embed them into the content for the duration of the edit. This approach was taken by Hyper-G [Kappe 1995], but has the disadvantage that it will be necessary to provide an editor for every format that we wish to enable for hypertext.
Much of the discussion so far has assumed that content references have been stored as some form of a count into the data. Other methods of representing references might be more resilient to editing. The Hytime and XPointer standards allow you to point to elements of the structure of a document.
A final method to consider is to use declarative specifications of the position(s) of link anchors [W3C 1998a] that will not be broken when the document is edited. For example, Microcosm's local link [Davis 1992] specifies that a link anchor will be placed on any occurrence of the defined text string within a given document.
5 Conclusions
Any system which de-couples structural information from content provides the potential for inconsistencies to occur. There are distinct philosophies for dealing with the resulting problems:
- Don't bother: the system may warn the user of potentially broken links.
- Avoid the problem: Links are expressed declaratively rather than by using counting methods.
- Loosely coupled: the system does not maintain the integrity of the links, but provides tools which enable the responsible user to do so.
- Automated link repairs: the system provides tools that attempt to automate the repair of the links on a just-in-time basis.
- Tightly coupled: all links, nodes, node content, and anchors are owned by the hyperbase. All changes to the these objects pass through the hyperbase which ensures that referential integrity is maintained at all times.
References
[Davis 1992] Hugh C. Davis, Wendy Hall, Ian Heath, Gary J. Hill, and Rob J. Wilkins. "Towards an Integrated Information Environment with Open Hypermedia Systems" in Proceedings of the ACM Conference on Hypertext (ECHT '92), Milano, Italy, 181-190, [Online: http://acm.org/pubs/citations/proceedings/hypertext/168466/p181-davis/], December 1992.[Davis 1995] Hugh C. Davis. "To Embed or Not to Embed..." in Communications of the ACM (CACM), 38(8), 108-109, August 1995.
[Davis 1998] Hugh C. Davis. "Referential Integrity of Links in Open Hypermedia Systems" in Proceedings of ACM Hypertext '98, Pittsburgh, PA, 207-216, June 1998.
[DeRose 1994] Steven J. DeRose and David G. Durand. Making Hypermedia Work: A User's Guide to HyTime. Kluwer Academic Press. 1994 .
[Fielding 1994] Roy Fielding. "Maintaining Distributed Hypertext Infostructures: Welcome to MOMspider's Web" in Proceedings of the First International World-Wide Web Conference, Geneva Switzerland, May 1994.
[Halasz 1994] Frank G. Halasz and Mayer D. Schwartz. "The Dexter Hypertext Reference Model" in Communications of the ACM (CACM), 37(2), 30-39, February 1994.
[Ingham 1996] Dave Ingham, Steve Caughey, and Mark Little. "Fixing the 'Broken-Link' Problem: The W3Objects Approach" in Computer Networks and ISDN Systems 28(7-11), 1255-1268, Proceedings of the Fifth International World-Wide Web Conference , Paris, France, [Online: http://w3objects.ncl.ac.uk/pubs/bootw/], May 1996.
[Kappe 1995] Frank Kappe. "A Scalable Architecture for Maintaining Referential Integrity in Distributed Information Systems" in Journal of Universal Computer Science (JUCS), 1(2), 1995.
[Nelson 1981] Theodor Helm Nelson. Literary Machines. Published by the author. 1981.
[W3C 1998a] W3C. World Wide Web Consortium. Names and Addresses, URI's, URL's, URN's, URC's, [Online: http://www.w3.org/pub/WWW/Addressing], 1998.
[W3C 1998b] W3C. World Wide Web Consortium. XML Pointer Language (XPointer). World Wide Web Consortium Working Draft 03-March-1998, [Online: http://www.w3.org/TR/1998/WD-xptr-19980303], 1998.