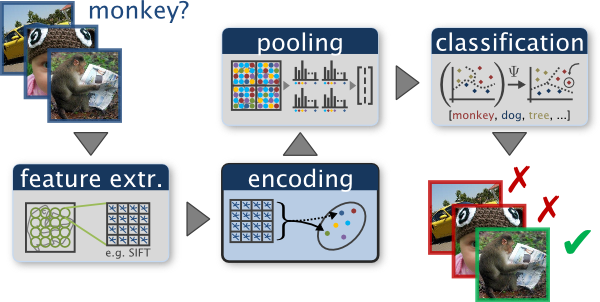
An example of a typical bag of words classification pipeline. Figure by Chatfield et al.
Project 3: Scene recognition with bag of words
CS 143: Introduction to Computer Vision
Brief
- This handout: /course/cs143/asgn/proj3/handout/
- Stencil code: /course/cs143/asgn/proj3/stencil/
- Data: /course/cs143/data/proj3/
- Handin: cs143_handin proj3
- Required files: README, code/, html/, html/index.html
- Due date: October 24th, 11:59pm
Overview
Bag of words models are a popular technique for image classification inspired by models used in natural language processing. The model ignores or downplays word arrangement (spatial information in the image) and classifies based only on a histogram of the frequency of visual words. Visual words are identified by clustering a large corpus of local features. See Szeliski chapter 14.4.1 for more details on category recognition with quantized features. In addition, 14.3.2 discusses vocabulary creation and 14.1 covers classification techniques.
For this project you will be implementing a basic bag of words model with many opportunities for extra credit. You will classify scenes into one of 15 categories by training and testing on the 15 scene database (introduced in Lazebnik et al. 2006, although built on top of previously published datasets). Lazebnik et al. 2006 is a great paper to read, although we will be implementing the baseline method the paper discusses (equivalent to the zero level pyramid) and not the more sophisticated spatial pyramid (which is extra credit). For a more recent review of feature encoding methods for bag of words models see Chatfield et al, 2011.

Example scenes from of each category in the 15 scene dataset. Figure from Lazebnik et al. 2006.
The basic flow of this project is as follows:
- Collect a lot of features.
- Use k-means to cluster those features into a visual vocabulary.
- For each of the training images build a histogram of the word frequency (assigning each feature found in the training image to the nearest word in the vocabulary).
- Train classifiers based on the word frequency histograms of training data.
- Build a histogram for each test image and determine its most likely category using the trained classifiers.
Details and Starter Code
The top level script is proj3.m. It breaks the project pipeline in to 5 steps:
- Collect many local features and cluster them in to a vocabulary of visual words.
- Represent each training image as a distribution of visual words. In the simplest case, simply assign each observed feature to the nearest visual word in your vocabulary. In this case, your bag of words representation will be a histogram counting visual word occurrences.
- Train 1-vs-all classifiers for each scene category based on observed bags of words in training data.
- Classify each test image by converting to bag of words representation and evaluating all 15 classifiers on the query.
- Build a confusion matrix and measure accuracy
The first two steps will require you to decide on a local feature representation for each scene. We suggest starting with the VLFeat library's vl_dsift function. We suggest using vl_kmeans to build the vocabulary. You can also implement other local features or clustering methods.
A baseline version of the final three steps is written for you. We have included an SVM implementation, primal_svm.m. This code is fast, portable, and accepts arbitrary kernel matrices. The stencil code is configured to train linear SVMs, although you can use non-linear kernels for improved performance and extra credit.
All the images are under the data directory. data/training and data/test both have folders for each scene category; training has exactly 100 scenes per directory, and test has a variable number. The stencil code is configured to train and test on the same number of images per category.
Whichever local feature representation you decide to use, it is not necessary to use the entire training set to build a visual word vocabulary. Instead you can randomly sample tens or hundreds of thousands of local descriptors to cluster. Make sure to sample from all the training images, though. We recommend starting with a vocabulary of about 200 words.
You should normalize your bag of words histograms, so that image size does not influence histogram counts.
Useful MATLAB functions: histc
Write up
For this project, and all other projects, you must do a project report in HTML. In the report you will describe your algorithm and any decisions you made to write your algorithm a particular way. Then you will show and discuss the results of your algorithm. Discuss any extra credit you did, and clearly show what contribution it had on the results (e.g. performance with and without each extra credit component).
It would be interesting (although not required) to see where the classifier is making mistakes in the spirit of the SUN database results page (Warning: large web page).
For this project you should also include a confusion matrix for your classifier. (You can include a graphic or MATLAB's text output in a <pre> tag.)
Extra Credit
For all extra credit, be sure to analyze on your web page cases whether your extra credit has improved classification accuracy. Each item is "up to" some amount of points because trivial implementations may not be worthy of full extra credit.Some ideas:
- up to 5 pts: Use cross-validation to measure performance rather than the fixed test / train split provided by the starter code. Randomly pick 100 training and 100 testing images for each iteration and report average performance and standard deviations.
- up to 5 pts: Add a validation set to your training process to tune learning parameters.
- up to 5 pts: Experiment with many different vocabulary sizes and report performance. E.g. 10, 20, 50, 100, 200, 400, 1000, 10000.
- up to 5 pts: Experiment with features at multiple scales. E.g. sampling features from different levels of a Gaussian pyramid.
- up to 5 pts: Add spatial information to your features by creating a (possibly overlapping) grid of visual word histograms over the image. This is the "Single-level" regime described by Lazebnik et al 2006.
- up to 15 pts: Add spatial information to your features by implementing the spatial pyramid and pyramid match kernel described in Lazebnik et al 2006.
- up to 10 pts: Train the SVM with more sophisticated kernels such as Gaussian/RBF, L1, or chi-sqr.
- up to 10 pts: Add additional, complementary features (e.g. gist descriptors, self-similarity descriptors, or PHOW features.) and have the classifier consider them all.
- up to 10 pts: Report performance on the 397-category SUN database. This involves more than 100x as many training and testing examples as the base project. Each 1-vs-all classifier may take several minutes to train.
- up to 5 pts: Use "soft assignment" to assign visual words to histogram bins. Each visual word will cast a distance-weighted vote to multiple bins. This is called "kernel codebook encoding" by Chatfield et al..
- up to 10 pts: Use one of the more sophisticated feature encoding schemes analyzed in the comparative study of Chatfield et al. (Fisher, Super Vector, or LLC)
Graduate Credit
To get graduate credit on this project you must do 10 points worth of extra credit. Those 10 points will not be added to your grade, but additional extra credit will be.
Web-Publishing Results
All the results for each project will be put on the course website so that the students can see each other's results. In class we will highlight the best projects as determined by the professor and TAs. If you do not want your results published to the web, you can choose to opt out. If you want to opt out, email cs143tas[at]cs.brown.edu saying so.
Handing in
This is very important as you will lose points if you do not follow instructions. Every time after the first that you do not follow instructions, you will lose 5 points. The folder you hand in must contain the following:
- README - text file containing anything about the project that you want to tell the TAs
- code/ - directory containing all your code for this assignment
- html/ - directory containing all your html report for this assignment, including images (any images not under this directory won't be published)
- html/index.html - home page for your results
Then run: cs143_handin proj3
If it is not in your path, you can run it directly: /course/cs143/bin/cs143_handin proj3
Rubric
- +40 pts: Build a vocabulary from a random set of features. (
build_vocabulary.m) - +20 pts: Build histograms of visual words for training and testing images. (
make_hist.m) - +20 pts: Train 1-vs-all SVMs on your bag of words model. (
proj3.mwhich callsprimal_svm.m) - +20 pts: Writeup with design decisions and evaluation.
- +15 pts: Extra credit (up to fifteen points)
- -5*n pts: Lose 5 points for every time (after the first) you do not follow the instructions for the hand in format
Final Advice
- Extracting features, clustering to build a universal dictionary, and building histograms from features can be slow. A good implementation can run the entire pipeline in less than 10 minutes, but this may be at the expense of accuracy (e.g. too small a vocabulary of visual words or too sparse a sampling rate). Save intermediate results if you are trying to fine tune one part of the pipeline.
Credits
Project description and code by Sam Birch and James Hays. Figures in this handout from Chatfield et al. and Lana Lazebnik.